
Компьютерная информационная система в структуре организации
2.1 Схема внедрения компьютерной ИС в организацию
Повышение качества управления организацией связанно с ускорением обработки информации за счет автоматизации процессов принятия решений.
Компьютерные автоматизированные информационные системы разрабатываются и внедряются в структуру организации. На рисунке 3 приведена схема управления организацией с использованием ИС.
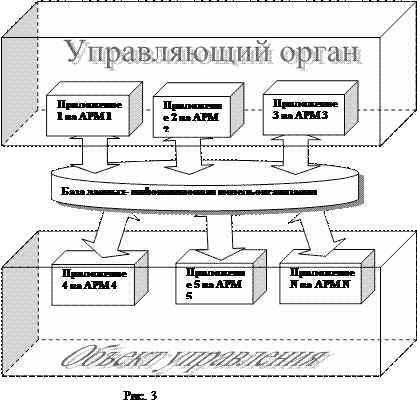

Система управления, состоящая из управляющего органа и объекта управления, объединяется с информационной системой. ИС состоит из базы данных и приложений, входящих в состав автоматизированных рабочих мест (см. рис.2.). Приложения – это программы, решающие информационные задачи пользователей. Они используют исходные данные, хранящиеся в базе данных. Результаты решения информационных задач также размещаются в БД. Обычно под информационными понимают следующие типы задач: — ввод, вывод и модификация информации, -подготовка и вывод на печать документов, -подготовка и отправка электронных сообщений, обработка информации с применением математических или логических формул, статистическая обработка данных и т.п.
Автоматизированные рабочие места включают компьютерную технику и приложения, необходимые для работы конкретных специалистов. Например, менеджеров, экономистов, техников, операторов и т.д. Каждый специалист решает свой круг информационных задач, поэтому приложение на его рабочем месте должно «уметь» решать эти задачи.
В современных операционных системах обработка информации выполняется при помощи элементов графического интерфейса — окон. В терминологии современных технологий разработки ИС окна называются формами. Специальные формы, используемые для подготовки бумажных документов, бланков получили название – отчеты.
Внешне приложения состоят из набора форм и отчетов. Обычно форму или отчет связывают с решением конкретной информационной задачи. Например, ввод сведений о клиентах туристической фирмы.
База данных ИС должна содержать все необходимые исходные данные для решения всех возможных пользовательских информационных задач. Информационные задачи, решаемые организацией, связаны с её бизнес – процессами (хозяйственными операциями). Поэтому в БД отражаются все состояния и процессы, происходящие в организации. БД – информационная модель деятельности организации.
2.2. Проектирование ИС
Создание ИС, реализующей ИТ управления, состоит из разработки базы данных и приложений, обеспечивающих функциональность рабочих мест.
Существует много подходов к проектированию БД. Среди них выделяются подходы, ориентированные на структуру предметной области и подходы, ориентированные на действия (динамику), выполняемые в предметной области.
Первая группа методов известна давно и сводится к четырем следующим этапам:
- Системный анализ предметной области;
- Построение информационно- логической модели предметной области;
- Построение даталогической модели предметной области;
- Построение таблиц базы данных.
Системный анализ дает возможность описать объекты, действующие в предметной области, и их информационные свойства. Анализу подвергаются живые объекты и неживые. Существенный вклад дает анализ документов организации. Как правило, объекты предметной области, задействованные в хозяйственных операциях, отражаются своими информационными свойствами в документах. Например, в документе Путевой лист объект Водитель отражается свойствами Фамилия, стаж, категория прав и т.п. А объект Бензин отражается свойствами Марка, количество литров. В то же время сам Путевой лист является объектом и у него есть атрибуты: номер, дата, подпись ответственного лица и т.д.
Во время анализа выявляются связи между свойствами объектов или/и объектами, а также ограничения, накладываемые на количественные характеристики объектов.
Результаты системного анализа оформляются документально. В простейшем случае это может быть таблица вида:
| № п\п | Объекты | Свойства | Связи | Ограничения |
| Преподаватель | Табельный номерФамилияИмяОтчествоКафедраПредметСтаж | студент | ||
| Студент | Номер зачетной книжкиФамилияИмяОтчествоГруппаСпециализация | преподаватель | ||
| … | … | … | … | |
| … | … | … | … |
Информационно- логическая модель (Инфологическая) представляет собой графическое описание семантики предметной области.
Основными элементами в модели являются Сущность и Связь.
Сущности соответствуют объектам предметной области, связи отображают логику их информационного взаимодействия.
Выше приведенная таблица может быть отражена в Инфологической модели следующим образом.
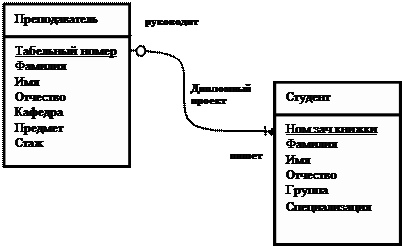
Сущности показаны прямоугольниками, а связи в виде линий с маркерами. Отдельные атрибуты сущностей выделяются в качестве первичных. Они обладают свойством уникальности. Например, табельный номер сотрудника и номер зачетной книжки студента не повторяется.
Связи отражают семантику предметной области. Они имеют имя, например, дипломное проектирование. Сущность в конкретной связи исполняет роль. Например, Преподаватель руководит, а студент пишет дипломный проект. Связи, могут отображать каким, образом взаимодействуют экземпляры одной сущности с экземплярами другой.
Так один преподаватель руководит несколькими студентами.
Типы связей: один к одному, один ко многим, многие ко многим.
Связи могут быть обязательными или необязательными.
Все студенты обязаны написать диплом, но не все преподаватели обязаны руководить проектированием.
Множественность и обязательность могут отражаться на связях различными маркерами. Например, кружками, ромбами, линиями и т. п.
Даталогическая модель определяет внутреннее представление данных с учетом особенностей конкретной СУБД.
Исходными данными для построения даталогической модели является информационно- логическая модель. Сущности заменяются отношениями. Отношение изображается в виде Т – образной таблицы. Сверху имя отношения, слева имена полей, справа типы данных в полях. Для фрагмента ИЛМ преподаватель- студент, Даталогическая модель выглядит так:

Отношения ДЛМ представляют собой описания таблиц базы данных. При этом связи между таблицами реализуются при помощи первичных и вторичных ключей. ТабНомер в отношении Преподаватель является первичным. Он однозначно идентифицирует любую запись в таблице. Данные в этом поле не повторяются. Одноименное поле в таблице студент является вторичным ключом. В нем допускается повторение данных. Это поле добавлено в отношение Студент только для организации связи между таблицами.
Используя ДЛМ легко построить таблицы базы данных в конкретной СУБД.
Для небольших БД допускаются упрощение процедур их проектирования. Ниже приводится пример разработки БД для обеспечения деятельности двух сотрудников.
3. Разработка баз данных для информационных систем
3.1. Получение внутреннего нормализованного представления данных с использованием реляционной модели
В обычном смысле БД представляет собой файл или множество файлов, имеющих определенную организацию. Однако при работе с обычными системами файловой обработки возникает ряд проблем, связанных, в частности, с избыточностью и зависимостью хранящихся в них данных. При проектировании БД эти проблемы решаются.
Пользователь должен принимать участие в процессе проектирования БД, так как только он может определить, какие данные необходимы для работы, указать связи, существующие между этими данными и обратить внимание на тонкости их обработки.
Информационные задачи отдельного пользователя обычно затрагивают лишь часть данных, хранящихся в информационной системе, и описание этих потребностей может не совпадать с описаниями потребностей других пользователей. Представление о том, какая именно информация необходима для работы организации зависит от функциональных задач, выполняемых специалистами (специалист отдела кадров и сотрудники бухгалтерии, руководитель подразделения и т.д.). Эти потребности описываются на внешнем уровне представления данных (представления А, В, и С, см. рис).
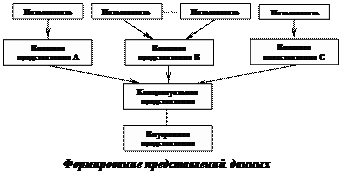
Внешних описаний данных, хранящихся в БД, следовательно, может быть множество. Их необходимо свести в единое концептуальное представление, описывающее данные на уровне всей информационной системы в целом. Представление этих данных на внутреннем уровне определяется способом их хранения во внешней памяти.
Рассмотрим пример БД информационной системы фирмы, занимающейся поставками товаров в магазины города, причем будем учитывать только информационные потребности двух сотрудников фирмы (в упрощенной форме – иначе пример был бы слишком громоздким).
Первый сотрудник, занимающийся связями с клиентами, для выполнения своих обязанностей нуждаются в следующей информации:
| Название магазина | Владелец | Телефон | Адрес | ||||||||||
| Фамилия | Имя | Отчество | Дата рождения | Адрес | Паспорт | Улица | Дом | Офис | |||||
| Улица | Дом | Квартира | Серия | Номер | |||||||||
Для второго сотрудника, который работает с платежными формами, необходима другая информация о клиентах:
| Название магазина | ИНН | Телефон | Адрес | Банк | Номер счета | Код по ОКОНХ | Код по ОКПО | ||
| Улица | Дом | Офис | |||||||
Данные, используемые отдельными специалистами, находятся в единой информационной системе предприятия, в общей для них базе данных. Поэтому внешние представления отдельных пользователей должны быть интегрированы в концептуальном представлении, цель описания данных на концептуальном уровне – создание такого формального представления о данных, чтобы любое внешнее представление являлось его подмножеством. В процессе интеграции внешних представлений устраняются двусмысленности и противоречия в информационных потребностях отдельных пользователей. Концептуальное описание, представляющее всю БД, должно быть единственным.
В рассматриваемом примере концептуальное представление должно включать всю информацию, необходимую двум сотрудникам. Противоречия могут возникнуть вследствие того, что сотрудники, которые используют общую информацию, могут представлять ее себе по-разному (например: номер телефона может быть записан в разных форматах). Все эти противоречия должны быть ликвидированы, данные, и форма их представления должны быть согласованы.
Тогда концептуальное описание определяется следующей информацией:
| Название магазина | ИНН | Телефон | Адрес | Владелец | Банк | Номер счета | Код по ОКОНХ | Код по ОКПО | ||||||||||
| Улица | Дом | Офис | Фамилия | Имя | Отчество | Дата рождения | Адрес | Паспорт | ||||||||||
| Улица | Дом | Квартира | Серия | Номер | ||||||||||||||
Данные, описанные концептуальной схемой, должны быть записаны во внешней памяти, на ВЗУ, предназначенных для хранения информации, находящейся в БД. Внутреннее описание данных характеризует способ хранения данных во внешней памяти.
Правила описания данных определяются выбранной моделью данных (в данном случае рассматривается только реляционная модель – самая распространенная на настоящее время).
Если взять описание данных о клиентах фирмы, занимающейся поставками товаров в магазины города, из приведенного выше примера, представленное следующим образом:
 Название магазина Название магазина | ИНН | Телефон |  Адрес Адрес |  Владелец Владелец | Банк | Номер счета | Код по ОКОНХ | Код по ОКПО |
| Улица | Дом | Офис | Фамилия | Имя |  Отчество Отчество | Дата рождения |  Адрес Адрес |  Паспорт Паспорт |
| Улица | Дом | Квартира | |||
| Серия | Номер |
то данные, описанные этой таблицей не могут в таком виде быть представлены в реляционной БД, так как не все значения являются атомарными (компоненты строк «Владелец» и «Адрес» состоят из нескольких значений, т.е. значения этих атрибутов заменяются другими отношениями, расшифровываются ими; в отношении, описывающем владельца, поля «Адрес» и «Паспорт» также не являются атомарными, следовательно строится иерархия отношений).
При проектировании БД могут быть приняты различные решения, но существуют базовые требования, которые должны учитываться в процессе работы: множество отношений должно обеспечивать минимальную избыточность представления информации; манипулирование данными, корректировка отношений не должна приводить к нарушению целостности данных, двусмысленности и потере информации; перестройка набора отношений при добавлении в БД новых атрибутов должна быть минимальной.
Описание реальных объектов и взаимосвязей между ними во многом носит субъективный характер, но есть определенные общие правила, в частности, правила нормализации. В ходе нормализации обеспечивается защита целостности данных путем устранения дублирования данных. В результате представление данных об одном объекте может быть разбито на несколько более мелких связанных таблиц (декомпозиция без потерь). Ограничения, которые должны соблюдаться при проектировании реляционной БД, достаточно многочисленны. Соблюдение ограничений при определении конкретных отношений в БД связано с реализацией нормальных форм. Нормальные формы нумеруются последовательно, начиная от первой. Чем больше номер нормальной формы, которой удовлетворяет БД, тем больше ограничений на хранимые в БД данные должно соблюдаться. Можно к типичным для реляционных СУБД ограничениям ввести дополнительный набор ограничений, что приведет к увеличению числа нормальных форм.
В плохо спроектированной БД вся информация может храниться в одной таблице. Для описанного выше примера такая таблица могла бы содержать следующие столбцы:
| Название магазина | ИНН | Телефон | Улица магазина | Дом магазина | Офис | Фамилия | Имя | Отчество | Год рождения | Улица владельца | Дом владельца | Квартира | Серия | Номер | Банк | Номер счета | Код по ОКОНХ | Код по ОКПО |
Компоненты адреса «Улица» и «Дом» переименованы для соблюдения требования того, что имена столбцов должны быть уникальны (правила именования зависят от конкретной СУБД).
Какие недостатки имеет такое представление?
Первая нормальная форма требует, чтобы на любом пересечении строки и столбца находилось единственное значение, которое должно быть неделимо (требование атомарности). Кроме того, в реляционной таблице не должно быть повторяющихся строк и групп данных.
Требование атомарности выполнено – составные столбцы «Адрес» и «Владелец» (а для владельца «Адрес» и «Паспорт») разбиты на компоненты, которые включены в общую таблицу. Но у одного магазина может быть несколько владельцев, а один человек может владеть несколькими магазинами. Это приводит к тому, что в таблицу нужно будет включать все строки, представляющие «комбинации» магазинов и их владельцев, т.е. в различных строках будут повторяться группы данных (несколько раз будут повторяться данные о магазине – для каждого его владельца, а данные владельца будут повторяться для каждого его магазина). Такое представление данных ведет к огромной избыточности, к тому, что неэффективно будет расходоваться память на ВЗУ. Кроме того, дублирование информации может привести к проблемам при ее обработке: чтобы внести изменения в информацию о магазине (например, если у него изменится счет в банке) нужно изменить эти данные в нескольких записях, соответствующих разным владельцам.
При определении того, какие таблицы должны входить в БД, и того, какая информация в них должна храниться, следует учитывать следующее правило: каждая таблица описывает объект, существующий самостоятельно, обладающий собственными свойствами. Построение БД следует начать с создания представления каждого объекта в виде строк, содержащих его атрибуты, в соответствующей таблице; определения моделей взаимосвязи объектов. В рассматриваемом примере в БД фактически должна храниться информация об объектах двух типов: о магазинах и об их владельцах. Эту информацию следует поместить в две различные таблицы («Магазины» и «Владельцы»), имеющие следующие столбцы:
«Магазины»
| Название магазина | ИНН | Телефон | Улица | Дом | Офис | Банк | Номер счета | Код по ОКОНХ | Код по ОКПО |
«Владельцы»
| Фамилия | Имя | Отчество | Дата рождения | Улица | Дом | Квартира | Серия | Номер |
Каждая строка таблицы «Магазины» будет описывать экземпляр соответствующего объекта (один магазин). А в каждой строке таблицы «Владельцы» будет находиться информация об одном владельце магазина.
При работе с информацией, хранящейся в БД, СУБД должна уметь отличать строки друг от друга. Атрибут или набор атрибутов, однозначно определяющий строку, – это ее первичный ключ.
Что можно выбрать в качестве первичного ключа для описанных выше таблиц?
Ключомотношения является такое множество атрибутов, что каждое сочетание их значений встречается только в одной строке отношения и никакое подмножество этих атрибутов этим свойством не обладает. Таким образом, ключ однозначно определяет строку, позволяет выбрать ее из всего множества строк отношения.
Определим ключ для таблицы «Магазины».
Если выбрать в качестве ключа атрибут «Название магазина», будет ли он удовлетворять указанному требованию? Нет, если в одном городе может быть несколько магазинов с одинаковыми названиями, расположенных в разных частях города. Чтобы гарантировать однозначность следует дополнить название магазина его адресом (по названию магазина и его адресу можно однозначно выбрать нужную строку в таблице), тогда ключ отношения будет составным.
Простым ключом, идентифицирующим нужный магазин, может быть номер расчетного счета в банке (если у каждого магазина единственный номер расчетного счета и каждый расчетный счет принадлежит одному магазину). Ключом может быть также ИНН (идентификационный номер) магазина.
Выберем в качестве первичного ключа атрибут «ИНН». Далее этот атрибут будет использоваться для организации связей между таблицами «Магазины» и «Владельцы» (эти связи должны отражать реальные взаимосвязи между магазинами и их владельцами).
Определимся с ключами и для таблицы «Владельцы».
Если бы можно быль предположить, что среди владельцев магазинов нет однофамильцев, то в качестве ключа можно было бы выбрать атрибут «Фамилия» рассматриваемого отношения. Но, к сожалению, владельцы магазинов могут быть не только однофамильцами, но и полными тесками (маловероятно, но вполне возможно). Поэтому в качестве ключа можно выбрать паспортные данные владельца, т.е. использовать для его идентификации составной ключ, включающий атрибуты «Серия» и «Номер». Этот ключ будем считать первичным. С его помощью установим связь между владельцем и его магазинами.
Первичные ключи обеспечат не только однозначность при поиске информации (они являются уникальными), но и позволят связать данные, находящиеся в двух таблицах.
Определим тип связи между таблицами «Магазины» и «Владельцы».
Если предположить, что один человек может владеть несколькими магазинами, но у каждого магазина есть единственный владелец, то следовало бы установить между этими таблицами связь «один-ко-многим». Для организации такой связи в БД можно было бы в строку таблицы «Магазины», содержащую информацию о магазине, включить внешний ключ, идентифицирующий владельца магазина, т.е. данные его паспорта – атрибуты «Серия» и «Номер». Организовать связь, включив ключ «ИНН», идентифицирующий магазины, в качестве внешнего ключа в таблицу «Владельцы», в данном случае нельзя, так как в этом случае информацию о владельце пришлось бы дублировать для каждого магазина.
Если сделать предположение о том, что один человек может быть владельцем только одного магазина, но у каждого магазина может быть несколько владельцев, получится связь «один-ко-многим», но в данном случае внешний ключ (ИНН магазина) пришлось бы включать в таблицу, содержащую сведения о владельцах.
В действительности каждый человек может оказаться владельцем нескольких магазинов и у каждого магазина может быть несколько владельцев, поэтому между таблицами «Магазины» и «Владельцы» должна быть установлена связь «многие-ко-многим», для организации которой создается специальная таблица, описывающая связи между магазинами и владельцами:
«Магазины-Владельцы»
| ИНН | Серия | Номер |
Эта таблица позволит по атрибуту «ИНН» магазина найти всех его владельцев (через данные их паспортов), а по составному атрибуту, включающему атрибуты «Серия» и «Номер» паспорта владельца найти в БД все магазины, которыми он владеет.
Для этого следует, создав таблицу «Магазины-Владельцы», установить связи «один-ко-многим» между таблицей «Магазины» и таблицей «Магазины-Владельцы», а также между таблицами «Владельцы» и «Магазины-Владельцы»:
| «Магазины» | «Владельцы» | |||||||||
 Название магазина Название магазина | ИНН | … | Фамилия | Имя | … | Серия | Номер | |||
| «Магазины-Владельцы» | ||||||||||
| ИНН | Серия | Номер | ||||||||
Установленные связи помогают СУБД поддерживать целостность, согласованность информации. Например, можно задать правила обновления информации в связанных таблицах при обновлении информации в основной таблице (при ликвидации магазина, например, должна быть удалена и перенесена в архив информация о нем из БД, причем не только строка из таблицы «Магазины», но и вся информация в связанных с ней таблицах, относящаяся к этому магазину).
Для удобства пользователей, ускорения поиска СУБД поддерживают возможность поиска не только по уникальным ключам. Например, найти в таблице можно все магазины с одинаковыми названиями или все магазины, принадлежащие одному владельцу.
Нормализация данных привела к разделению таблиц, выделению отношений «первичный ключ–внешний ключ» в меньшие таблицы. Результатом нормализации является уменьшение избыточности данных – уже не нужно дублировать данные о каждом владельце для каждого магазина.
Вторая нормальная форма требует, чтобы любой неключевой столбец зависел от своего первичного ключа (причем от всего ключа, а не от отдельных его компонентов). Отношение имеет вторую нормальную форму, если оно соответствует первой нормальной форме и не содержит неполных функциональных зависимостей. Неполная функциональная зависимость определяется двумя условиями: ключ отношения функционально определяет некоторый неключевой атрибут и часть ключа функционально определяет тот же неключевой атрибут.
Отношение, не соответствующее второй нормальной форме, характеризуется избыточностью хранимых данных.
В рассматриваемом примере набор атрибутов отношений и выбор ключей сделан таким образом, что таблицы соответствуют второй нормальной форме. Если бы этого соответствия не было, для приведения таблиц ко второй нормальной форме было бы необходимо выделить повторяющуюся информацию (часть ключа и определяемые ею неключевые атрибуты) в отдельную таблицу.
Например: в БД необходимо хранить информацию о товарах, которые поставлены в магазины. Эта информация включает атрибуты «Наименование», «Код» и «Цена» товара, а также «Количество» поставленного товара. Если включить эту информацию в таблицу «Поставки» в следующем представлении:
«Поставки»
| ИНН | Код | Наименование | Цена | Количество |
(здесь «ИНН» идентифицирует магазин, в который выполнена поставка (это внешний ключ, используемый для создания связи «один-ко-многим» таблицы «Магазины» с данной таблицей), «Наименование» – название товара, «Код» – его уникальный код (товары с разными характеристиками и, следовательно, разными ценами могут иметь одно наименование, но коды будут разными), «Цена» – отпускная цена товара, «Количество» – количество поставленного товара), то может возникнуть избыточность.
Для определения строки, представляющей поставку товара в конкретный магазин, можно задать составной ключ, включающий атрибуты «ИНН» и «Код». Эта информация дает возможность определить цену товара и его количество, поставленное в данный магазин, а также вычислить общую стоимость товара. Если предположить, что товар поставляется во все магазины по одной и той же цене, и цена не изменяется со временем, то неключевой атрибут «Цена» определяется не только составным ключом «ИНН» + «Код», но и его частью – атрибутом «Код». Таким образом, одна и та же цена повторяется во всех строках таблицы, где содержится информация о поставке одного и того же товара. Это ведет к избыточности. Наименование товара также определяется его кодом. Поэтому информацию, относящуюся только к товару и не зависящую от магазина, можно вынести в отдельную таблицу:
«Товар»
| Код | Наименование | Цена |
а в таблице «Поставки» оставить только описанную ниже информацию:
«Поставки»
| ИНН | Код | Количество |
Здесь ключевое поле «Код» позволит связать данные, находящиеся в таблице «Поставки», с данными из таблицы «Товары»:
| «Поставки» | ||||
 ИНН ИНН | Код | Количество | ||
| «Товары» | ||||
| Код | Наименование | Цена |
Таким образом, приведение ко второй нормальной форме ликвидировало избыточность путем выделения новых таблиц: таблица «Поставки» разбита на две таблицы «Поставки» и «Товары», между которыми установлена связь.
Третья нормальная форма еще больше повышает требования: отношение соответствует второй нормальной форме и среди его атрибутов отсутствуют транзитивные функциональные зависимости (ни один неключевой столбец не должен зависеть от другого неключевого столбца, он может зависеть только от первичного ключа).
В рассматриваемом примере несоответствие третьей нормальной форме проявилось бы при выполнении такого условия: все товары с одинаковым наименованием имеют одну цену (наименование определялось бы кодом, а цена – наименованием товара). В этом случае появилась бы избыточность, так как цена для данного наименования товара повторялась бы столько раз, сколько различных кодов этого товара используется.
Избавиться от избыточности можно было бы, разбив таблицу «Товары» на две таблицы (одна включала бы атрибуты «Код» и «Наименование», а вторая «Наименование» и «Цена»).
Однако в рассматриваемом примере ситуация другая: товары имеют разные коды, если их характеристики различны, следовательно, должны отличаться и цены.
Четвертая нормальная форма запрещает независимые отношения типа «один ко многим» между ключевыми и неключевыми столбцами. Проще говоря, в одну таблицу нельзя помещать разнородную информацию, т.е. данные, между которыми нет непосредственной связи.
Это правило можно рассмотреть на следующем примере. Сотрудник, занимающийся связями с клиентами, для выполнения своих обязанностей собирается использовать информацию о членах семей владельцев магазинов. Эту информацию не следует включать в таблицу «Владельцы», так как трудно определить, сколько места нужно резервировать в строках таблицы, соответствующих конкретным людям, для хранения данных о их семейном положении, – один может быть одиноким, а другой – многодетным отцом. Информацию о членах семьи нужно вынести в отдельную таблицу, каждая строка которой будет содержать информацию об одном члене семьи, включив в нее внешний ключ, идентифицирующий владельца магазина, для организации связи с таблицей «Владельцы».
Пятая нормальная форма обычно завершает процесс нормализации. На этом этапе все таблицы разбиваются на минимальные части для устранения в них избыточности. Каждый фрагмент неключевых данных в таблицах должен встречаться только один раз. Это снимает проблемы с обновлением информации в БД: все изменения неключевой информации должны вноситься только один раз, что обеспечивает возможность управления целостностью данных.
Процесс проектирования БД является очень важным этапом в разработке информационных систем. Именно качество проектирования во многом определяет эффективность использования БД.
В настоящее время широко используются специальные средства, облегчающие процесс разработки информационных систем (CASE-средства – Computer-Aided Software/System Engineering).
Вопросы для самоконтроля:
1. Что представляет собой база данных?
2. Что такое внешнее представление данных?
3. В чем сущность концептуального представления данных?
4. Что такое модель данных?
5. Что такое нормализация?
6. Что такое ключ отношения?
7. Какой ключ называется внешним?
8. Какие связи могут быть организованы в базе данных?
9. В чем сущность каждой из пяти нормальных форм?
3.2. Задание для самостоятельной работы
Спроектировать базы данных некоторой фирмы, занимающейся обслуживанием клиентов. База данных нужна трем сотрудникам фирмы. Первый из них занимается учетом услуг, оказываемых фирмой, и нуждается в следующей информации:
| Услуги | ФИО исполнителя | Оплачено | ||
| Код услуги | Наименование | Стоимость | ||
| Верстка | ||||
| Набор | ||||
| Печать | ||||
| Сканирование | ||||
| Копирование |
Второй сотрудник собирает сведения об исполнителях и его интересует:
| Номер исполнителя | ФИО | Услуги | |||
| Наименование | Стоимость | Дата приема | Дата исполнения | ||
| К.К.Кукушкин | |||||
| И.О.Гришин | |||||
| П.П.Петров | |||||
| С.С.Сидоров | |||||
| А.А.Андреев | |||||
| А.А.Александров | |||||
| М.К.Сергеев | |||||
| А.П.Аркадьев | |||||
| А.А.Антонов |
Третий сотрудник работает с клиентами и ему важно знать:
| Номер клиента | ФИО | Адрес | Заказы | ||||
| Наименование | Дата приема | Дата исполнения | Стоимость | Оплачено | |||
| И.И.Иванов | Пермь, Ленина, 12-40 | ||||||
| С.С.Сидоров | Пермь, Сибирская, 11-36 | ||||||
| И.И.Ильин | Пермь, Пушкина, 22-65 | ||||||
| О.О.Овсов | Пермь, Ким,16 | ||||||
| К.П.Шишкин | Пермь, Хасана, 4-59 |
Статьи к прочтению:
ТЕМА 1. ПОНЯТИЕ ИНФОРМАЦИОННОЙ СИСТЕМЫ
Похожие статьи:
-
Структура информационной системы
Структуру информационных систем составляет совокупность отдельных ее частей, называемых подсистемами. Функциональные подсистемы реализуют и поддерживают…
-
Базы данных в структуре информационных систем
ОСНОВНЫЕ ПОНЯТИЯ Понятие «база данных» в отличие от понятия «банк информации» изначально связано с компьютерными системами, с историей и развитием….