
Данные, их типы, структуры и обработка
Любая актуализация информации опирается на какие-то данные, любые данные могут быть каким-то образом актуализированы.
Данные – это некоторые сообщения, слова в некотором заданном алфавите.
Пример. Число 123 – данное, представляющее собой слово в алфавите из десяти натуральных цифр; число 12,34 – данное, представляющее собой слово в алфавите из десяти натуральных цифр и десятичной запятой; текст математика и информатика – нужные дисциплины, – данное в алфавите из символов русского языка и знаков препинания, включая пробел.
Текущее (то есть рассматриваемое в данный момент времени) состояние данных называют текущим значением данных или просто значением.
До разработки алгоритма (программы) необходимо выбрать оптимальную для реализации задачи структуру данных. Неудачный выбор данных и их описания может не только усложнить решаемую задачу и сделать ее плохо понимаемой, но и привести к неверным результатам. На структуру данных влияет и выбранный метод решения.
Пример. При решении системы линейных алгебраических уравнений можно воспользоваться методом Крамера (с помощью определителей) или методом Гаусса (с помощью последовательных исключений неизвестных). Метод Крамера потребует при реализации примерно в 3 раза больше операций, чем метод Гаусса, и поэтому им никогда не пользуются при расчетах на ЭВМ.
Тип данных характеризует область определения значений данных.
Задаются типы данных простым перечислением значений типа, например как в простых типах данных, либо объединением (структурированием) ранее определенных каких-то типов – структурированные типы данных .
Пример. Зададим простые типы данных специальность, студент, вуз следующим перечислением:
специальность = (филолог, историк, математик, медик);
студент = (Петров, Николаев, Семенов, Иванова, Петрова);
вуз = (МГУ, РГУ, КБГУ).
Значением типа студент может быть Петров.
Пример. Опишем структурированный тип данных специальность_студента:
специальность_студента=(специальность, студент).
Значением типа специальность_студента может быть пара (историк, Семенов).
Для обозначения текущих значений данных используются константы – числовые, текстовые, логические.
Часто (в зависимости от задачи) рассматривают данные, которые имеют не только линейную (как приведенные выше), но и иерархическую структуру.
Пример. Структуру вуз можно задать иерархической структурой, состоящей, например, из следующих уровней: Ректорат, Деканаты и подразделения, Кафедры, Отделы, Преподаватели и сотрудники.
В алгоритмических языках есть стандартные типы, например, целые, вещественные, символьные, тестовые и логические типы. Они в этих языках не уточняются (не определяются, описываются явно) и имеют соответствующие описания с помощью служебных слов.
Пример. В школьном алгоритмическом языке (ШАЯ), например, целые, вещественные, символьные, текстовые (литерные, стринговые) и логические типы данных описываются ключевыми словами цел, вещ, сим, лит, лог. В языке Паскаль – аналогичными ключевыми словами integer, real, char, string, boolean.
Каждый тип данных допускает использование определенных операций со значениями типа (с типом).
Пример. Для целого типа данных назовем операции :=, +, –, *, = (сравнение на равенство),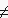 , ,
, ,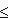 ,
,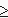 .. Для вещественного типа данных еще и операция / (деление). Для символьного типа данных – только :=, =, , , , . Например, сравнение а
.. Для вещественного типа данных еще и операция / (деление). Для символьного типа данных – только :=, =, , , , . Например, сравнение а
Для описания переменных, значениями которых могут быть лишь символы, тексты, используются соответствующие ключевые слова: на ШАЯ – сим, лит, на Паскале – char, string.
Текстовые (символьные) константы обычно заключают в апострофы.
Наиболее часто используемая структура данных – массив.
Одномерный массив (вектор, ряд, линейная таблица) – это совокупность значений некоторого простого типа (целого, вещественного, символьного, текстового или логического типа), перенумерованных в каком-то порядке и имеющих общее имя. Для выделения конкретного элемента массива необходимо указать его порядковый номер в этом ряду.
Пример. Последовательность чисел 89, –65, 9, 0, –1.7 может образовывать одномерный вещественный массив размерности 5, например, с именем x вида: x[1] = 89, x[2] = –65, x[3] = 9, x[4] = 0, x[5] = –1.7.
Значение порядкового номера элемента массива называется индексом элемента.
Пример. Можно ссылаться на элемент х[4], элемент х[i], элемент x[4+j] массива х. При текущих значениях переменных i = 2 и j = 1 эти индексы определяют, соответственно, 4-й, 2-й и 5-й элементы массива.
Для обозначения (нового типа объектов) массивов в алгоритмических языках обычно вводится специальное служебное слово.
Пример. В ШАЯ – это слово таб, после которого приводится имя массива и в квадратных скобках его размерность, например, для одномерного массива – в виде [m:n], где m – номер первого элемента массива (часто 1), n – номер последнего элемента (шаг перебора элементов равен 1). На Паскале имеется соответствующее слово array. Вышеуказанная последовательность из пяти чисел описывается на ШАЯ в виде: вещ таб x[1:7], а на Паскале (в рамках рассматриваемого нами его ядра) необходимо указывать предельную величину размерности:
x: array [1..100] of real;.
Двумерный массив (матрица, прямоугольная таблица) – совокупность одномерных векторов, рассматриваемых либо горизонтально (векторов-строк), либо вертикально (векторов-столбцов) и имеющих одинаковую размерность, одинаковый тип и общее имя.
Матрицы, как и векторы, должны быть в алгоритме описаны служебным словом (например, таб или array), но в отличие от вектора, матрица имеет описание двух индексов, разделяемых запятыми: первый определяет начальное и конечное значение номеров строк, а второй – столбцов.
Пример. Если матрица x описана в виде
x: array [1..5, 1..3] of real; ,
то определяется таблицу из 5 строк (от 1-й до 5-й строки) и 3 столбцов (от 1-го до 3-го столбца) вида:
| (столбец 1) | (столбец 2) | (столбец 3) | |
| x11 | x12 | х13 | (строка 1) |
| x21 | x22 | х23 | (строка 2) |
| х31 | х32 | х33 | (строка 3) |
| х41 | x42 | х43 | (строка 4) |
| х51 | x52 | х53 | (строка 5) |
Для актуализации элемента двумерного массива нужны два его индекса – номер строки и номер столбца, на пересечении которых стоит этот элемент.
Пример. Элемент х[3,2] – элемент на пересечении 3-й строки и 2-го столбца массива х.
Статьи к прочтению:
#8 Структуры C++
Похожие статьи:
-
Иерархические структуры данных
Основные структуры данных Работа с большими наборами данных автоматизируется проще, когда данные упорядочены, то есть образуют заданную структуру….
-
Структура простейшей базы данных. свойства полей базы данных. безопасность баз данных
РАБОТА С БАЗАМИ ДАННЫХ Содержание лекции- 1.Основные понятия баз данных. Базы данных и системы управления базами данных. 2.Структура простейшей базы…