
Моделирование случайных процессов в системах массового обслуживания
Комуне случалось стоять в очереди и с нетерпением прикидывать, успеет ли он сделать покупку (или заплатить за квартиру, покататься на карусели и т.д.) за некоторое имеющееся в его распоряжении время? Или, пытаясь позвонить по телефону в справочную и натыкаясь несколько раз на короткие гудки, нервничать и оценивать — дозвонюсь или нет? Из таких «простых» проблем в начале XX века родилась весьма непростая наука — теория массового обслуживания, использующая аппарат теории вероятностей и математической статистики, дифференциальных уравнений и численных методов. Основоположником ее стал датский ученый А.К.Эрланг, исследовавший проблемы функционирования телефонных станций.
Впоследствии выяснилось, что новая наука имеет многочисленные выходы в экономику, военное дело. организацию производства, биологиюи экологию; по нейнаписаны десятки книг, тысячи журнальных статей.
Компьютерное моделирование при решении задач массового обслуживания. реализуемое в виде метода статистических испытаний (метода Монте-Карло), хоть и не является в теории массового обслуживания основным, но играет в ней важную роль. Основная линия в ней — получение результатов аналитических, т.е. представленных формулами. Однако, возможности аналитических методов весьма ограничены, в то время как метод статистических испытаний универсален и весьма прост для понимания (по крайней мере кажется таковым).
Типичная задача: очередь к одному «продавцу». Рассмотрим одну из простейших задач данного класса. Имеется магазин с одним продавцом, в который случайным образом входят покупатели. Если продавец свободен, он начинает обслуживать покупателя сразу, если покупателей несколько, выстраивается очередь.
Вот аналогичные задачи:
• ремонтная зона в автохозяйстве и автобусы, сошедшие с линии из-за поломки;
•травмопункт и больные, пришедшие на прием по случаю травмы (т.е. без системы предварительной записи);
• телефонная станция с одним входом (или одной телефонисткой) и абоненты, которых при занятом входе ставят в очередь (такая система иногда практикуется);
• сервер локальной сети и персональные машины на рабочем месте, которые шлют сообщение серверу, способному воспринять разом и обработать не более одного сообщения.
Будем для определенности говорить о магазине, покупателях и продавце. Рассмотрим возникающие здесь проблемы, которые заслуживают математического исследования и, как выясняется, весьма серьезного.
Итак, на входе этой задачи случайный процесс прихода покупателей в магазин. Он является «марковским», т.е. промежутки между приходами любой последовательной пары покупателей — независимые случайные события, распределенные по некоторому закону. Реальный характер этого закона может быть установлен лишь путем многочисленных наблюдений; в качестве простейшей модельной функции плотности вероятности можно взять равновероятное распределение в диапазоне времени от 0 до некоторого Т — максимально возможного промежутка между приходами двух последовательных покупателей. При этом распределении вероятность того, что между приходами двух покупателей пройдет 1 минута, 3 минуты или 8 минут одинакова (если T8).
Такое распределение, конечно, малореалистично; реально оно имеет при некотором значении t = ? максимум и быстро спадает при больших t, т.е. имеет вид, изображенный на рис. 7.56.
Можно, конечно, подобрать немало элементарных функций, графики которых похожи на тот, что изображен на рис. 7.56. Например, семейство функций Пуассона, широко используемых в теории массового обслуживания:
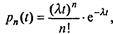 (7.70)
(7.70)
где ? — некоторая константа, п — произвольное целое. Функции (7.70) имеют максимум при 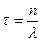 и нормированы:
и нормированы: 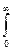 pn(t)dt = 1.
pn(t)dt = 1.
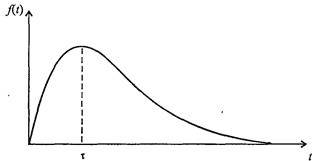
Рис. 7.56. Типичная плотность вероятности распределения времени между приходами покупателей
Второй случайный процесс в этой задаче, никак не связанный с первым, сводится к последовательности случайных событий — длительностей обслуживания каждого из покупателей. Распределение вероятностей длительности обслуживания качественно имеет тот же вид, что и в предыдущем случае; при отработке первичных навыков моделирования методом статистических испытаний вполне уместно принять модель равновероятного распределения.
В таблице 7.8 в колонке А записаны случайные числа — промежутки между приходами покупателей (в минутах), в колонке В — случайные числа — длительности обслуживания (в минутах). Для определенности взято аmax = 10 и bmах = 5. Из этой короткой таблицы, разумеется, невозможно установить, каковы законы распределения приняты для величин А и В; в данном обсуждении это не играет никакой роли. Остальные колонки предусмотрены для удобства анализа; входящие в них числа находятся путем элементарного расчета. В колонке С представлено условное время прихода покупателя, в колонке D — момент начала обслуживания, Е — момент конца обслуживания, F — длительность времени, проведенного покупателем в магазине в целом, G — в очереди в ожидании обслуживания, Н — время, проведенное продавцом в ожидании покупателя (магазин пуст). Таблицу удобно заполнять по горизонтали, переходя от строчки к строчке. Приведем для удобства соответствующие формулы (в них i = 1, 2, 3,…):
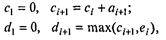
так как начало обслуживания очередного покупателя определяется либо временем его прихода, если магазин пуст, либо временем ухода предыдущего покупателя;
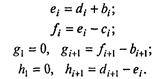
Таблица 7.8
Моделирование очереди
| N | А | В | С | D | Е | F | G | Н |
Таким образом, при данных случайных наборах чисел в колонках A и В и покупателям приходилось стоять в очереди (колонка G), и продавцу — в ожидании покупателя (колонка H).
При моделировании систем такого вида возникают следующие вопросы. Какое среднее время приходится стоять в очереди к прилавку? Чтобы ответить на него, следует найти
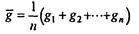
в некоторой серии испытаний. Аналогично можно найти среднее значение величины h. Конечно, эти выборочные средние сами по себе — случайные величины; в другой выборке того же объема они будут иметь другие значения (при больших объемах выборки, не слишком отличающиеся друг от друга). Доверительные интервалы, в которых находятся точные средние значения (т.е. математические ожидания соответствующих случайных величин) при заданных доверительных вероятностях находятся методами математической статистики.
Сложнее ответить на вопрос, каково распределение случайных величин G и Н при заданных распределениях случайных величин А и В. Допустим, в простейшем моделировании мы примем гипотезу о равновероятных распределениях величин A и В — скажем, для А в диапазоне от 0 до 10 минут и В — от 0 до 5 минут. Для построения методом статистических испытаний распределений величин G и Н поступим так: найдем в достаточно длинной серии испытаний (реально — в десятках тысяч, что на компьютере делается достаточно быстро) значения gmax (для Н все делается аналогично) и разделим промежуток [0, gmax] на т равных частей — скажем, вначале на 10 — так, чтобы в каждую часть попало много значений gi. Разделив число попаданий nk в каждую из частей на общее число испытаний n, получим набор чисел pk = 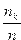 (k = 1, 2,…,n). Построенныепо ним гистограммы дают представление о функциях плотностей вероятности соответствующих распределений. По гистограмме можно составить представление о функции плотности распределения соответствующей случайной величины. Для проверки же гипотезы о принадлежности такого эмпирически найденного распределения тому или иному конкретному виду служат известные статистические критерии.
(k = 1, 2,…,n). Построенныепо ним гистограммы дают представление о функциях плотностей вероятности соответствующих распределений. По гистограмме можно составить представление о функции плотности распределения соответствующей случайной величины. Для проверки же гипотезы о принадлежности такого эмпирически найденного распределения тому или иному конкретному виду служат известные статистические критерии.
Располагая функцией распределения (пусть даже эмпирической, но достаточно надежной), можно ответить на любой вопрос о характере процесса ожидания в очереди. Например: какова вероятность прождать дольше т минут? Ответ будет получен, если найти отношение площади криволинейной трапеции, ограниченной графиком плотности распределения, прямой х = т и у = 0, к площади всей фигуры.
Следующая программа позволяет моделировать описанный выше процесс. На выходе она дает средние значения и дисперсии случайных величин g и h, полученные по выборке, максимальный объем которой порядка 10000 (ограничение связано с малой допустимой длиной массива в PASCALe; чтобы его смягчить, использовано динамическое описание массивов g и h). Кроме того, программа строит гистограммы распределений величин g и h.
Программа 152. Моделирование очереди
Program Cohered;
(входной поток равновероятных событий;
динамические массивы позволяют значительно увеличить объем выборки)
Uses Crt, Graph;
Const N = 10000 (число членов выборки);
W1 = 10 (диапазон времен прихода от 0 дo wl};
W2 = 5 (диапазон времен обслуживания от 0 до w2};
Type Т = Array(l..N] Of Real; U = ^Т;
Var A, B, C, D, E, F, Aa, Bb, Cc, Dd, Ее, Ff, Dg, Dh, M : Real;
Sl, S2 : Double; I, K, J, I1, I2 : Integer;
LI, L2, V : Array [1..11] Of Real; G, H : U; Ch : Char;
Begin
If MaxAvail = SizeOf(G) Then New(G);
If MaxAvail = SizeOf(H) Then New(H);
Randomize; (ниже — имитационное моделирование)
Aa := 0; Bb := W2 * Random; Cc := 0; Ее := Bb; Ff := Bb;
G^[l] = 0; H^[1] := 0;
For К = 1 To 11 Do
Begin L1(K] := 0; L2[K] := 0 End;
For I = 2 To N Do
Begin
A := Wl * Random; В := W2 * Random;
С := Cc + A; If СЕе Then D := С Else D := Ее;
E := D + B; F := E — C; G^[I] := F — B; H^[I] := D — Ее;
Cc := С; Ее := E;
If G^[I]
L2[l] := L2[l] + 1;
For К := 2 To 10 Do
Begin
If (G^[I]К — 1) And (G^[I]
If (H^[I]K — 1) And (H^[I]
End;
If G^[I]10 Then Ll[l1] := Ll[ll] + 1;
If H^[I]10 Then L2[ll] := L2[ll] + 1;
Sl := Sl + G^[l]; S2 := S2 + H^[I];
End;
For I := 1 To 11 Do (ниже — нормировка распределений g и h}
Begin
L1[I] := L1[I] / N; L2[I] := L2[I] / N
End;
(ниже — расчет средних и дисперсий величин g и h}
Sl := Sl / N; S2 := S2 / N; Dg := 0; Dh := 0;
For I := 1 То N Do
Begin
Dg := Dg + Sqr(G^[I] — Sl); Dh := Dh + Sqr(H^[I] — S2)
End;
Dg := Dg / N; Dh := Dh / N;
WriteLn(‘распределение величины g распределение величины h’);
WriteLn;
For K := 1 To 11 Do
WriteLn (’11[‘, K, ‘]=’, L1[K] : 6 : 4, » : 20, ’12(‘, К, ‘]=’,
L2[K] : 6 : 4);
WriteLn;
WriteLn(‘выборочное среднее величины g=’, S1 : 6 : 3,
‘ выборочная дисперсия величины g=’, Dg : 6 : 3);
WriteLn(‘выборочное среднее величины h=’, S2 : 6 : 3,
‘ выборочная дисперсия величины h=’, Dh : 6 : 3);
Dispose(G); Dispose(H); WriteLn;
WriteLn(‘для продолжения нажать любую клавишу’);
Repeat Until KeyPressed; Ch := ReadKey;
(ниже — построение гистограмм распределений величин g и h)
DetectGraph(I, К); InitGraph(I, К, »);
I := GetMaxX; К := GetMaxY; J := I Div 2; M :’= Ll[l];
For I1 := 2 То 11 Do If L1[I1]M Then M := L1[I1];
For I1 := 1 To 11 Do V[I1] := L1[I1] / M;
Line(10, К — 10, J — 20, К — 10); Line[l0, К — 10, 10, 5) ;
OutTextXY(20, 100, ‘распределение величины g’);
For I1 := 1 To 11 Do
Begin
I2 := Round((K — 20) * (1 — V[I1])) + 10;
Line(I1 * 20 — 10, I2, I1 * 20 + 10, I2);
Line(I1 * 20 — 10, I2, I1 * 20 — 10, К — 10);
Line(I1 * 20 + 10, I2, I1 * 20 + 10, К — 10);
End;
Line(J + 20, К — 10, I — 10, К — 10);
Line(J + 20, К — 10, J + 20, 5) ;
OutTextXY(J + 30, 100, ‘распределение величины h’); M := L2[l];
For I1 := 2 To 11 Do If L2[I1]M Then M := L2[I1];
For I1 := 1 To 11 Do V[I1] := L2[I1] / M;
For I1 := 1 To 11 Do
Begin
I2 := Round((K — 20) * (1 — V[I1])) + 10;
Line(J + I1 * 20, I2, J + I1 * 20 + 20, I2);
Line(J + I1 * 20, I2, J + I1 * 20, К — 10);
Line(J + I1 * 20 + 20, I2, J + I1 * 20 + 20, К — 10);
End;
OutTextXY(200, GetMaxY — 10, ‘для выхода нажать любую клавишу’);
Repeat Until KeyPressed; CloseCraph
End.
Приведем для сравнения результаты расчета средних значений величин g, h и соответствующих среднеквадратичных отклонений Sg, Sh, полученные при одинаковых значениях всех параметров в пяти разных сериях испытании по 10000 событий в серии (табл. 7.9) (входной поток покупателей — процесс равновероятных событий с максимальным временем между приходами 10 мин, длительность обслуживания также распределена равновероятным образом в интервале от 0 до 5мин).
Таблица 7.9
Статьи к прочтению:
- Модели вычислений: машина тьюринга, расп, рам, неветвящиеся программы, деревья решений
- Модели внутривидовой конкуренции
Лекция 19: Статистическое моделирование систем массового обслуживания
Похожие статьи:
-
Техника моделирования случайных процессов
Моделирование случайных процессов – мощнейшее направление в современном математическом моделировании. Событие называется случайным, если оно достоверно…
-
Различные примеры моделирования случайных процессов
Метод статистического моделирования имеет множество приложений. Чаще всего он заключается в том, что для решения математической задачи строится некоторая…