
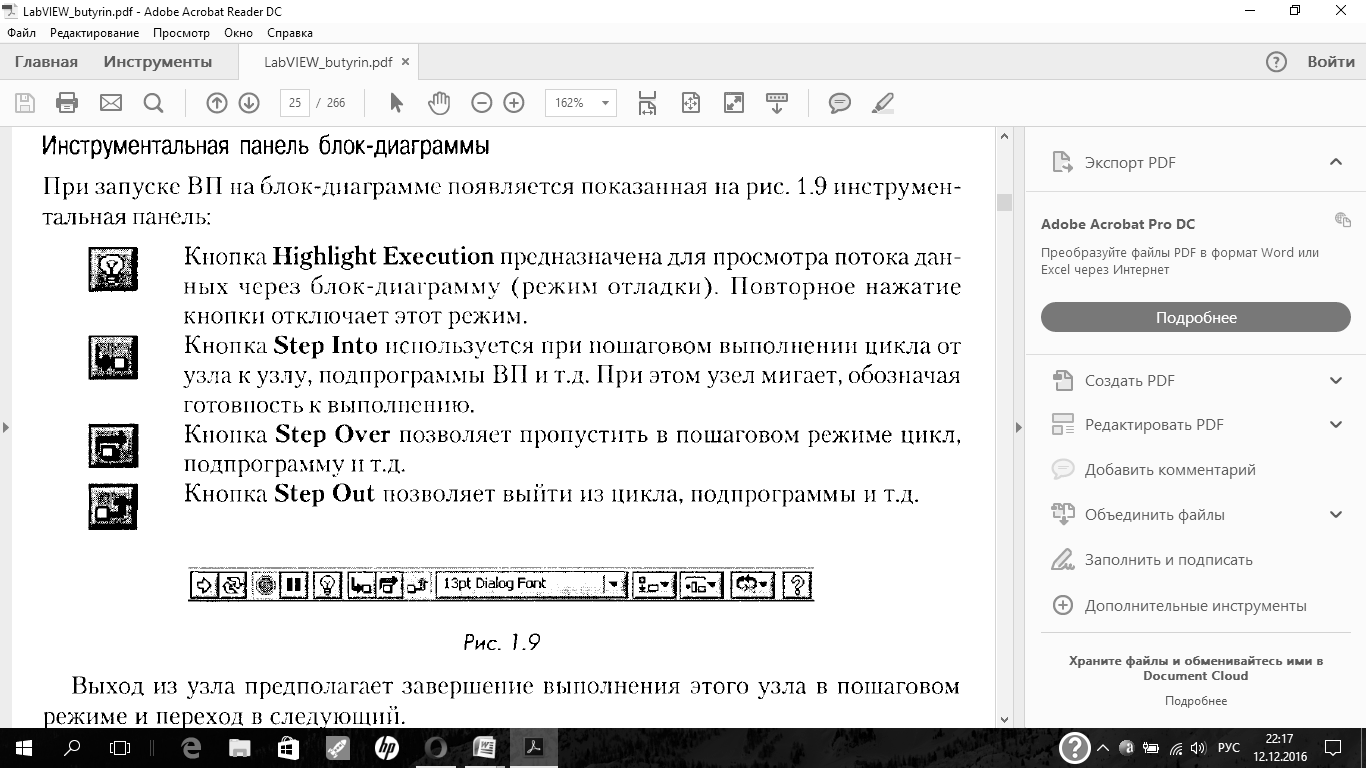
Опишите функции лицевой панели и блок диаграммы виртуального прибора
Программно-инструментальная среда LabVIEW
Среда разработки лабораторных виртуальных приборов LabVIEW (Laboratory Virtual Instrument Engineering Workbench) представляет собой среду прикладного графического программирования, используемую в качестве стандартного инструмента для проведения измерений, анализа их данных и последующего управления приборами и исследуемыми объектами. LabVIEW может использоваться на компьютерах с операционными системами Windows, MacOS, Linux, Solaris и HP-UX.
Компьютер, оснащенный измерительно-управляющей аппаратной частью и LabVIEW, позволяет полностью автоматизировать процесс физических исследований.
Создание любой программы для достижения этих целей (виртуального прибора) в
графической среде LabVIEW отличается большой простотой, поскольку исключает множество синтаксических деталей.
Сфера применимости LabVIEW также непрерывно расширяется. В образовании
она включает лабораторные практикумы по электротехнике, механике, физике. В
фундаментальной науке LabVIEW используют такие передовые центры как CERN
(в Европе), Lawrence Livermore, Batelle, Sandia, Oak Ridge (США), в инженерной
практике — объекты космические, воздушного, надводного и подводного флота,
промышленные предприятий и т.д.
LabVIEW — среда разработки прикладных программ, в которой используется язык
графического программирования G и не требуется написания текстов программ.
Среда LabVIEW дает огромные возможности как для вычислительных работ, так
и — главным образом — для построения приборов, позволяющих проводить измерения физических величин в реальных установках, лабораторных или промышленных, и осуществлять управление этими установками.
Программа, написанная в среде LabVIEW, называется виртуальным прибором
(ВП) (VI — virtual instrument). Внешнее графическое представление и функции ВП
имитируют работу реальных физических приборов. LabVIEW содержит полный
набор приборов для сбора, анализа, представления и хранения данных. Источником кода виртуального инструмента служит блок-схема программируемой задачи.
Программная реализация виртуальных приборов использует в своей работе принципы иерархичности и модульности. Виртуальный прибор, содержащийся в составе
другого виртуального прибора, называется прибором-подпрограммой (SubVI).
Опишите функции лицевой панели и блок диаграммы виртуального прибора
При нажатии кнопки New открывается окно CreateNew (создать новый ВП), где
расположено меню, из которого можно выбрать либо пустые окна ВП (Blanc VI),
либо окна с различными шаблонами (VI from Templates). Выберем пустые окна ВП
(Blanc VI), и нажмем кнопку ОК. На экране появляются две совмещенные панели,
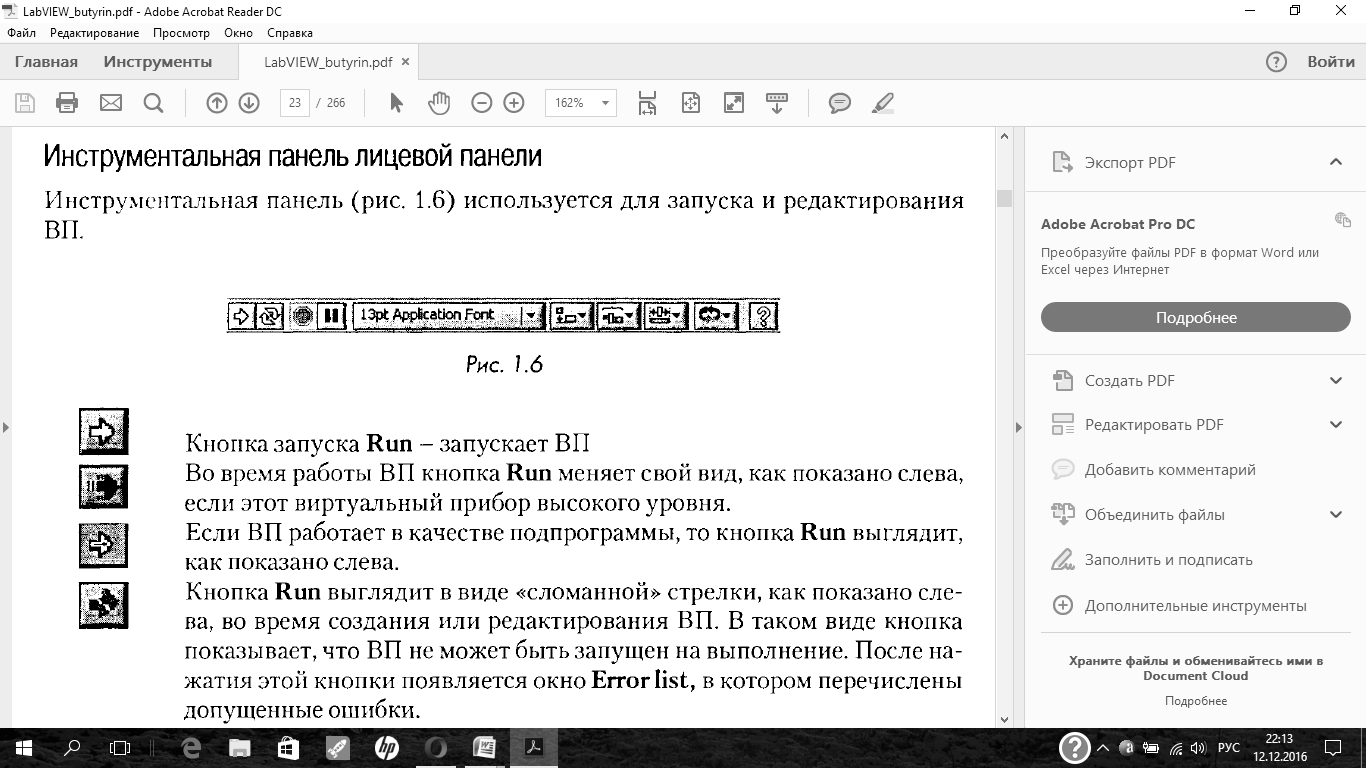
расположенные каскадом. Одна из них -лицевая панель (Front Panel) — имеет серый цвет рабочего пространства, другая — панель блок-диаграмм (Block Diagram) — белый цвет. Для развертывания панелей на левую и правую половины экрана нужно нажать на клавиатуре одновременно Ctrl+T.Панели можно развернуть также нажатием Windowsв верхней части панели и затем The Left and Right.(Выбрав The Up and Down,можно развернуть панели на верхнюю и нижнюю половины экрана). Каждая из этих панелей может быть развернута на весь экран нажатием кнопки с изображением прямоугольника в верхнем правом углу панели. Возврат к двум панелям осуществляется нажатием той же кнопки с изображением сдвоенных прямоугольников.
Лицевая панель
Лицевая (передняя) панель имитирует панель реального физического прибора. На ней
располагаются управляющие и измерительные элементы виртуального прибора.
Пример лицевой панели представлен на рис. 1.3.
Палитра элементов лицевой панели
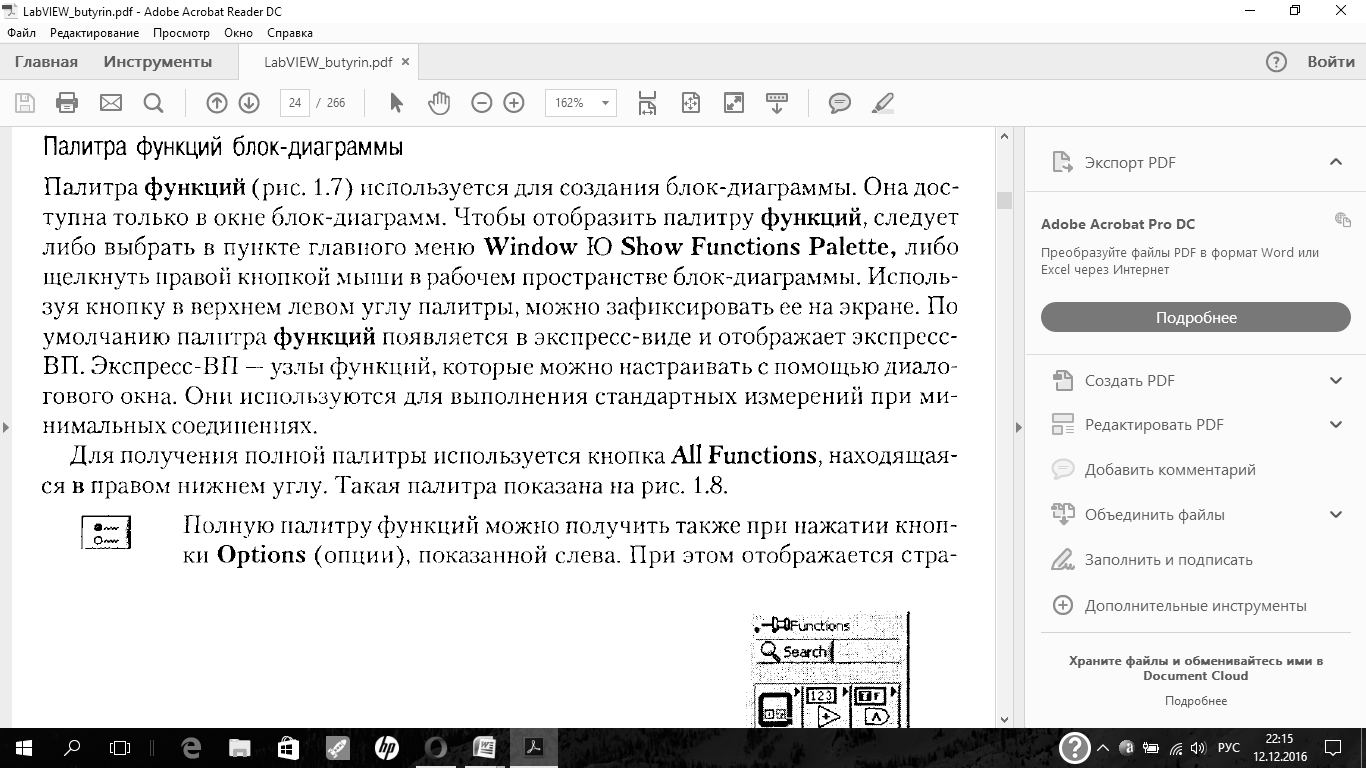
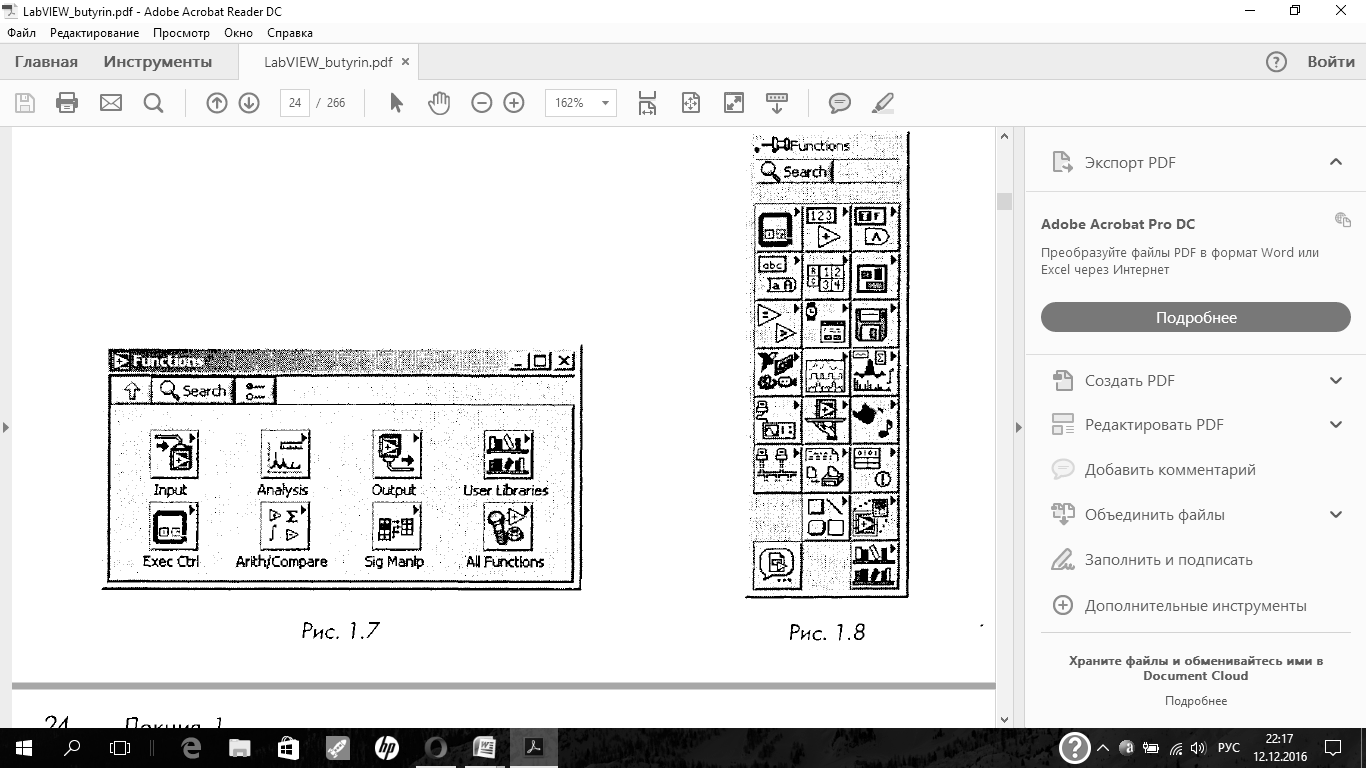
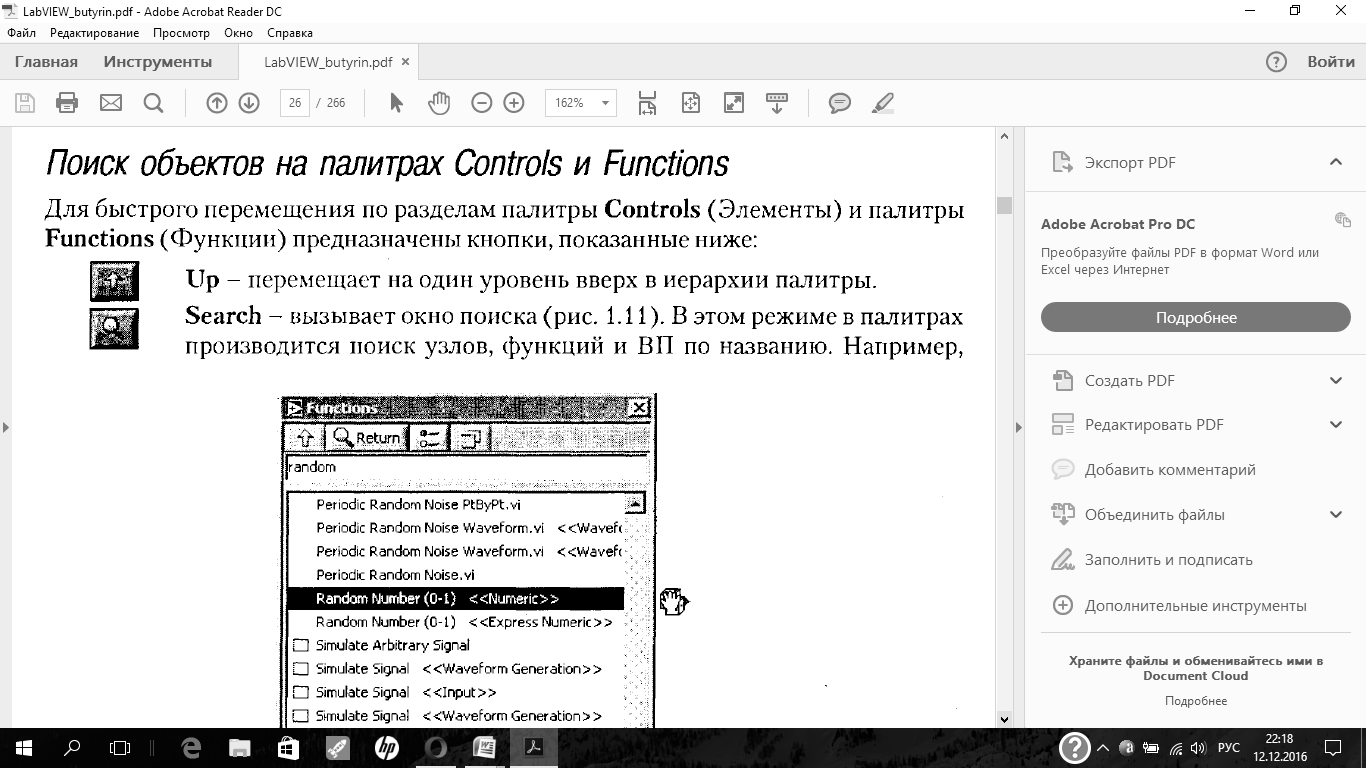
Лицевая панель создается с использованием палитры элементов под общим названием Controls,которая вызывается нажатием правой клавиши мыши на свободное поле лицевой панели (либо можно выбрать в пункте главного меню Window =
= Show Controls Palette).Эти элементы могут быть либо средствами ввода данных —
элементами собственно управления (Controls),либо средствами отображения
данных — элементами отображения (Indicators).
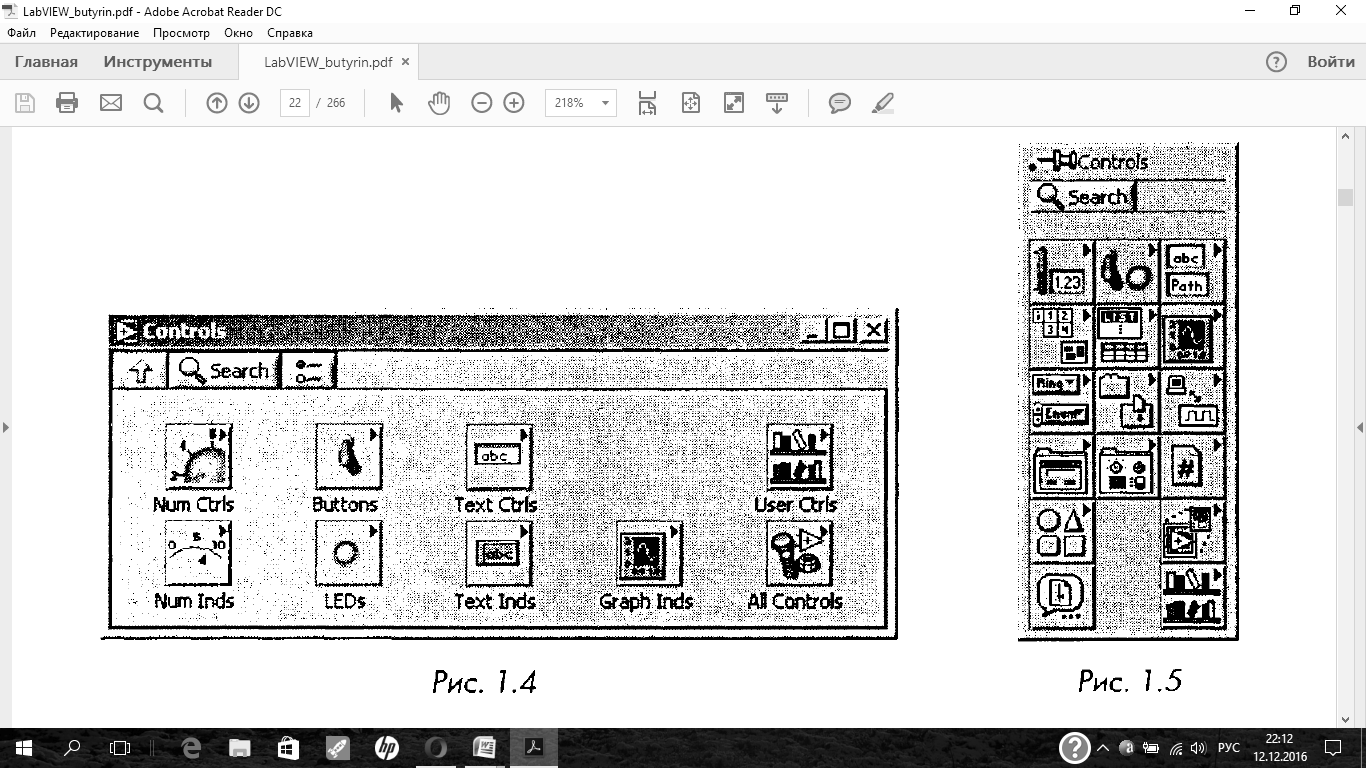
По умолчанию палитра элементов появляется в экспресс-виде (рис. 1.4) и содержит лишь наиболее часто используемые элементы.
Выбранный элемент выделяется инструментом перемещение(стрелка) и
выводится на лицевую панель.
Для получения полной палитры используется кнопка All Controls,находящаяся
в правом нижнем углу. Такая палитра показана на рис. 1.5.
Данные, вводимые на лицевой панели ВП, поступают на блок-диаграмму, где ВП
производит с ними необходимые операции. Результат вычислений передается на
элементы отображения информации на лицевой панели ВП.
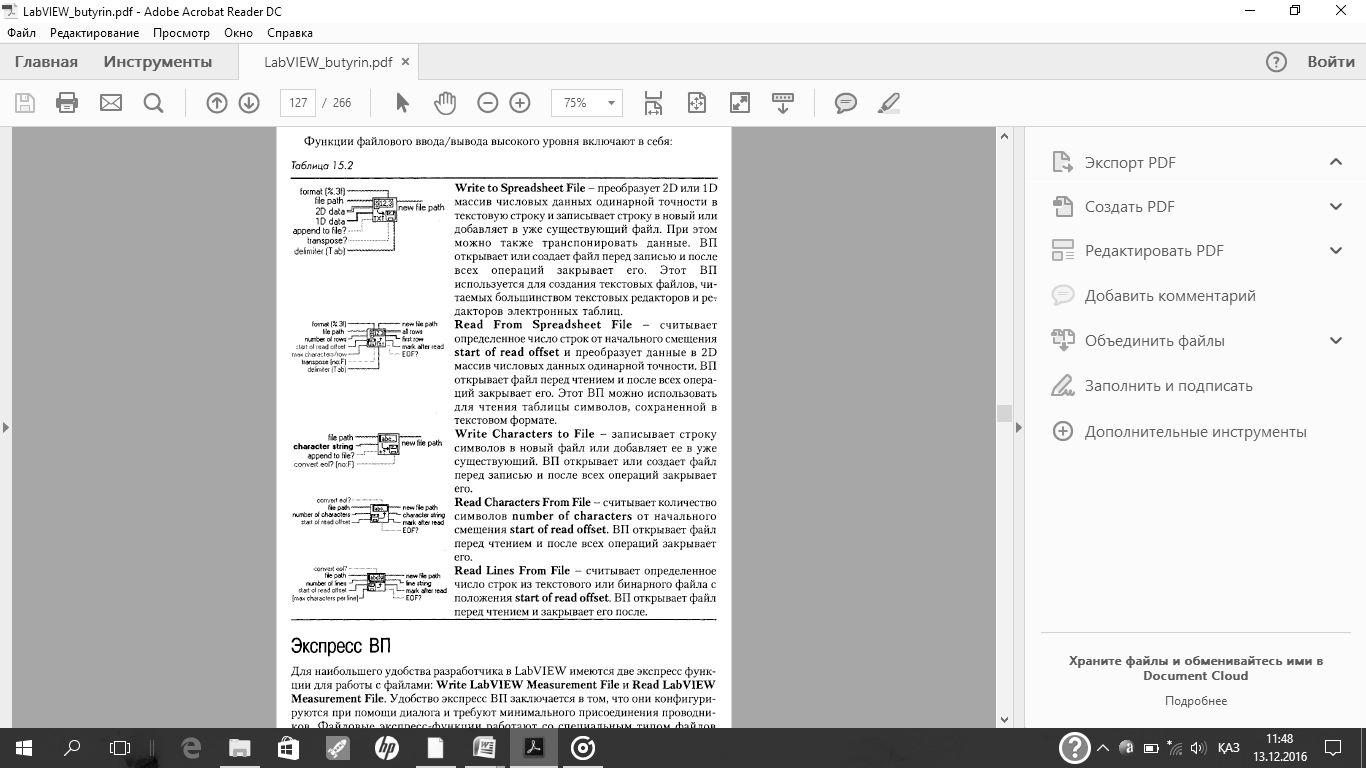
| Напишите функции файлового ввода/выводавысокого уровня. |
Функции файлового ввода/вывода высокого уровня
Функции файлового ввода/вывода высокого уровня расположены в верхней строке палитры Functions = File I/O.Они предназначены для выполнения основных операций по вводу/выводу данных. Использование функций файлового ввода/вывода высокого уровня позволяет сократить время и усилия программистов при записи и считывании данных в/из файл(а). Функции файлового ввода/вывода высокого уровня выполняют запись и считывание данных и операции закрытия и открытия файла. При наличии ошибок файловые функции высокого уровня отображают диалоговое окно с описанием
ошибок, в котором пользователю предлагается продолжить выполнение программы или остановить ее. Однако из-за того, что функции данного класса объединяют весь процесс работы с файлами в один ВП, переделать их под определенную задачу бывает трудно. Для специфических задач следует использовать функции файлового ввода/вывода низкого уровня.
| Перечислите математические функции иоператоры структуры Formula Node |
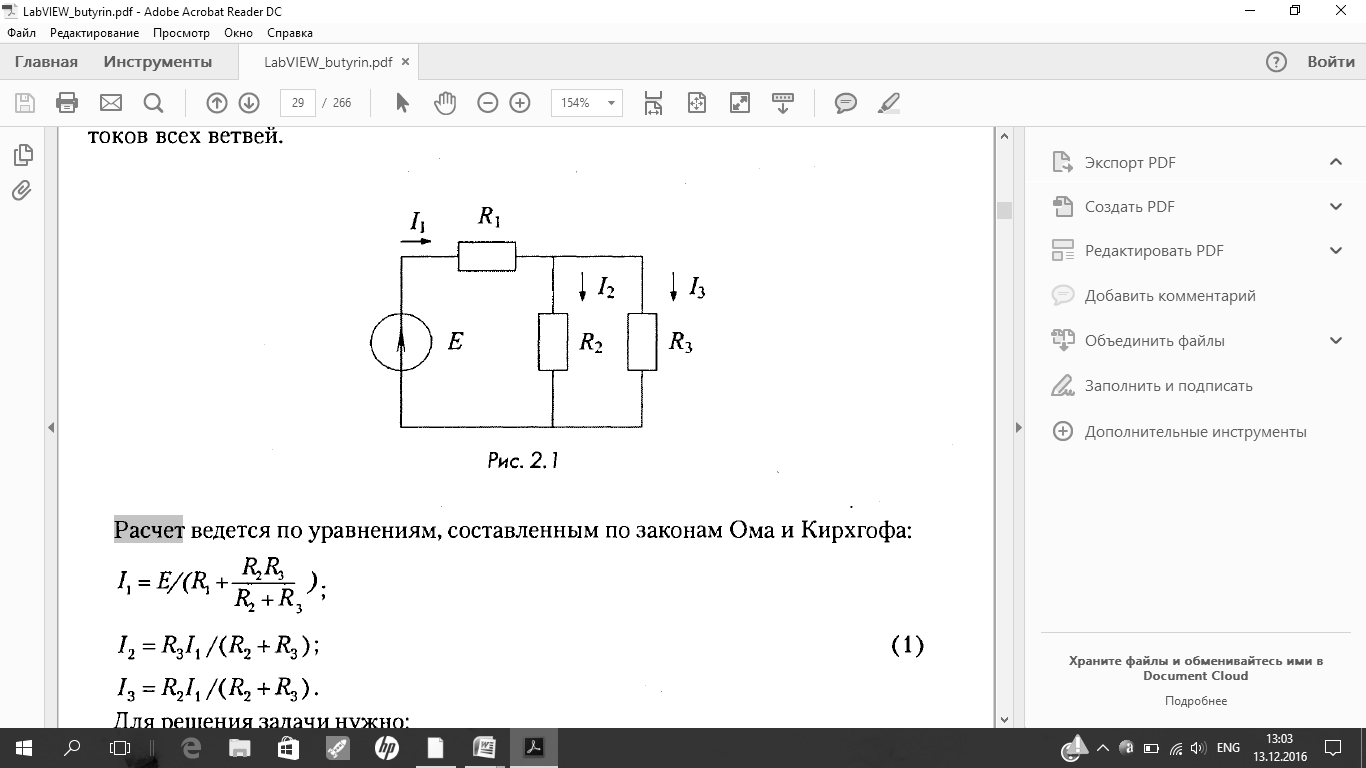
Задача: составить уравнения для токов этой схемы и решить их различными способами: с использованием формульного узла (структуры LabVIEW, предназначенной для расчетов по формулам).
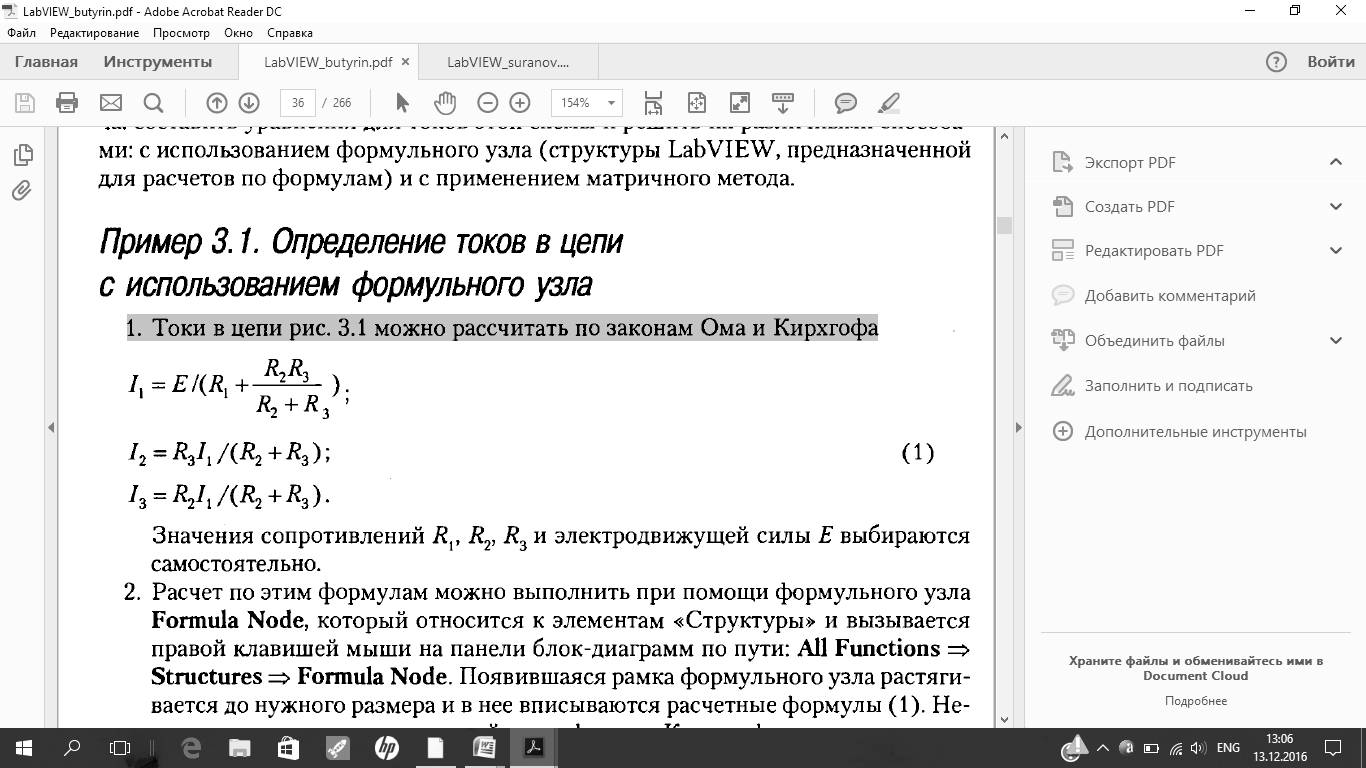
1. Токи в цепи рис. 3.1 можно рассчитать по законам Ома и Кирхгофа
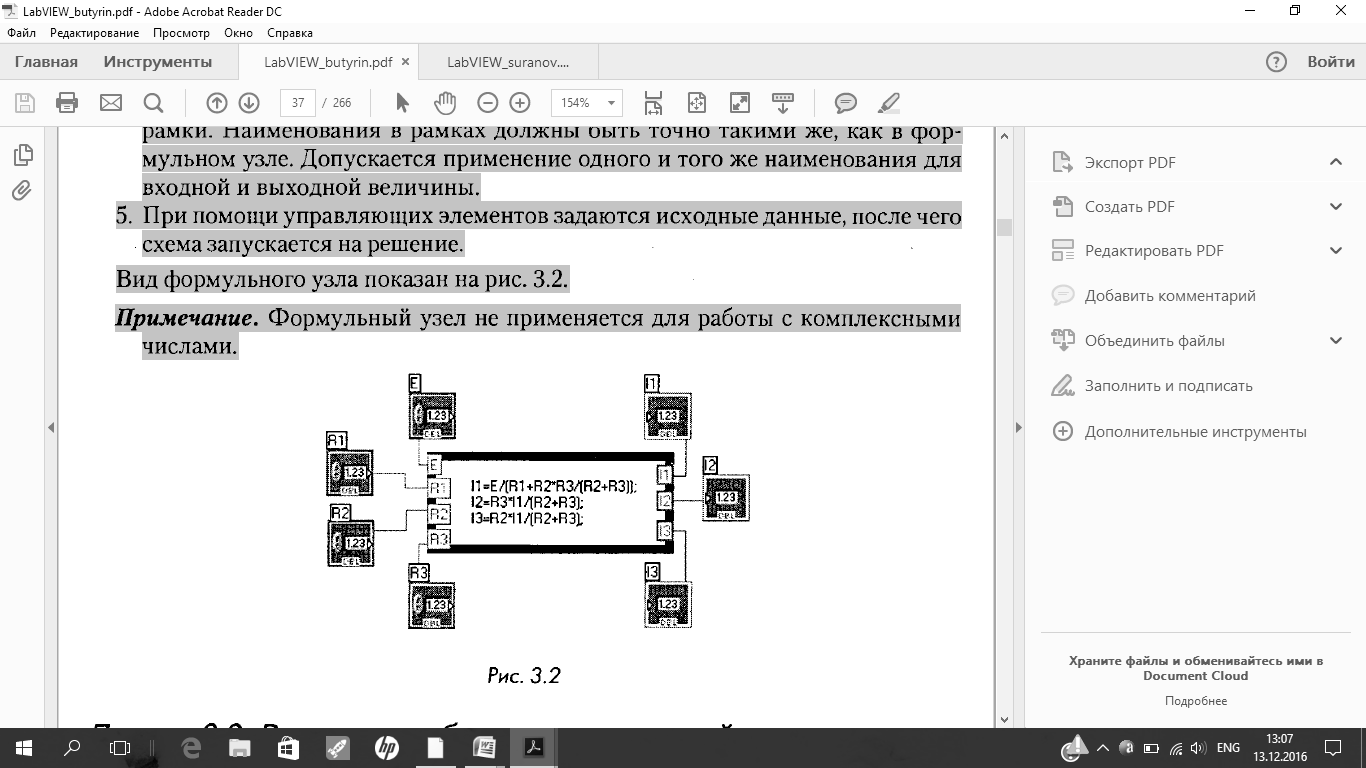
2. Расчет по этим формулам можно выполнить при помощи формульного узла Formula Node,который относится к элементам Структуры и вызывается правой клавишей мыши на панели блок-диаграмм по пути: All Functions = Structures = Formula Node.Появившаяся рамка формульного узла растягивается до нужного размера и в нее вписываются расчетные формулы (1). Неизвестные записываются в левой части формул. Каждая формула пишется на отдельной строке и заканчивается точкой с запятой.
3. Затем в формулы нужно внести исходные данные и вывести результаты расчета. Для этого курсор устанавливается правой клавишей мыши на рамке формульного узла и из всплывающего меню левой клавишей вызывается Add Input(добавить вход) для входных величин и Add Output(добавить выход) для выходных величин. В появившиеся рамки вписываются наименования этих величин.
4. К входным рамкам подключаются цифровые управляющие элементы, к выходным — индикаторы. Входы и выходы можно устанавливать в любом месте рамки. Наименования в рамках должны быть точно такими же, как в формульном узле. Допускается применение одного и того же наименования для входной и выходной величины.
5. При помощи управляющих элементов задаются исходные данные, после чего схема запускается на решение.
Примечание. Формульный узел не применяется для работы с комплексными числами.
| Напишите виды матричных операции в средеLabVIEW |
Ввиду того, что вычислительные операции в матричной форме имеют исключительно важное значение, рассмотрим их подробнее.
LabVIEW поддерживает все основные матричные операции. По своей сути матрица является двумерным массивом, а значит, к ней применимы все операции по
работе с многомерными массивами.
Использование матриц и матричных вычислений обычно упрощает внешний вид
и структуру программы, однако следует помнить, что массивы могут занимать в
памяти значительное пространство, а операции над матрицами требуют для своей
реализации большого числа алгебраических вычислений.
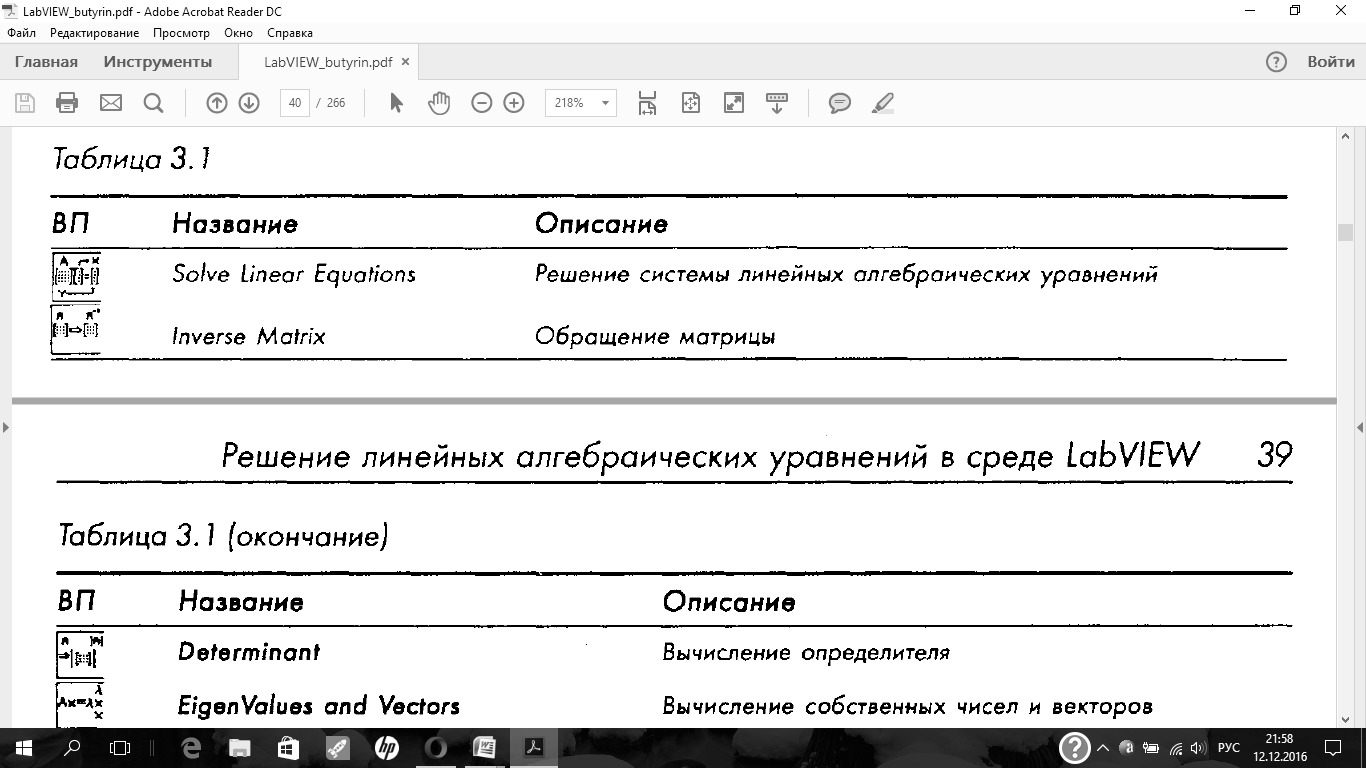
ВП для работы с матрицами находятся на панели All Functions = Analyze =
Mathematics = Linear Algebra.Список функций по работе с матрицами приведен
в табл. 3.1

Различные матричные функции в LabVIEW имеют похожий набор входных и
выходных параметров. Один из входов, matrix type,позволяет уточнить структуру
исходной матрицы. Значения свойства matrix type приведены в табл. 3.2.
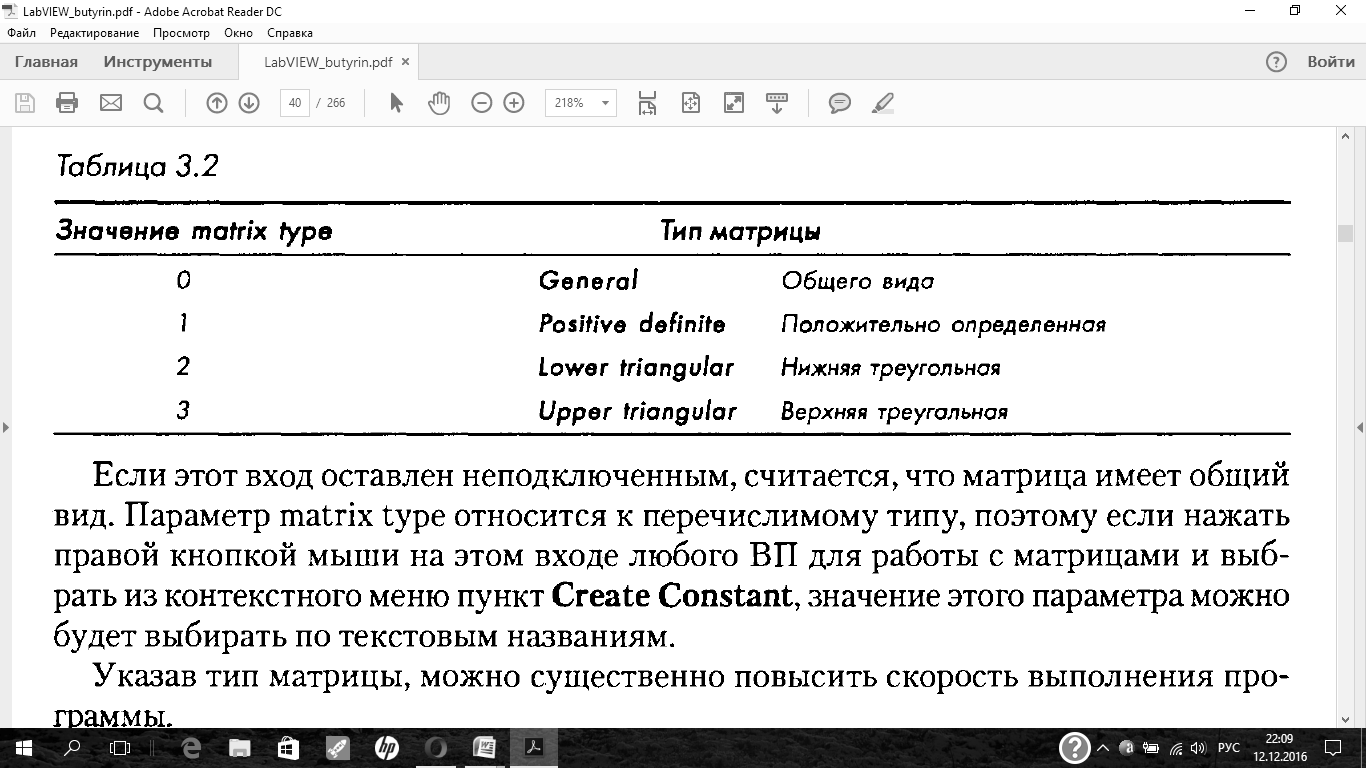
Если этот вход оставлен неподключенным, считается, что матрица имеет общий
вид. Параметр matrix type относится к перечислимому типу, поэтому если нажать
правой кнопкой мыши на этом входе любого ВП для работы с матрицами и выбрать из контекстного меню пункт Create Constant,значение этого параметра можно будет выбирать по текстовым названиям.
Указав тип матрицы, можно существенно повысить скорость выполнения программы.
На панели Linear Algebraимеются еще две функции: Dot Product и Outer
Product. Dot Product(скалярное произведение) считает первый вектор строкой, а
второй столбцом и вычисляет сумму произведений элементов векторов. Outer
Product(внешнее произведение) формирует матрицу из произведений взаимно
ортогональных элементов.
В полной версии LabVIEW на панели Linear Algebraимеется еще функция, предназначенная для вычисления собственных чисел и собственных векторов матриц. К ее входу помимо самой матрицы подключаются два специальных признака. Первый из них matrix typeуказывает тип матрицы, причем здесь, в отличие от других матричных операций, предусмотрено всего два типа матриц: общего вида и симметричная. Если на вход подается симметричная матрица, в качестве matrix typeследует указать единицу. Второй признак output option определяет, нужно ли вычислять собственные векторы: если к нему подключить О, будут вычислены только собственные числа, в противном случае и собственные числа и собственные векторы.
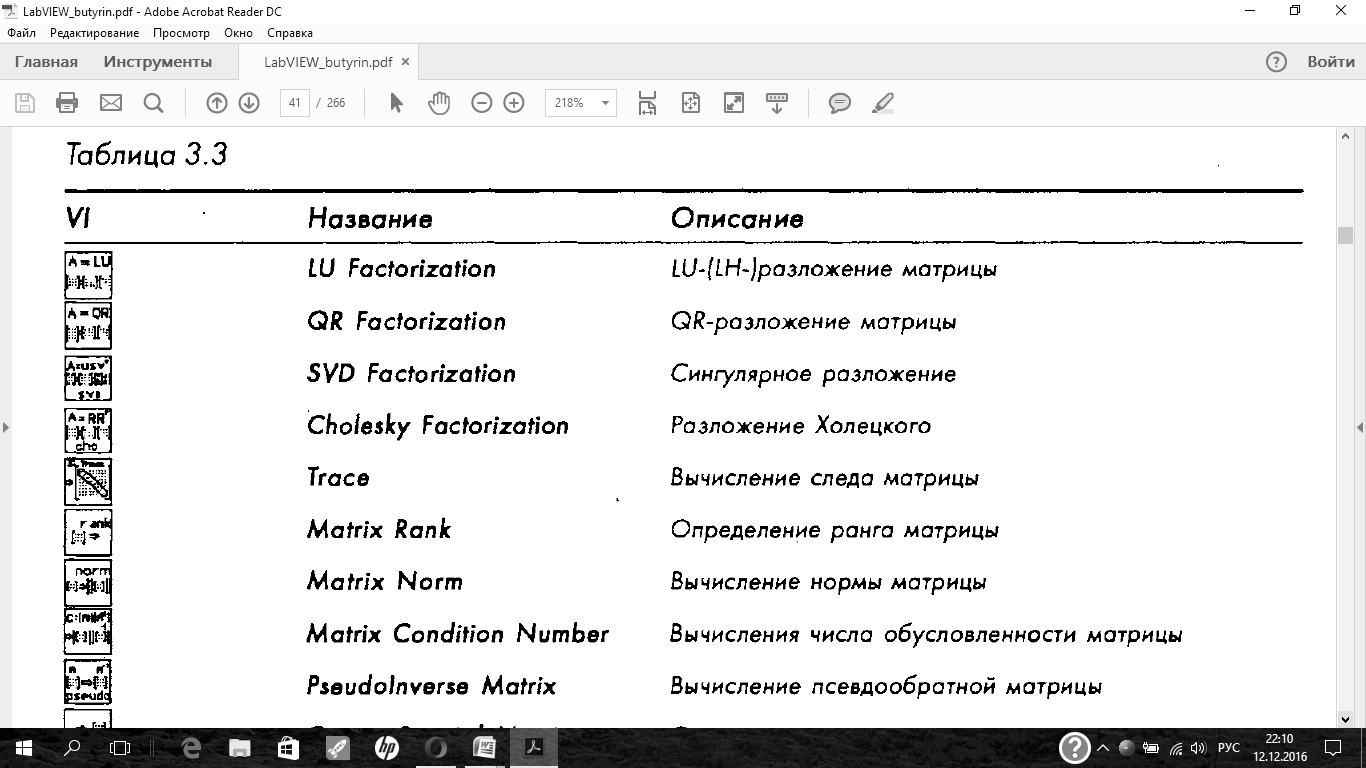
Полная версия Lab VIEW содержит на панели Linear Algebraеще две вспомогательные панели: Complex Linear Algebra и Advanced Linear Algebra.Первая панель содержит те же инструменты, что и панель Linear Algebra,но предназначенные для работы с комплексными числами. Вторая содержит более сложные функции, список которых приведен в табл. 3.3.
| Опишите основные функции работы смассивами |
Массив — это набор элементов определенной размерности. Массивы объединяют элементы одного типа данных. Элементами массива называют группу составляющих его объектов. Размерность массива — это совокупность столбцов (длина) и строк (высота), а также глубина массива. Массив может быть одномерным (вектор), двумерным (матрица) или многомерным, и содержать до 231-1 элементов в каждом направлении, насколько позволяет оперативная память. Данные, составляющие массив, могут быть любого типа: численные, логические или строковые. Массив также может содержать элементы графического представления данных и кластеры. Массивы удобно использовать при работе с группами данных одного типа и при накоплении данных после повторяющихся вычислений. Все элементы массива упорядочены. Каждому элементу присвоен индекс, причем нумерация элементов массива всегда начинается с 0. Таким образом, индексы
массива находятся в диапазоне от 0 до (я-1), где п — число элементов в массиве.
Создание массива элементов управления и индикации
Для создания массива элементов управления или индикации данных необходимо выбрать шаблон массива из палитры Controls = ArrayClusterи поместить его на лицевую панель. Затем в шаблон массива поместить элемент управления или индикации данных (см. рис. 6.1). При этом терминал элемента на блок диаграмме приобретет цвет, соответствующий типу данных элементов массива. Поместить элемент в шаблон массива следует до того, как он будет использоваться на блок-диаграмме. Если этого не сделать, то шаблон массива не будет инициализирован, и использовать массив будет нельзя. Подобным образом можно создать массив-константу. Для этого необходимо выбрать шаблон Functions = Array = Array constantи поместить в него константу
необходимого типа.
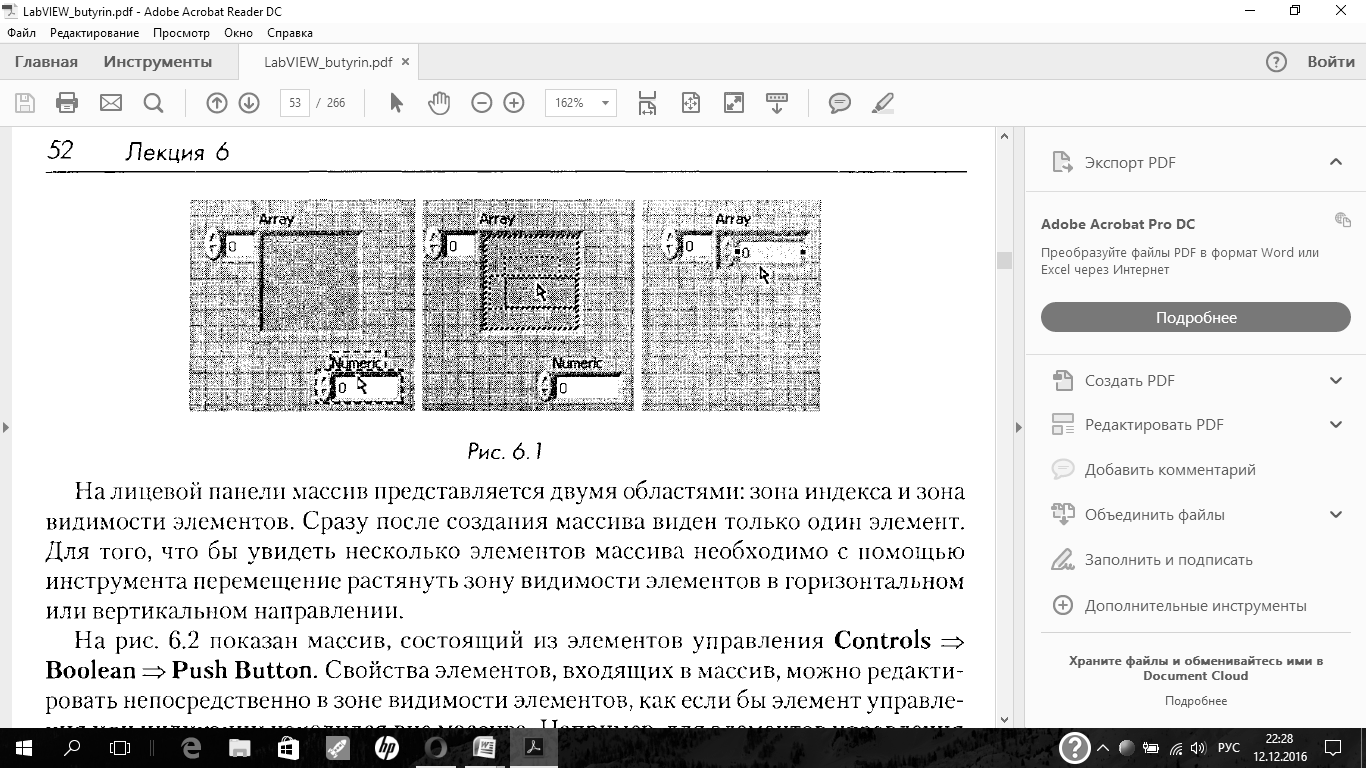
На лицевой панели массив представляется двумя областями: зона индекса и зона видимости элементов. Сразу после создания массива виден только один элемент. Для того, что бы увидеть несколько элементов массива необходимо с помощью инструмента перемещение растянуть зону видимости элементов в горизонтальном или вертикальном направлении.
На рис. 6.2 показан массив, состоящий из элементов управления Controls =
Boolean = Push Button.Свойства элементов, входящих в массив, можно редактировать непосредственно в зоне видимости элементов, как если бы элемент управления или индикации находился вне массива.
Обратите внимание на то, что у всех элементов массива различаются только их значения, а все свойства: размер, цвет, точность, представление и т.д. могут быть только одинаковыми. Изменяя свойство у одного из элементов массива, вы изменяете свойства всех элементов.
В зоне индекса задается номер элемента массива, начиная с которого показываются элементы массива в зоне видимости элементов, т.е. индекс левого верхнего отображенного элемента. По умолчанию это значение 0. Это значит, что элементы массива показаны, начиная с нулевого элемента. Изменяя значение индекса можно наблюдать любой последовательный участок массива.
При желании можно удалить зону индекса. Для этого необходимо вызвать контекстное меню и выбрать пункты Visible Items = Index Display.
Двумерные массивы
Двумерный (2D) массив представляет собой прямоугольную таблицу (матрицу). Каждый элемент двухмерного массива характеризуется двумя индексами. Пример двухмерного массива размерностью 6 x 4.
Для увеличения размерности массива необходимо щелкнуть правой кнопкой мыши по элементу индекса и выбрать из контекстного меню пункт Add Dimension.
Также можно использовать инструмент перемещение. Для этого надо просто изменить размер элемента индекса. Таким образом, можно увеличить размерность массива с одномерного до двумерного и выше, при этом зона видимости элементов становиться двумерной.
Следует отметить, что для массивов размерностью от 3 и выше в зоне видимости элементов показывается двумерный срез массива. При этом числа в элементе индекса будут указывать индекс (координаты) левого верхнего отображаемого элемента.
На блок-диаграмме массив изображается утолщенным проводником, толщина которого зависит от размерности массива (рис 6.6).
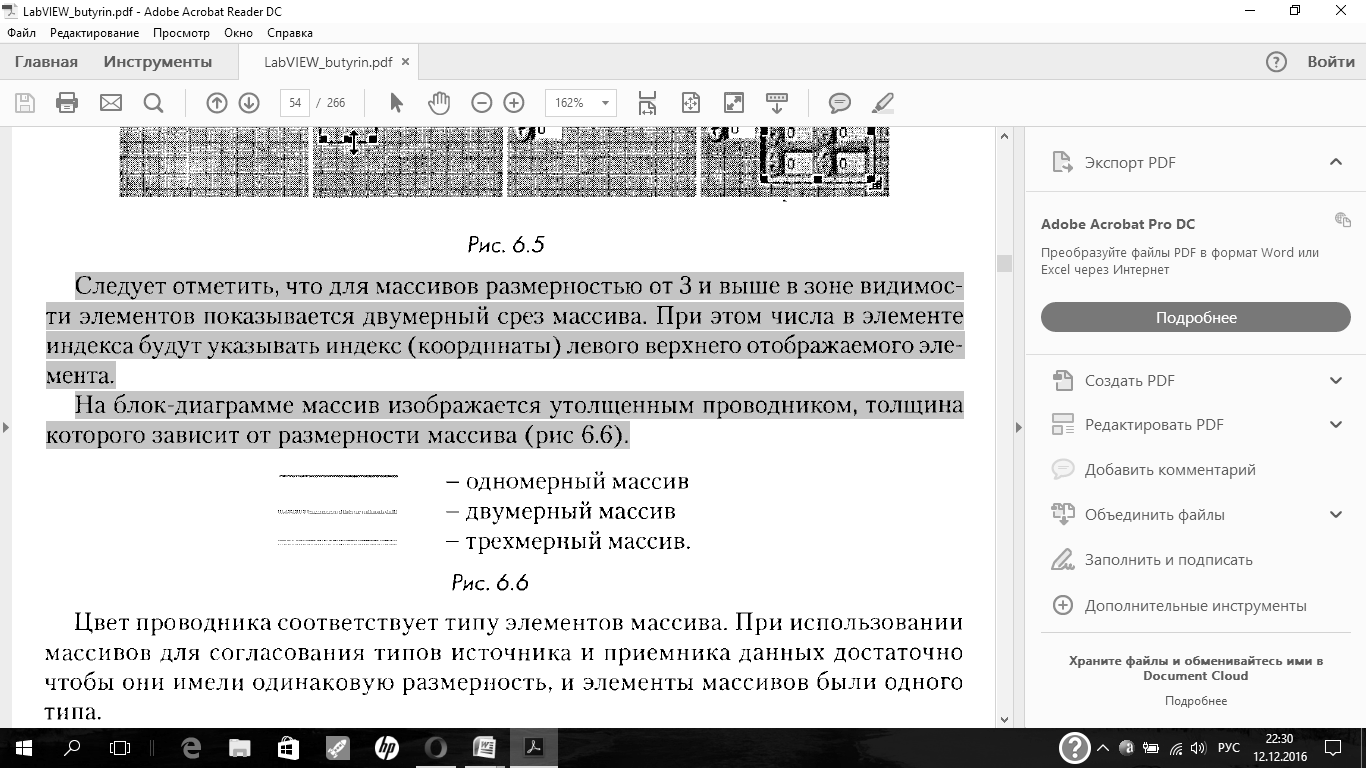
Цвет проводника соответствует типу элементов массива. При использовании массивов для согласования типов источника и приемника данных достаточно чтобы они имели одинаковую размерность, и элементы массивов были одного типа.
Математические функции (полиморфизм)
Для выполнения простейших математических операций над элементами массива можно использовать стандартные функции, расположенные в палитре Functions =Numeric.Все они являются полиморфными. Это означает, что на поля ввода этих функций могут поступать данные различных типов (скалярные величины, массивы). Например, можно использовать функцию Addдля прибавления скалярной величины к массиву или сложения двух массивов. Если на одно поле ввода данных функции Addподать скалярную величину 2, а другое поле соединить с массивом, то функция прибавит 2 к каждому элементу массива.
Если на вход функции Addподать два массива одинаковой размерности, функция сложит каждый элемент первого массива с соответствующим элементом второго. Если с помощью функции Addсложить два массива разного размера, то функция сложит каждый элемент первого массива с соответствующим элементом второго и выдаст результат в виде массива с размером меньшего из двух исходных (рис. 6.7).
В Lab VIEW, в отличие от большинства языков программирования, для того чтобы производить вычисления с элементами массивов, не потребуется использовать цикл. Большинство функций полиморфны и работают с массивами так же как со скалярными величинами. Например, для вычисления синуса от каждого элемента массива достаточно подать этот массив на вход соответствующей функции (рис. 6.8).
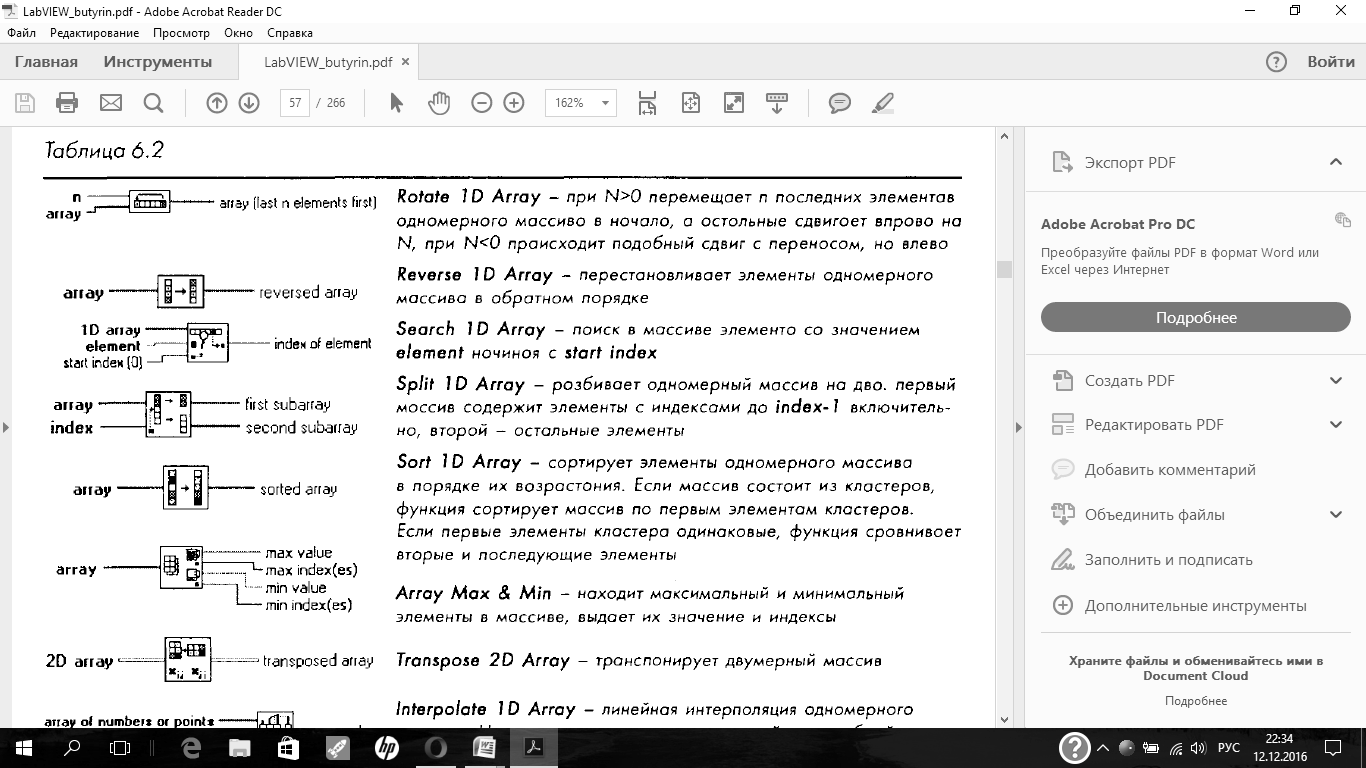
Основные функции работы с массивами
Для работы с массивами предназначены следующие функции из палитры
Functions = Array:


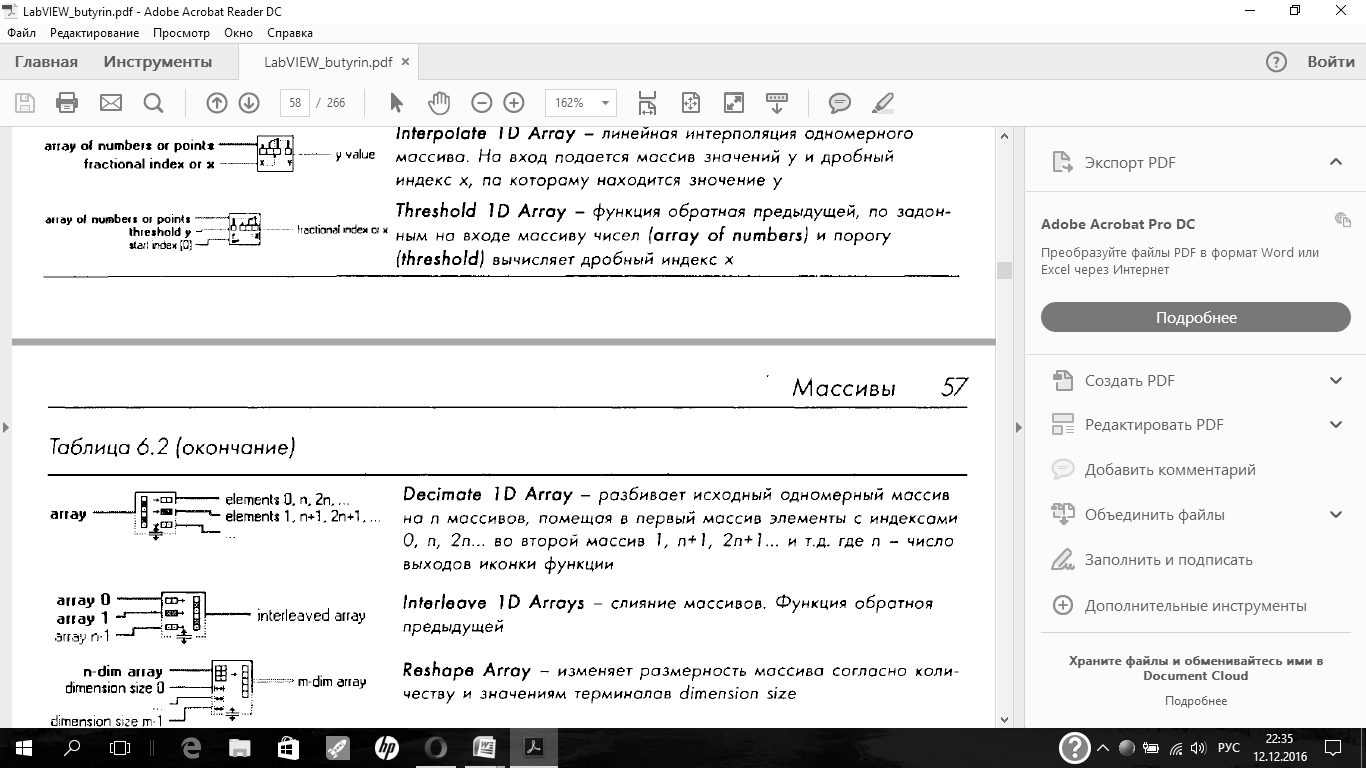
Дополнительные функции работы с массивами
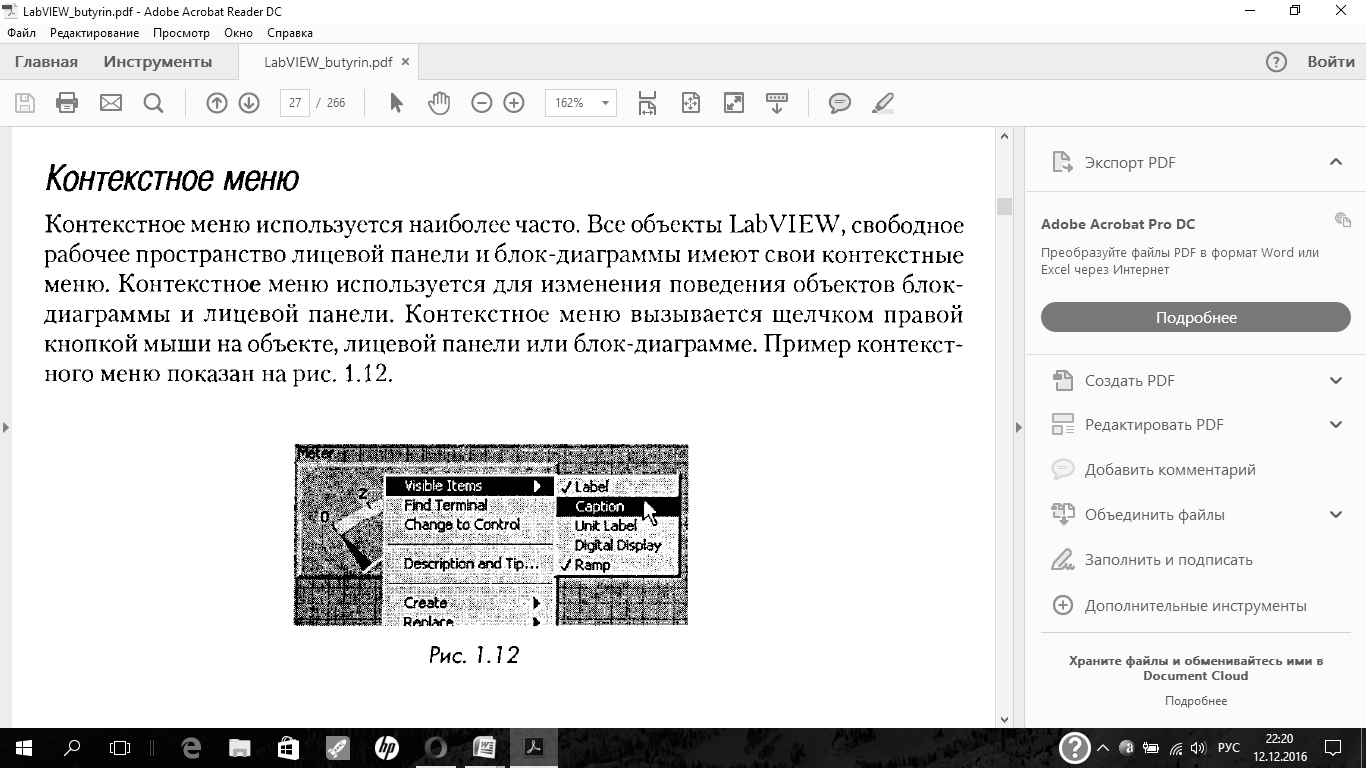
| Перечислите виды структур в LabVIEW иопишите их |
С помощью структур можно осуществить повторение отдельных частей программы, выполнение той или иной части программы в зависимости от какого-либо условия, выполнение программы в строго определенном порядке. Вызвать любую структуру можно из палитры Functions = Structures.
Любая структура изображается в виде рамки, внутри которой содержится один или несколько участков программы. Каждый такой участок программы называется
поддиаграммой. По краям структуры могут быть помещены входные и выходные терминалы. Вы можете наложить структуру на уже существующий участок программы или наоборот сначала поместить структуру, а за тем создавать элементы внутри нее.
Контекстное меню структуры вызывается при нажатии правой кнопки мыши на рамке структуры. Общими для всех структур пунктами контекстного меню являются:
Auto Grow- если флажок установлен, то при помещении объектов во внутрь структуры, она будет соответственно увеличивать размер.
Remove… — удаление соответствующей структуры.
Replace with … -изменить уже существующую структуру на структуру другого вида, подобную по функциональности.
Виды:
Цикл For выполняет участок программы расположенный в поддиаграмме цикла
определенное количество раз.
[N] — терминал общего числа итераций, определяет общее число итераций.
[i] — терминал счетчика итераций, содержит номер текущей итерации, начиная с 0.
Данные могут поступать в цикл For (или выходить из него) через терминалы входных/выходных данных цикла. Терминалы входных/выходных данных цикла передают данные из структур и в структуры. Они представляют собой цветные прямоугольники и располагаются на границе области цикла. Прямоугольник принимает цвет типа данных, передаваемых по терминалу. Данные выходят из цикла по его завершении. Пока цикл не выполнил все положенные итерации выходные данные получить нельзя.
Число итераций цикла For должно быть известно до начала выполнения цикла.
Имеется две возможности задать это число:
Непосредственно присоединить проводник к терминалу общего числа итераций [N]
Присоединить к одному из входных терминалов массив. В этом случае структура сама разберет массив на элементы.
Цикл For может автоматически разбирать массив на элементы на входе и собирать
из отдельных элементов массив на выходе. Это свойство называется автоиндексацией.
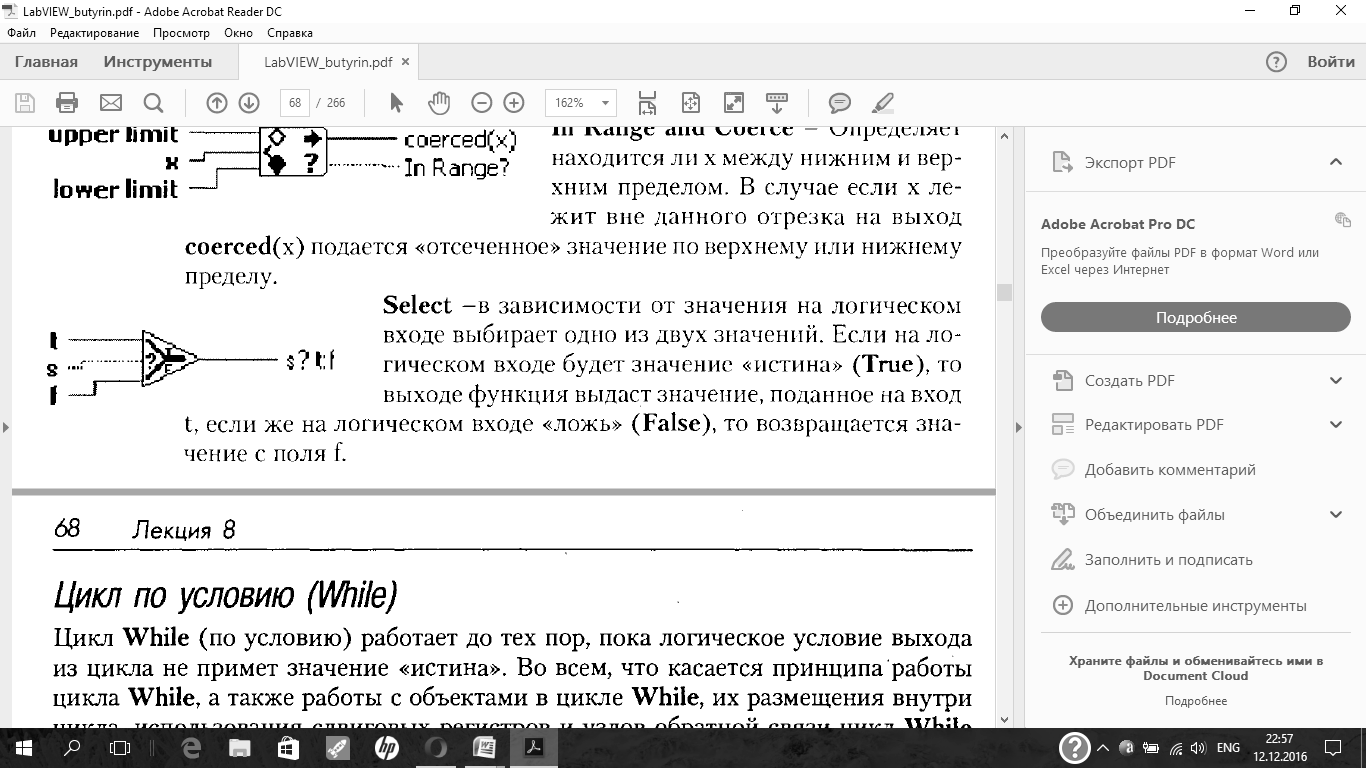
Цикл While(по условию) работает до тех пор, пока логическое условие выхода из цикла не примет значение ?истина?. Во всем, что касается принципа работы цикла While,а также работы с объектами в цикле While,их размещения внутри цикла, использования сдвиговых регистров и узлов обратной связи цикл While аналогичен циклу For.Принципиальное различие этих циклов заключается в том, что цикл For выполняется некоторое число раз, задаваемое явно через терминал общего числа итераций или задаваемое неявно как число элементов индексируемого на входе цикла массива. Цикл же Whileвыполняется неопределенное число раз, пока не будет выполнено заданное условие. В отличие от цикла Forцикл Whileвыполняется всегда. В случае если условие с самого начала выполнено, цикл выполняется 1 раз.
Элементы цикла While:
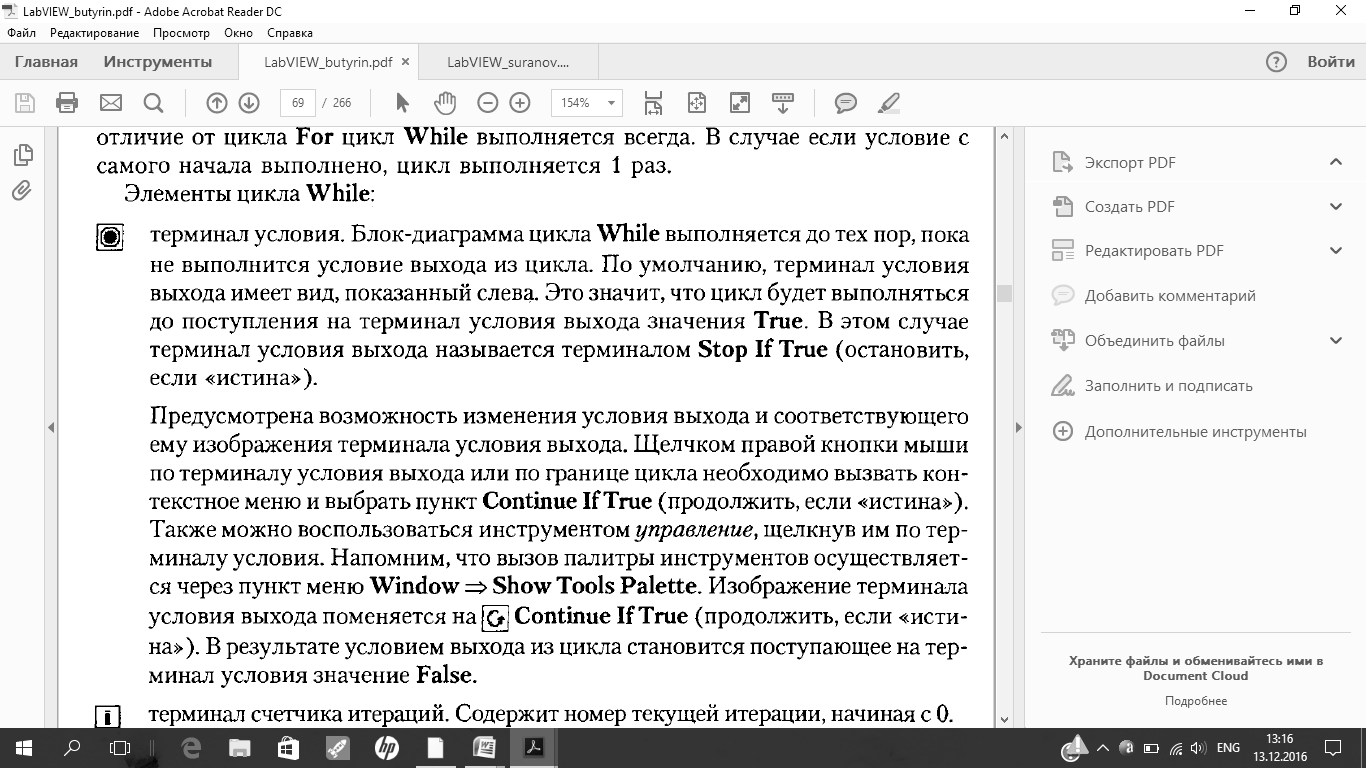
В основном автоиндексирование в цикле по условию (While)имеет тот же смысл что и в цикле с фиксированным числом итераций (For). Надо заметить, что в цикле While(в отличие от цикла for)по умолчанию автоиндексирование для массивов выключено, т.е. массив не разбирается на элементы, а поступает в каждую итерации целиком. Следует учесть, что цикл Whileможет прекратить выполнение только при заранее определенном значении логической переменной, присоединенной к терминалу условия выхода из цикла, и не зависит от размера разбираемого (Indexing)массива. Т.е. выполнение цикла может закончиться раньше или позже, чем закончатся элементы массива. Очевидно, что в первом случае из массива будут извлечены не все элементы, а во втором, при попытке считывания после конца массива, в цикл будет поступать значение по умолчанию для данного типа (0 для чисел, пустой массив, пустая строка для массивов и строк соответственно и т.д.) Пользуясь пунктом контекстного меню ?Replace?можно изменить структуру Цикл по условию (While loop)на Цикл с фиксированным числом итераций (For loop).
Структура Caseимеет две или более поддиаграммы вариантов. Только одна поддиаграмма варианта видима в данный момент времени и только одна поддиаграмма варианта работает при обращении к этой структуре. Входное значение терминала селектора структуры определяет, какая поддиаграмма будет выполняться в данный момент времени. В простейшем случае структура Caseаналогична логическим операторам (if…then…else)в текстовых языках программирования.
Элементы структуры выбора:
Для использования структуры Caseнеобходимо отметить вариант по умолчанию. Вариант по умолчанию или поддиаграмма по умолчанию выполняется, если значение терминала варианта выходит за пределы диапазона или не существуют вариантов для возможных значений терминала варианта. Щелчок правой кнопки мыши на границе структуры Caseпозволяет добавлять, дублировать, перемещать и удалять варианты (поддиаграммы), а также отмечать вариант по умолчанию.
Структура Caseдопускает использование входных и выходных терминалов данных. Терминалы входных данных доступны во всех поддиаграммах, но их использование поддиаграммой структуры необязательно. Создание выходного терминала на одной поддиаграмме приводит к его появлению на других поддиаграммах в том же самом месте границы структуры. Если хотя бы в одной поддиаграмме выходной терминал не определен, то поле этого терминала окрашивается в белый цвет, что говорит об ошибке создания структуры. Необходимо определять значения выходных терминалов во всех вариантах (поддиаграммах). Кроме того, выходные терминалы должны иметь значения совместимых типов.
Структура последовательности (Sequence)
Структура последовательности представляет собой одну или несколько поддиаграмм (кадров) которые исполняются подряд. Существуют два типа структур последовательности: структура открытой последовательности и многослойная структура.
Использование структур последовательности позволяет управлять порядком выполнения программы. В случае если вы хотите быть уверенным в том, что некоторая часть программы выполниться строго после другой части программы используйте структуру последовательности.
Структура открытой последовательности(Flat Sequence Structure)
Структура открытой последовательности выполняется кадр за кадром слева на право. Вы можете добавлять или удалять кадры из последовательности, используя контекстное меню. Когда вы добавляете или удаляете поддиаграммы, структура изменяет размер автоматически. Например, на рис. 9.4 изображена открытая структура последовательности, с помощью которой осуществляется подача двух звуковых сигналов с паузой между ними в 1 секунду. Пользуясь пунктом контекстного меню Replaceможно изменить тип структуры на многослойную.
Структура многослойной последовательности (Stacked Sequence Structure)
Структура многослойной последовательности содержит пронумерованные поддиаграммы (О, 1… и т.д.) которые выполняются по порядку. На блок диаграмме (в отличае от открытой последовательности) одновременно вы можете видеть только одну поддиаграмму. Переход от одной к другой поддиаграмме осуществляется с помощью селектора структуры последовательности. Если вы хотите сэкономить место на блок-диаграмме, используйте многослойную последовательность. От одной поддиаграммы к другой данные передаются через терминалы локальных переменных. Для того, что бы создать терминал требуется на рамке структуры вызвать контекстное меню и выбрать пункт Add Sequence Local.После того как вы присоедините источник данных к терминалу локальных переменных, в нем появляется стрелка, направленная наружу, это значит, что терминал является приемником данных. Во всех последующих терминал будет являться источникам данных и стрелка в нем будет направлена внутрь. В кадрах предшествующих кадру источника данных терминал выглядит заштрихованным, и вы не можете его использовать.
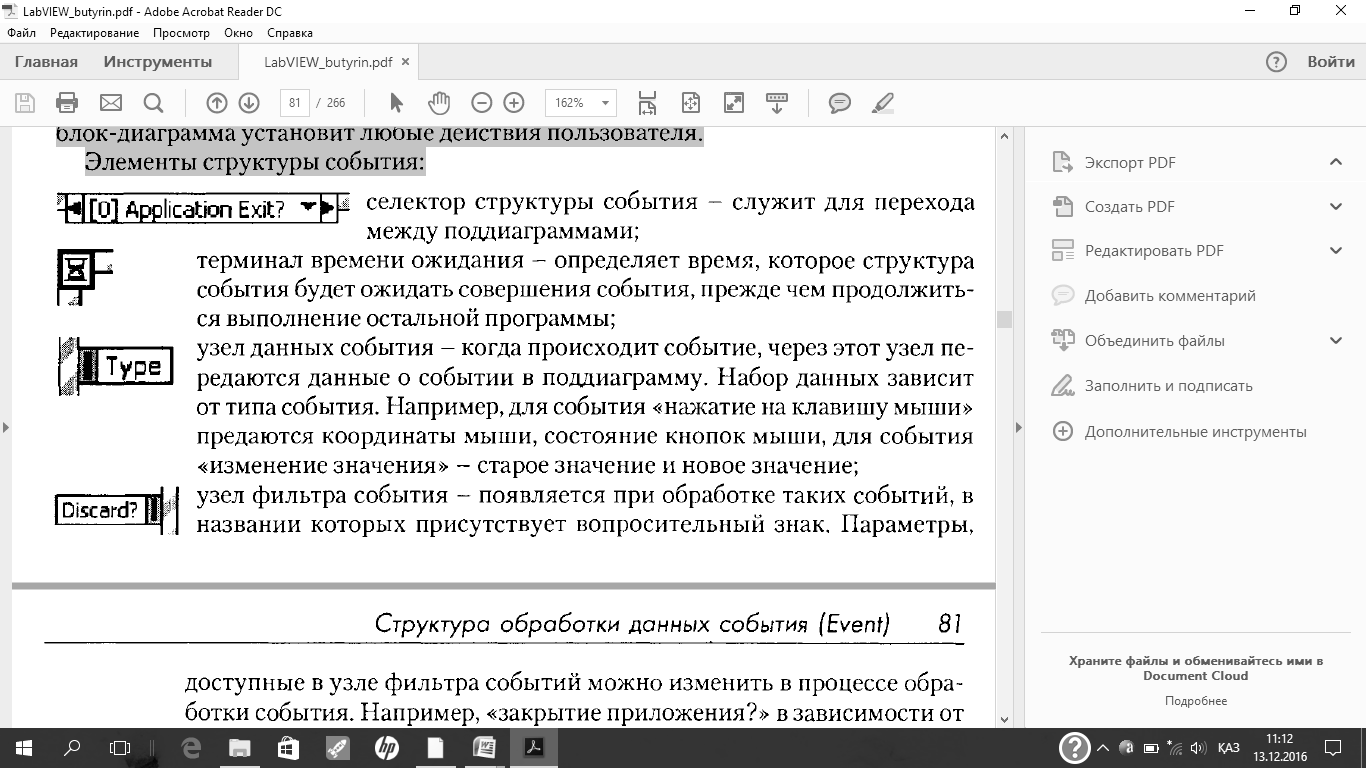
Структура события используется для синхронизации действий пользователя на лицевой панели с выполнением блок-диаграммы. Применение данной структуры позволяет выполнять определенную поддиаграмму каждый раз, когда пользователь совершает соответствующее действие (нажимает кнопку, изменяет значение элемента управления, перемещает мышь и т.д.). Без использования структуры события придется опрашивать состояние объектов лицевой панели в цикле, проверяя, не произошли ли какие-либо изменения. Опрашивание состояния объектов лицевой панели требует существенного количества процессорного времени и есть вероятность, что предполагаемые изменения будут пропущены, если они произошли слишком быстро. В этом качестве структура события позволяет избежать процесса опрашивания состояния лицевой панели для определения произведенных пользователем действий. Использование структуры событий сокращает требования программы к ресурсам процессора, упрощает код блок-диаграммы и гарантирует, что блок-диаграмма установит любые действия пользователя.
Элементы структуры события:
| Объясните способы применения операторовцикла с пред и пост условиями | №1 | 10.11 14:09:29 |
Цикл For выполняет участок программы расположенный в поддиаграмме цикла
определенное количество раз.
[N] — терминал общего числа итераций, определяет общее число итераций.
[i] — терминал счетчика итераций, содержит номер текущей итерации, начиная с 0.
Данные могут поступать в цикл For (или выходить из него) через терминалы входных/выходных данных цикла. Терминалы входных/выходных данных цикла передают данные из структур и в структуры. Они представляют собой цветные прямоугольники и располагаются на границе области цикла. Прямоугольник принимает цвет типа данных, передаваемых по терминалу. Данные выходят из цикла по его завершении. Пока цикл не выполнил все положенные итерации выходные данные получить нельзя.
Число итераций цикла For должно быть известно до начала выполнения цикла.
Имеется две возможности задать это число:
Непосредственно присоединить проводник к терминалу общего числа итераций [N]
Присоединить к одному из входных терминалов массив. В этом случае структура сама разберет массив на элементы.
Цикл For может автоматически разбирать массив на элементы на входе и собирать
из отдельных элементов массив на выходе. Это свойство называется автоиндексацией.
Цикл While(по условию) работает до тех пор, пока логическое условие выхода из цикла не примет значение истина. Во всем, что касается принципа работы цикла While,а также работы с объектами в цикле While,их размещения внутри цикла, использования сдвиговых регистров и узлов обратной связи цикл While аналогичен циклу For.Принципиальное различие этих циклов заключается в том, что цикл For выполняется некоторое число раз, задаваемое явно через терминал общего числа итераций или задаваемое неявно как число элементов индексируемого на входе цикла массива. Цикл же Whileвыполняется неопределенное число раз, пока не будет выполнено заданное условие. В отличие от цикла Forцикл Whileвыполняется всегда. В случае если условие с самого начала выполнено, цикл выполняется 1 раз.
Элементы цикла While:
В основном автоиндексирование в цикле по условию (While)имеет тот же смысл что и в цикле с фиксированным числом итераций (For). Надо заметить, что в цикле While(в отличие от цикла for)по умолчанию автоиндексирование для массивов выключено, т.е. массив не разбирается на элементы, а поступает в каждую итерации целиком. Следует учесть, что цикл Whileможет прекратить выполнение только при заранее определенном значении логической переменной, присоединенной к терминалу условия выхода из цикла, и не зависит от размера разбираемого (Indexing)массива. Т.е. выполнение цикла может закончиться раньше или позже, чем закончатся элементы массива. Очевидно, что в первом случае из массива будут извлечены не все элементы, а во втором, при попытке считывания после конца массива, в цикл будет поступать значение по умолчанию для данного типа (0 для чисел, пустой массив, пустая строка для массивов и строк соответственно и т.д.) Пользуясь пунктом контекстного меню Replaceможно изменить структуру Цикл по условию (While loop)на Цикл с фиксированным числом итераций (For loop).
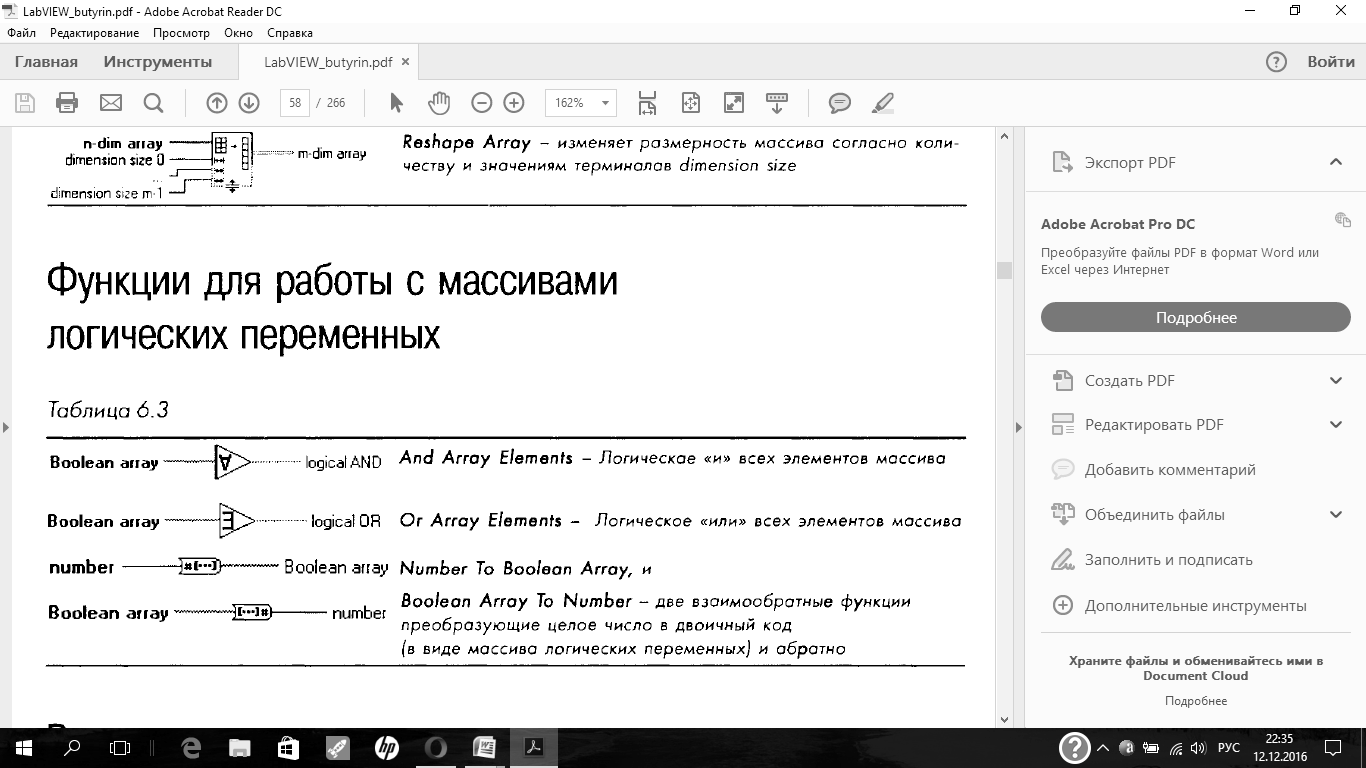
| Напишите виды логических функции LabVIEW |
В LabVIEW существуют элементы управления и индикации, которые могут иметь только два состояния (включено, выключено). Такие элементы имеют логический тип (Boolean)и расположены в палитре Controls = Boolean.Например, это кнопки и лампочки. Иначе говоря, данные логического типа могут иметь только два значения: истина (True)и ложь (False).
Механическое действие (Mechanical Action)
У логических элементов управления через контекстное меню можно установить
механическое действие (Mechanical Action),в зависимости от которого элемент управления будет по разному реагировать на нажатие мыши и считывание ВП его
значения.
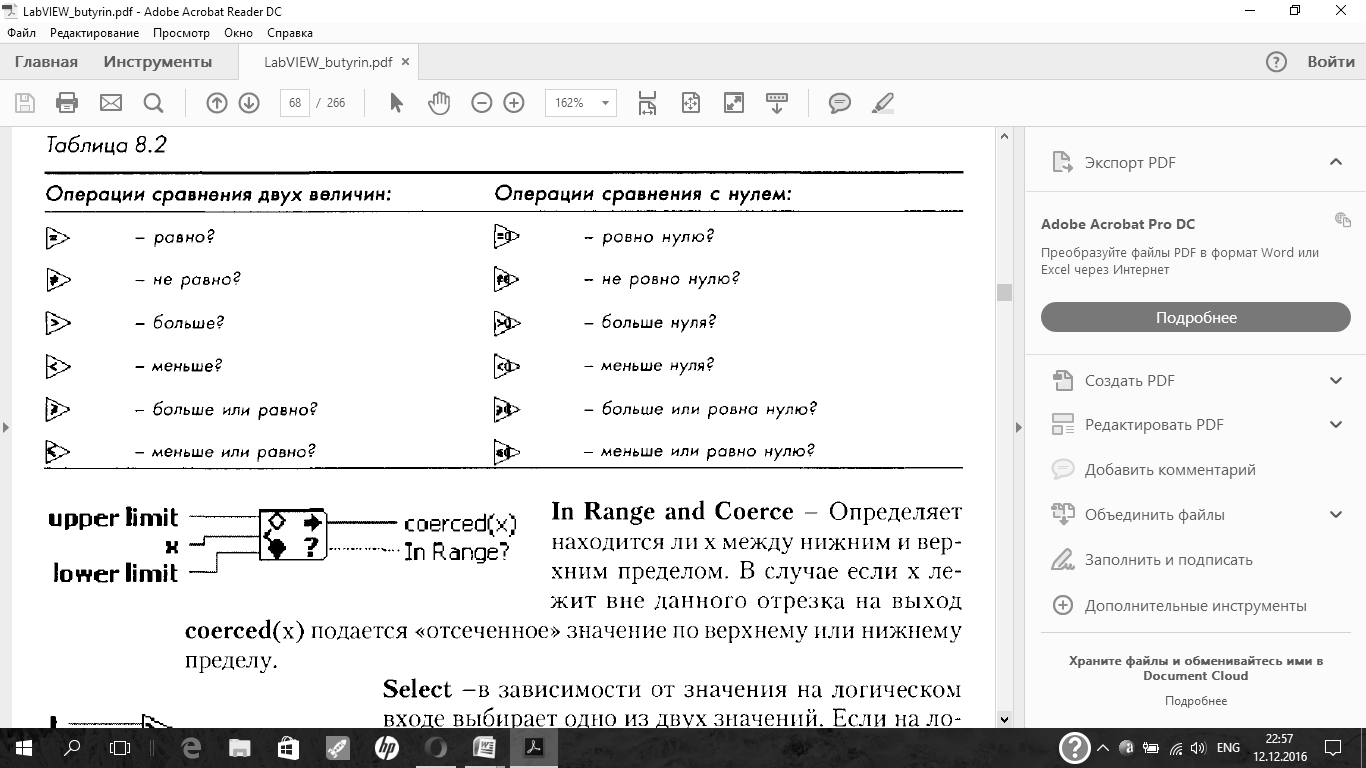
Логические функции
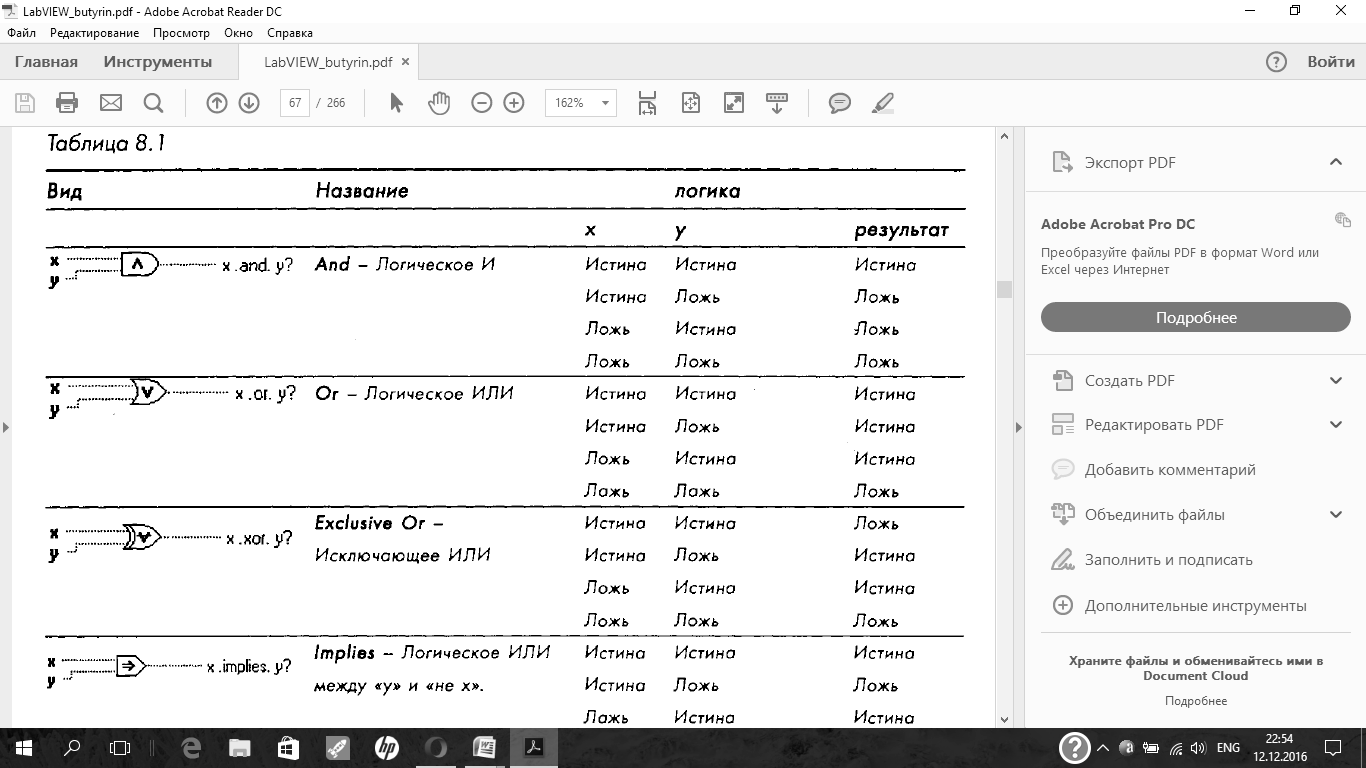
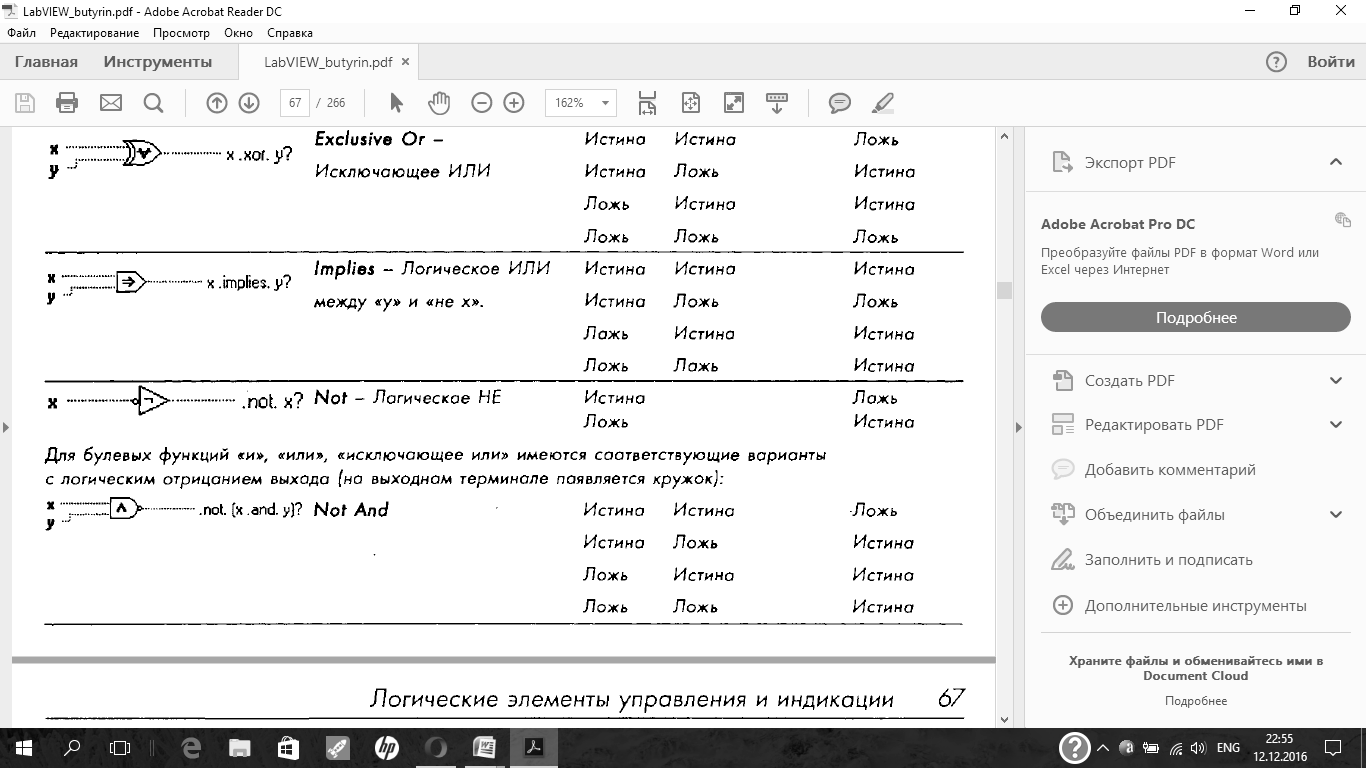
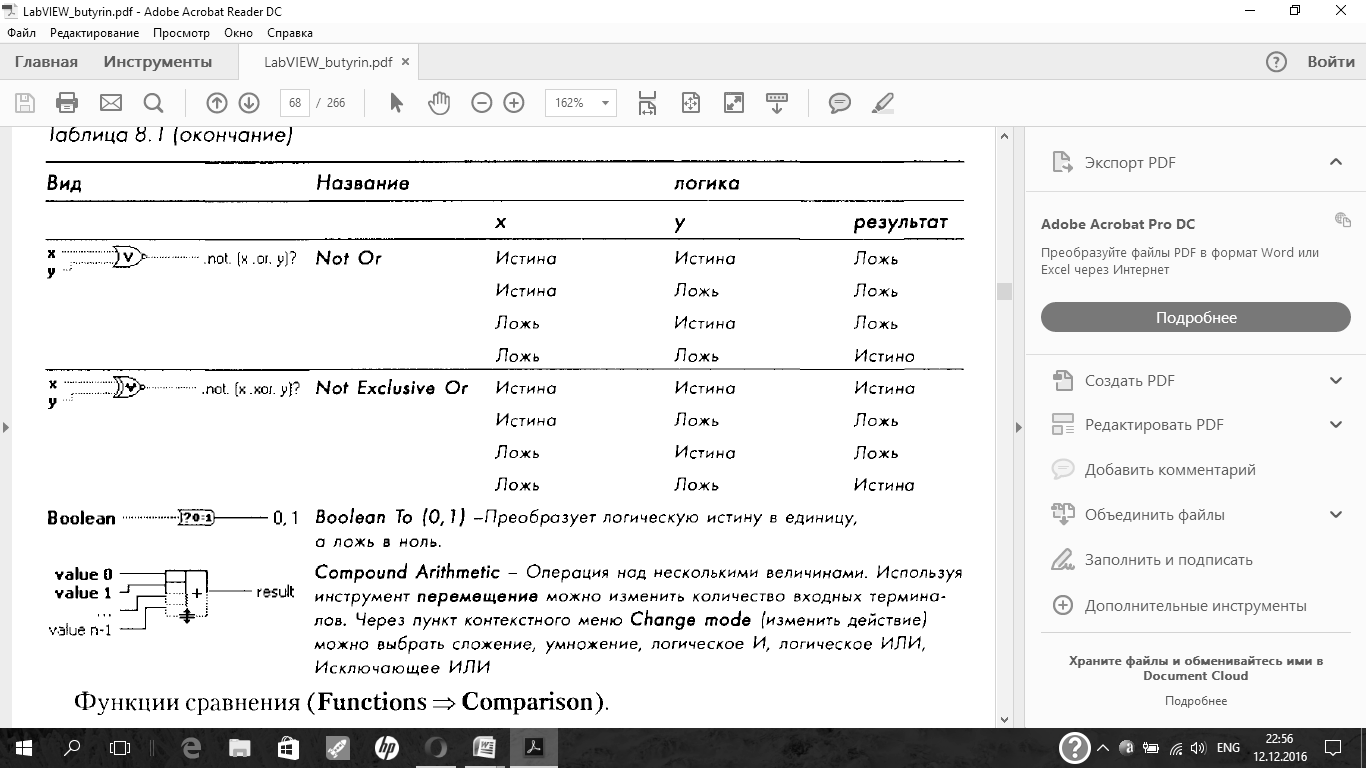
Функции сравнения (Functions = Comparison).
| Опишите cтруктуру обработки данныхсобытии |
Структура события используется для синхронизации действий пользователя на лицевой панели с выполнением блок-диаграммы. Применение данной структуры позволяет выполнять определенную поддиаграмму каждый раз, когда пользователь совершает соответствующее действие (нажимает кнопку, изменяет значение элемента управления, перемещает мышь и т.д.). Без использования структуры события придется опрашивать состояние объектов лицевой панели в цикле, проверяя, не произошли ли какие-либо изменения. Опрашивание состояния объектов лицевой панели требует существенного количества процессорного времени и есть вероятность, что предполагаемые изменения будут пропущены, если они произошли слишком быстро. В этом качестве структура события позволяет избежать процесса опрашивания состояния лицевой панели для определения произведенных пользователем действий. Использование структуры событий сокращает требования программы к ресурсам процессора, упрощает код блок-диаграммы и гарантирует, что блок-диаграмма установит любые действия пользователя.
Элементы структуры события:
Структура события работает так же, как и структура варианта. В зависимости от того, какое событие происходит, структура выполняет тот или иной вариант блок-диаграммы. Для каждого варианта можно настроить одно или несколько событий, по которым он будет выполняться. Во время выполнения кода при запуске структуры варианта LabVIEW ждет указанного события и потом выполняет соответствующую поддиаграмму. После выполнения всех записанных в этой поддиаграмме действий выполнение структуры завершается.
При создании структуры события в ней уже есть вариант, который выполняется по истечению времени ожидания (Timeout).Время ожидания в миллисекундах подключается к терминалу времени ожидания. В случае если никаких данных на этот терминал не поступает или на него подано -1, поддиаграмма этого варианта не выполняется вообще. Чтобы добавить событие и перейти к диалоговому окну редактора событий выберите в контекстном меню структуры Add EventCase. В поле Event Specifiers отображается описание текущего одного или нескольких событий для варианта, который выбран чуть выше в ниспадающем меню Event Handled for Case. Удалить или добавить событие для текущего варианта можно с помощью кнопок, расположенных левее этого поля.
В поле Event Sources представлены источники события. В них входят четыре основные категории: приложение (Application), текущий ВП (This VI), динамический источник (Dynamic), элементы управления (Controls). В поле Events производится выбор события. В табл. 10.1 представлены обрабатываемые события.
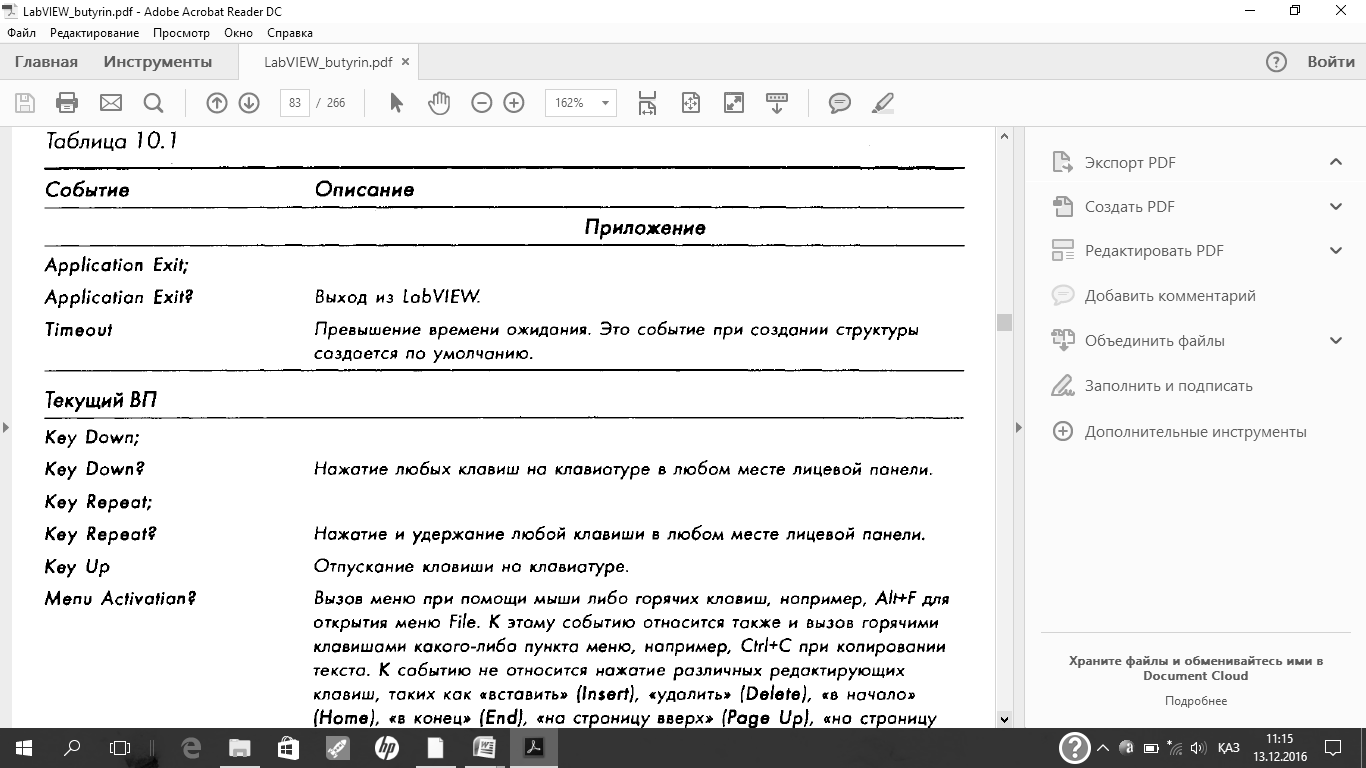
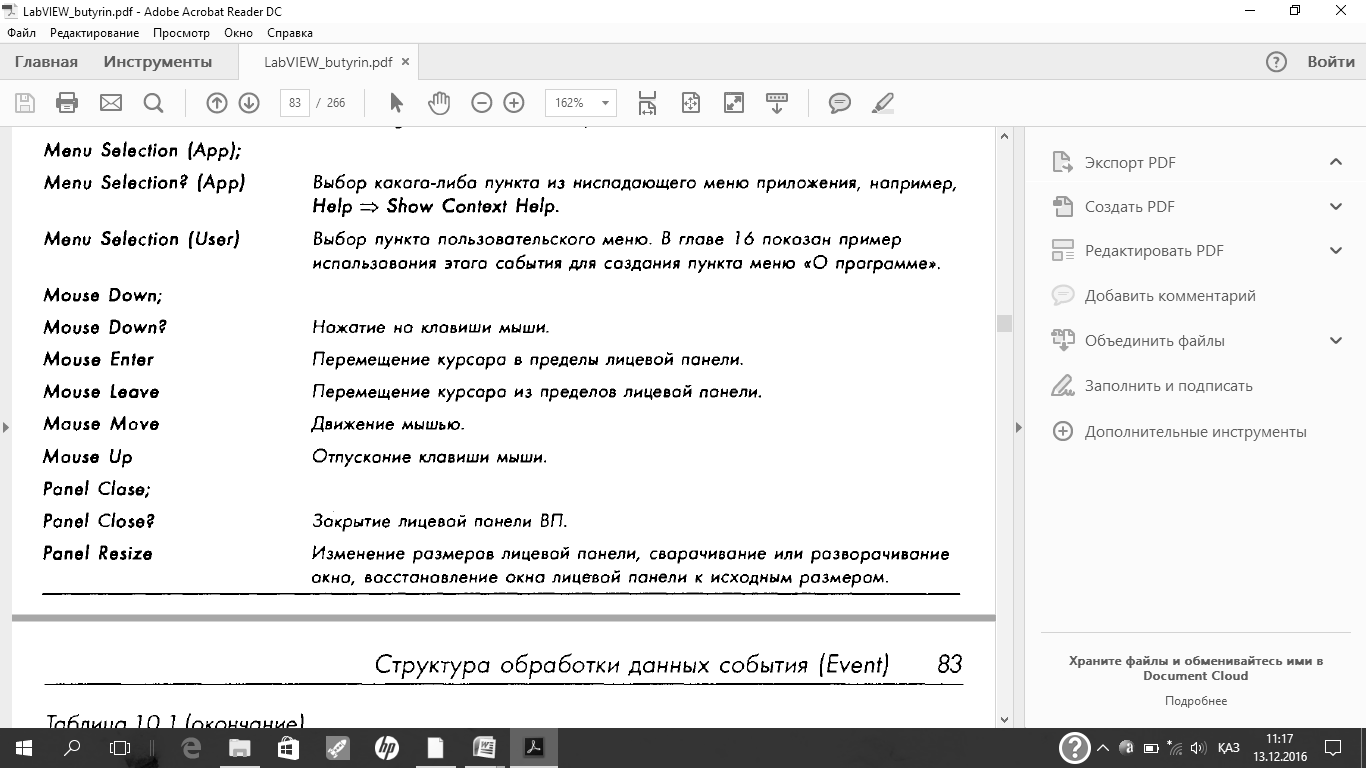
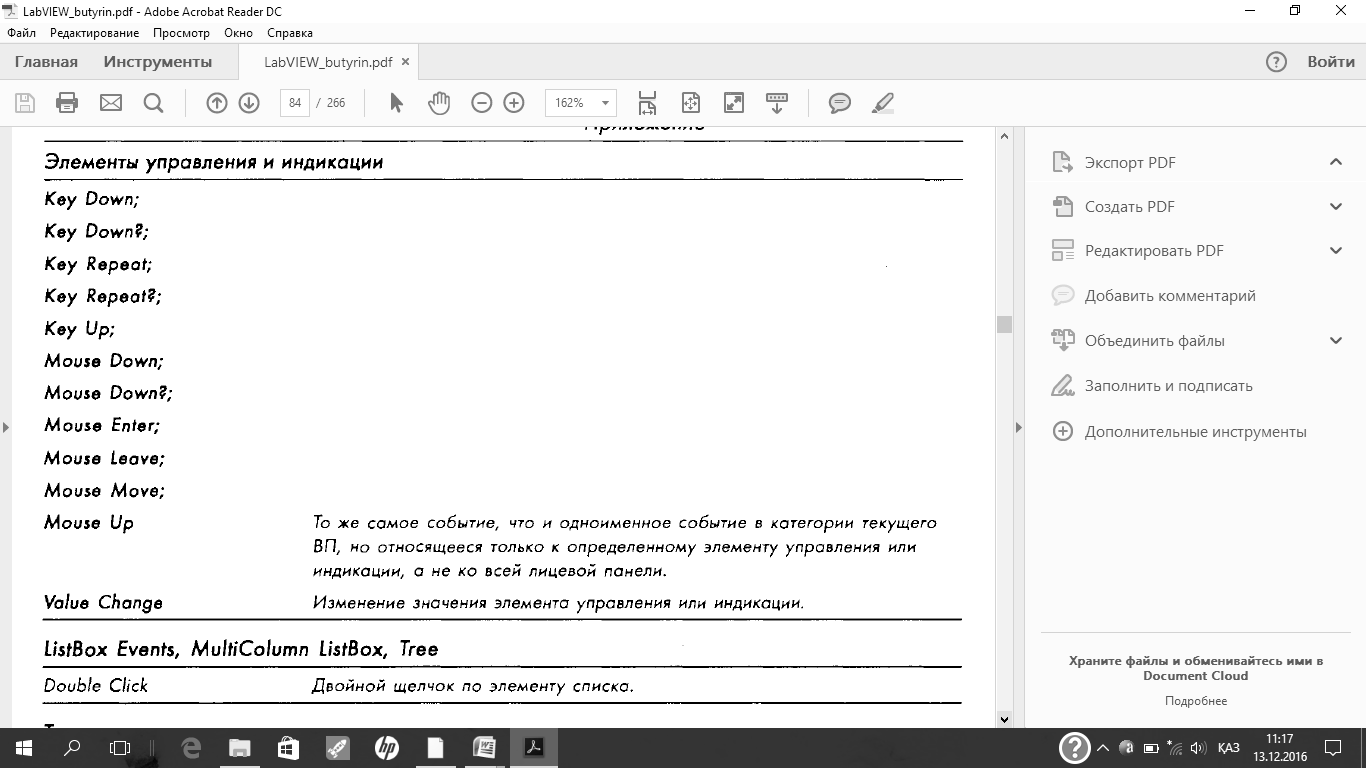
В таблице встречается двойное обозначение одного и того же события. Существует два вида событий пользовательского интерфейса — уведомление и фильтрация. Уведомляющие события показывают, что пользователь уже совершил некоторое действие, например, изменил значение элемента управления. Фильтрующие события информируют вас о действиях пользователя перед тем, как их обработает LabVIEW. Это позволяет вам каким-то образом отреагировать на действия пользователя, в том числе и отменить его действия. Для фильтрующих событий в обозначении используется знак вопроса. В обозначении уведомляющих событий знака вопроса нет.
После того как вы закончили редактирование событий, нажмите ОК.Если вам понадобится еще раз обратиться к этому окну, в контекстном меню структуры событий выберите Edit Events Handled by This Case.
Когда вы перейдете на блок-диаграмму, обратите внимание, что в каждом варианте у левого края структуры появились узлы данных события, а в случае использования фильтрующих событий — у правого края структуры появились также и узлы фильтра событий. Как было выше упомянуто, узел данных событий передает возможные параметры события в поддиаграмму варианта. В табл. 10.2 представлены некоторые параметры узла данных события.
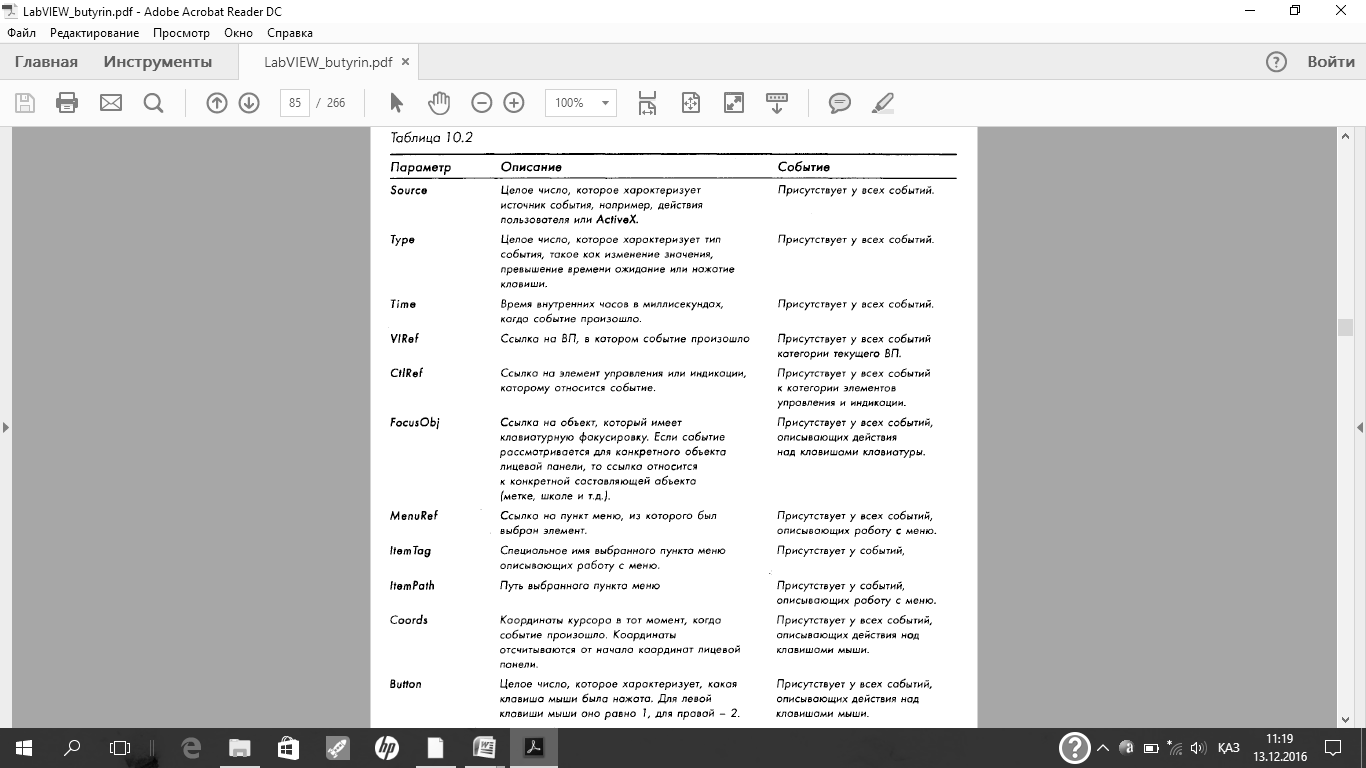
В узле данных события можно убирать лишние терминалы. Для этого просто уменьшите размер узла данных события или в контекстном меню выберите пункт Remove Element.Если вам потребуется добавить параметр, увеличьте размер узла или в контекстном меню выберите пункт Add Element.Поменять параметр, например, с параметра OldValна параметр NewValможно просто, кликнув по терминалу или выбрав в контекстном меню пункт Select Item.
Узел фильтра событий может содержать изменяемые параметры. Практически все параметры узла фильтра событий повторяют параметры узла данных события.
Однако есть и специальные параметры. К такому параметру относится параметр
Discard.
| Объясните функции работы с кластерами |
Кластеры объединяют элементы разных типов данных. Кластеры играют ту же роль, что и структуры в текстовых языках программирования.
Объединение нескольких групп данных в кластер устраняет беспорядок на блок-диаграмме и уменьшает количество полей ввода/вывода данных, необходимых подпрограмме ВП. Максимально возможное количество терминалов ввода/вывода данных ВП равно 28. Если лицевая панель содержит более 28 элементов, которые необходимо использовать в ВП, можно некоторые из них объединить в кластер и связать кластер с полем ввода/вывода данных. Как и массив, кластер может быть элементом управления или индикации, однако при этом кластер не может содержать одновременно элементы управления и индикации.
В кластере, как и в массиве, все элементы упорядочены, но обратиться по индексу к ним нельзя, необходимо сначала разделить их. Для этого предназначена функция Unbundle By Name,которая обеспечивает доступ к определенным элементам кластера по их имени.
Порядок элементов в кластере
Каждый элемент кластера имеет свой логический порядковый номер, не связанный с положением элемента в шаблоне. Первому помещенному в кластер элементу автоматически присваивается номер 0, второму элементу — 1 и так далее. При удалении элемента порядковые номера автоматически изменяются. Порядок элементов в кластере определяет то, как элементы кластера будут распределены по терминалам функций Bundle(объединения) и Unbundle(разделения) на блок-диаграмме.
Посмотреть и изменить порядковый номер объекта, помещенного в кластер, можно, щелкнув правой кнопкой мыши по краю кластера и выбрав из контекстного меню пункт Reorder Controls In Cluster.Панель инструментов и кластер примут вид, показанный на рис. 11.2.
В белом поле (4) указан текущий порядковый номер элемента, в черном (5) — новый порядковый номер. Для установки порядкового номера элемента нужно в поле ввода текста Click to setto ввести число и нажать на элемент. Порядковый номер элемента изменится. При этом корректируются порядковые номера других элементов. Сохранить изменения можно, нажав кнопку Confirmна панели инструментов. Вернуть первоначальные установки можно, нажав кнопку Cancel.
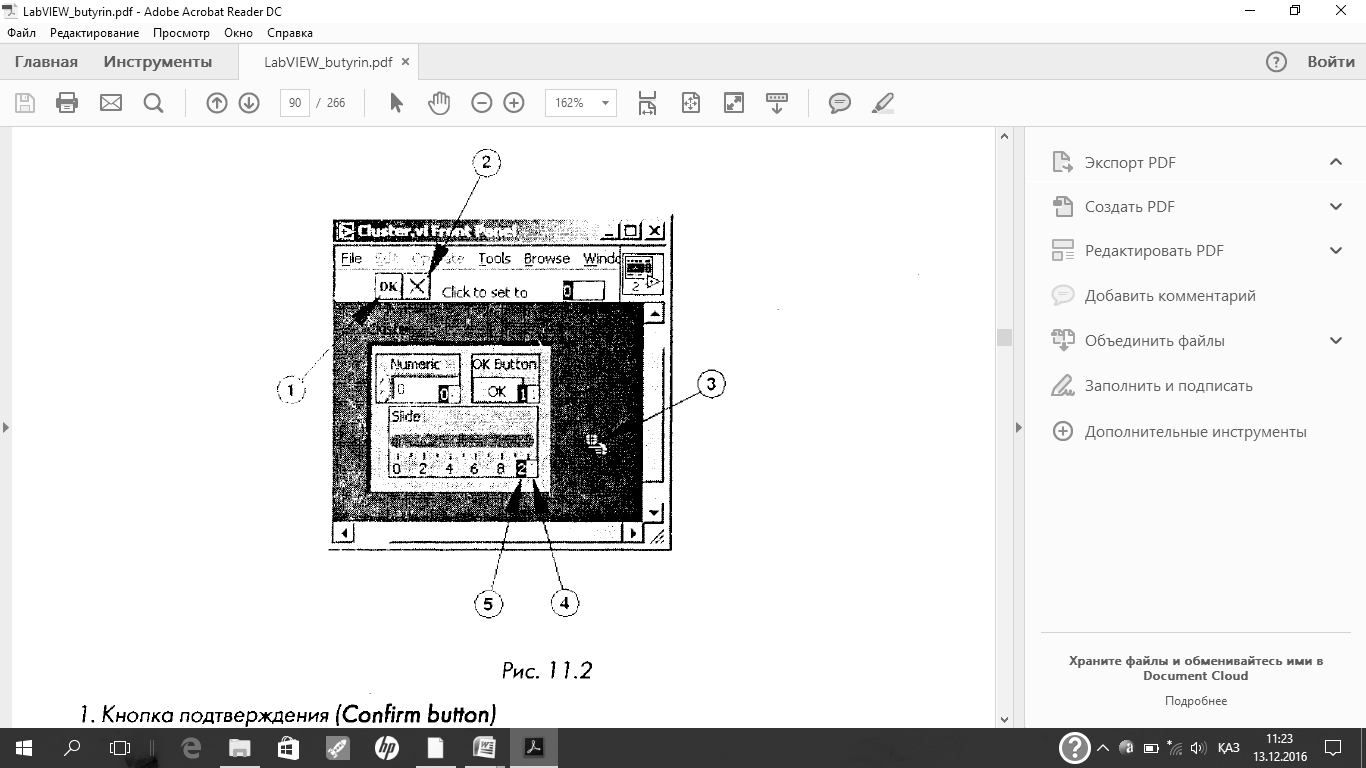
1. Кнопка подтверждения (Confirm button)
2. Кнопка отмены (Cancel button)
3. Курсор определения порядка (Cluster order cursor)
4. Текущий порядковый номер (Current order)
5. Новый порядковый номер (New order)
Соответствующие элементы, определенные в кластерах одинаковыми порядковыми номерами, должны иметь совместимые типы данных. Например, в одном кластере элемент 0 является числовым элементом управления, а элемент 1 — строковым элементом управления. Во втором кластере элемент 0 — числовой элемент индикации и элемент 1 — строковый элемент индикации, тогда кластер элементов управления корректно соединится с кластером элементов индикации.
Если изменить порядковые номера элементов в одном из кластеров, проводник данных между кластерами будет разорван, так как типы данных элементов кластеров не будут соответствовать друг другу.
Создание кластера констант
На блок-диаграмме можно создать кластер констант, выбрав в палитре Functions
= Clusterшаблон Cluster Constantи поместив в него числовую константу или другой объект данных, логический или строковый.
Если на лицевой панели кластер уже существует, то кластер констант на блок-диаграмме, содержащий те же элементы, можно создать, просто перетащив кластер с лицевой панели на блок-диаграмму или, щелкнув правой кнопкой мыши на кластере, выбрать из контекстного меню пункт Create = Constant.
Функции работы с кластерами
Для создания и управления кластерами используются функции, расположенные на палитре Functions = Cluster.Функции Bundle и Bundle by Nameиспользуются для
сборки и управления кластерами. Функции Unbundle и Unbundle by Nameиспользуются для разборки кластеров.
Эти функции также можно вызвать, щелкнув правой кнопкой мыши по терминалу данных кластера и выбрав из контекстного меню подменю Cluster Tools.Функции Bundle и Unbundleавтоматически содержат правильное количество полей ввода/вывода данных. Функции Bundle by Name и Unbundle by Nameв полях ввода/вывода данных содержат имя первого элемента кластера.
Сборка кластеров
Для сборки отдельных элементов в кластер используется функция Bundle.Эта же функция используется для изменения данных в элементе уже существующего кластера. Инструмент перемещение используется для добавления полей ввода данных, для этого также можно щелкнуть правой кнопкой по полю ввода данных и выбрать из контекстного меню пункт Add Input.На рис. 11.3 собирается кластер из трех элементов: численного, строкового и булевого типа.
На поле ввода данных cluster(которое находиться наверху функции) можно подать уже имеющийся кластер, в этом случае узел Bundleвыполняет функцию заменызначений всех или некоторых элементов кластера. Количество полей ввода данных функции должно соответствовать количеству элементов во входящем кластере. Например, на рис. 11.4 показано изменение значений двух полей кластера.
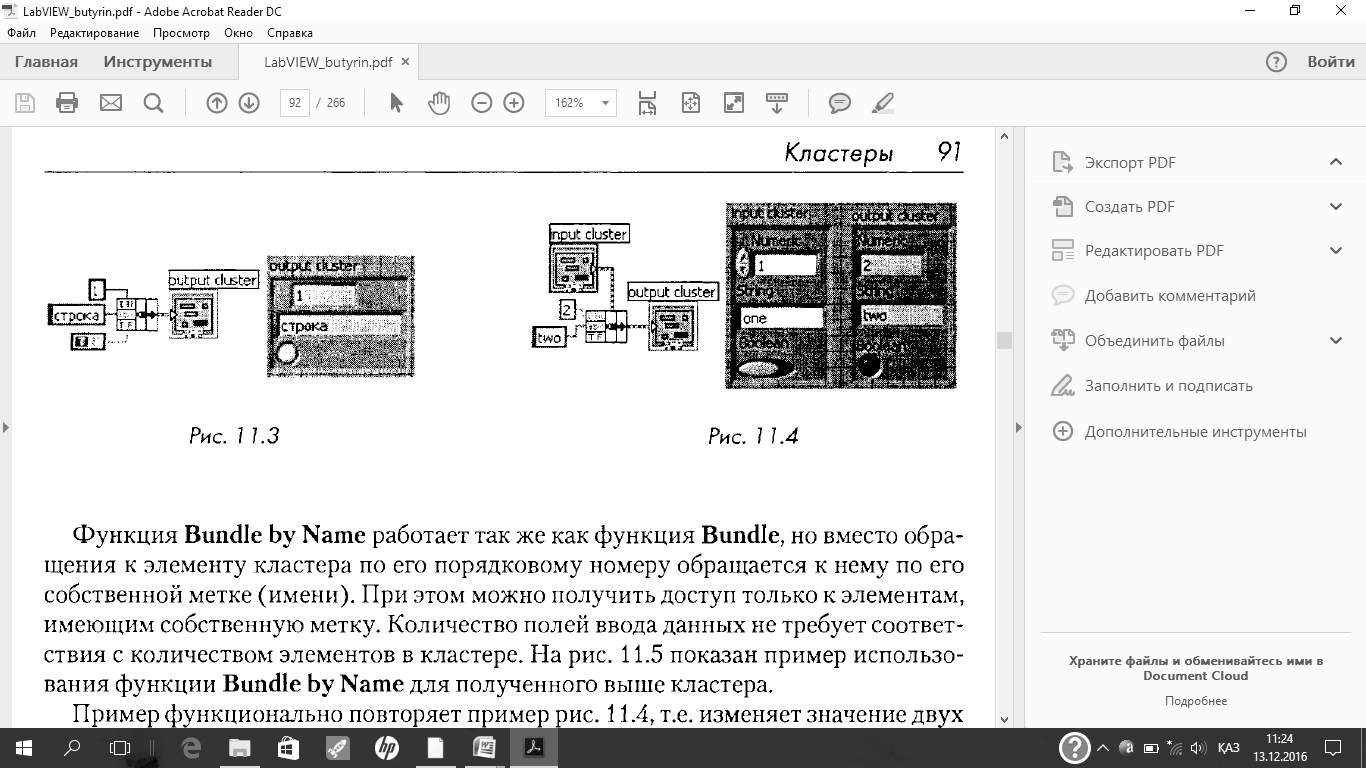
Функция Bundle by Nameработает так же как функция Bundle,но вместо обращения к элементу кластера по его порядковому номеру обращается к нему по его собственной метке (имени). При этом можно получить доступ только к элементам, имеющим собственную метку. Количество полей ввода данных не требует соответствия с количеством элементов в кластере. На рис. 11.5 показан пример использования функции Bundle by Nameдля полученного выше кластера.
Пример функционально повторяет пример рис. 11.4, т.е. изменяет значение двух элементов в кластере, но обращение к элементам происходит по их именам. С помощью инструмента управление можно щелкнуть по полю ввода данных терминала и выбрать желаемый элемент из выпадающего меню. Можно также щелкнуть правой кнопкой мыши по полю ввода данных и выбрать элемент в разделе контекстного меню Select Item.
Использовать функцию Bundle by Nameследует при работе со структурами данных, которые могут меняться в процессе работы. Чтобы добавить новый элемент в кластер или изменить порядковый номер элемента, нет необходимости вновь подключать функцию Bundle by Name,так как имя элемента все еще действительно.
Разделение кластера
Функция Unbundleиспользуется для разбиения кластеров на отдельные элементы. Функция Unbundle by Nameиспользуется для выделения из кластера элементов по определенному имени. Количество полей вывода данных не зависит от количества элементов в кластере.

С помощью инструмента управление можно щелкнуть по полю вывода данных и выбрать желаемый элемент из контекстного меню. Можно также щелкнуть правой кнопкой мыши по полю вывода данных и выбрать из контекстного меню пункт Select Item.
Так, функция Unbundleпри использовании кластера, показанного на рис. 11.6, имеет три поля вывода данных, которые соотносятся с тремя элементами кластера.
Необходимо знать порядок элементов в кластере для корректного сопоставления элементов имеющих одинаковый тип (как Thermometer и Numericв данном примере). Если использовать функцию Unbundle by Name,то полей вывода данных может быть произвольное количество, и обращаться к отдельным элементам можно в произвольном порядке.
Масштабирование кластера
Каждый элемент в кластере имеет свой масштабный коэффициент. Предположим, что исходные данные, значения давления, скорости потока и температуры были получены с соответствующих датчиков напряжения. Затем ВП масштабирует эти значения и выдает фактические значения физической величины.
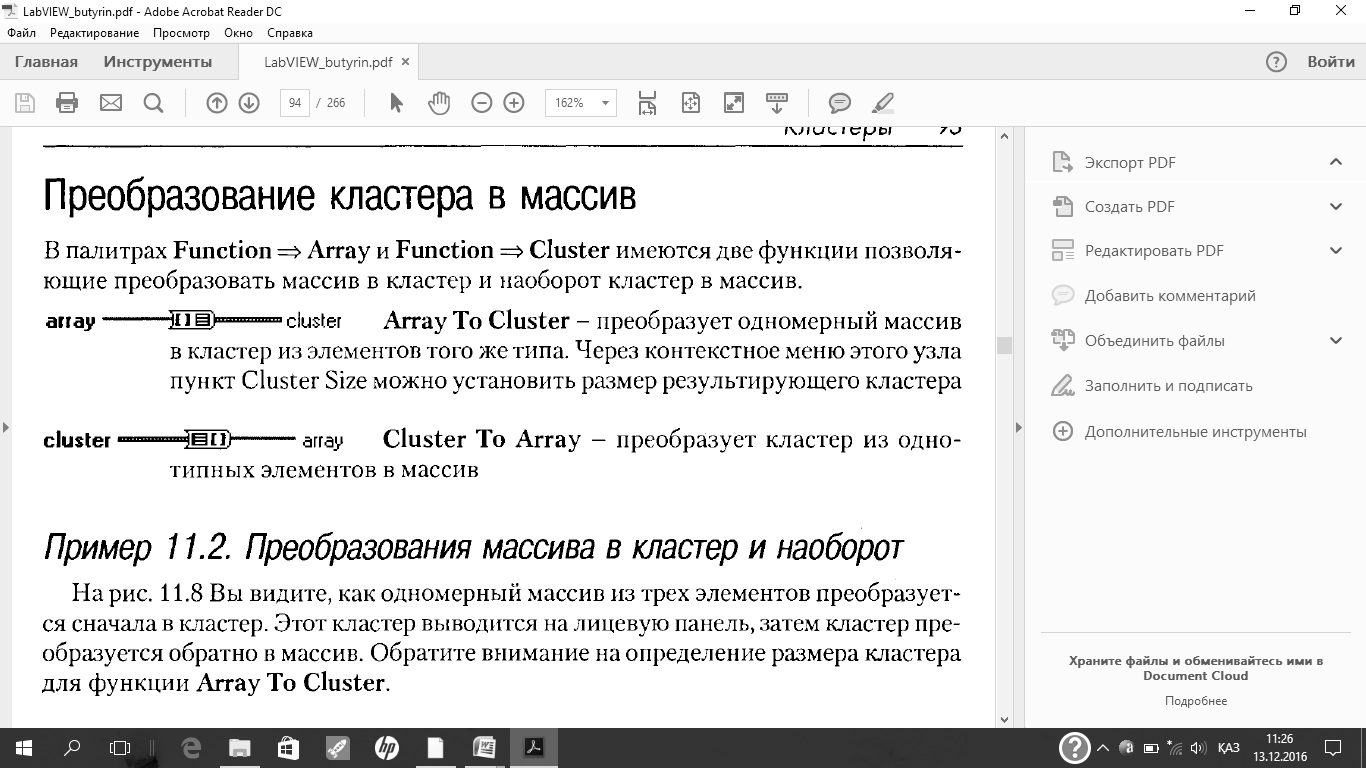
Преобразование кластера в массив
В палитрах Function = Array и Function=$ Clusterимеются две функции позволяющие преобразовать массив в кластер и наоборот кластер в массив.
Кластеры ошибок
Ошибки при работе над любым проектом неизбежны. Поэтому при создании проекта важным этапом является отладка приложения, обработка ошибок. Обработка ошибок подразумевает сопоставление какого-либо действия возможным непланируемым событиям, например, вывода диалогового окна. В Lab VIEW не реализована автоматическая обработка ошибок. Это сделано для того, чтобы можно было самостоятельно выбирать метод, которым обрабатываются ошибки. Например, если для ВП истекло время ожидания ввода/вывода, можно сделать так, чтобы не прекращалась работа всего приложения. Можно также заставить ВП повторить попытку через некоторое время. Процесс обработки ошибок в Lab VIEW происходит на блок-диаграмме.
Существует два способа возврата ошибок в ВП и функциях: с помощью числа,
обозначающего код ошибки и с помощью кластера ошибок. Как правило, функции используют число — код ошибки, а ВП принимают на вход и выдают на выходе информацию об ошибках в виде кластера.
Обработка ошибок в Lab VIEW также построена на модели поточного программирования. Как и другие данные, информация об ошибках проходит через ВП. Для передачи информации об ошибках через ВП необходимо использовать входной и выходной кластеры ошибок, а также включить в конце ВП обработчик ошибок для определения того, были ли сбои в процессе работы ВП.
При выполнении ВП Lab VIEW следит за появлением ошибок, и, как только где-нибудь
происходит сбой, составляющие части ВП перестают выполняться и только передают ошибку дальше, на выход. Для обработки появляющихся в ВП ошибок в конце потока выполнения обычно используется показанный на рис. 11.9 простой обработчик ошибок
Simple Error Handler. Simple Error Handlerнаходится на палитре Functions = Tune and Dialog.
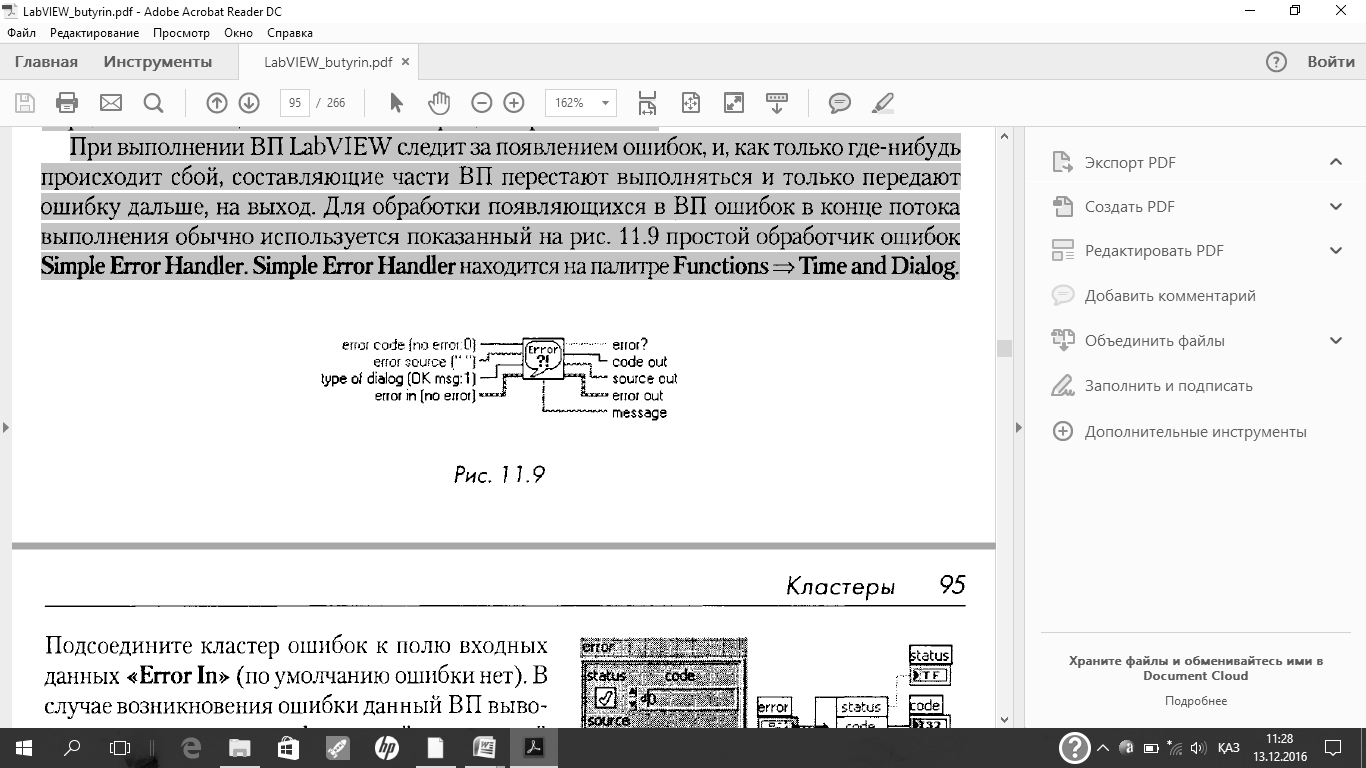
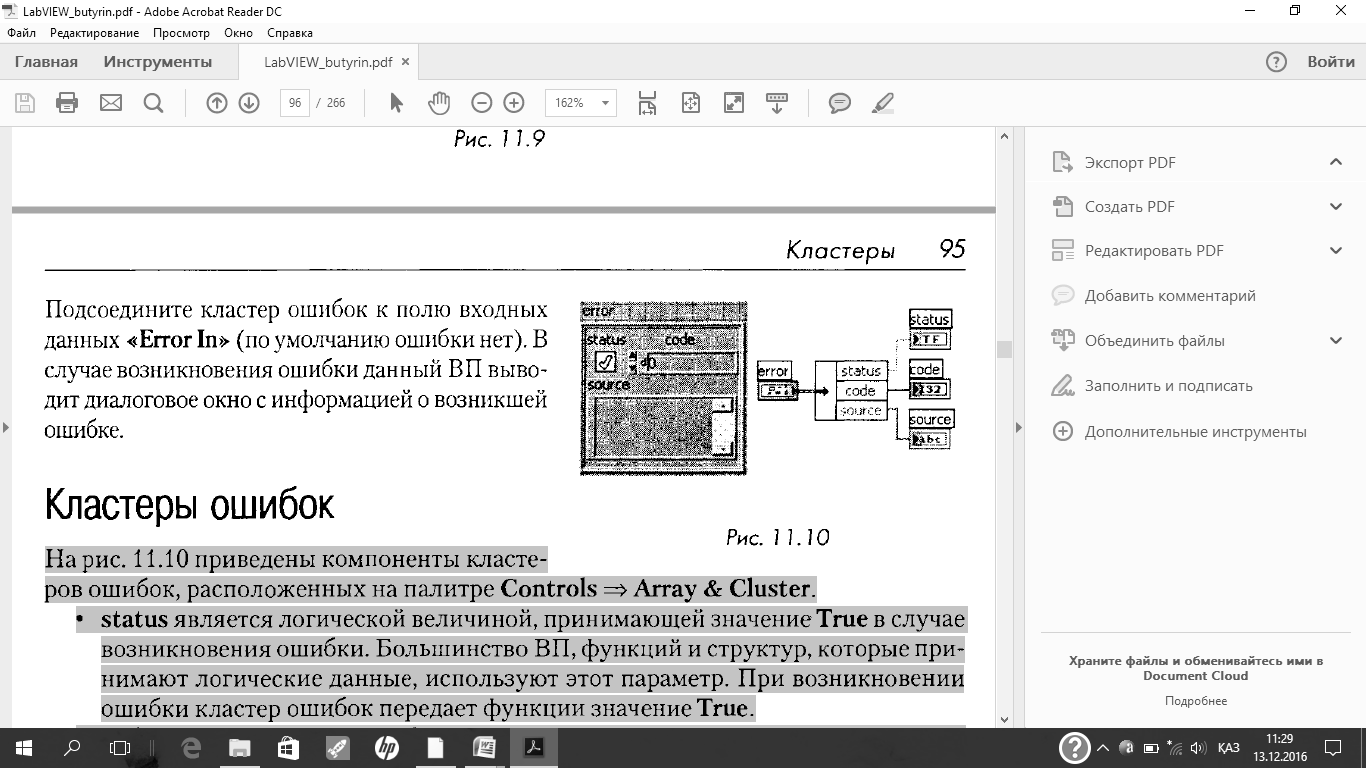
Подсоедините кластер ошибок к полю входных данных Error In(по умолчанию ошибки нет). В случае возникновения ошибки данный ВП выводит диалоговое окно с информацией о возникшей ошибке.
На рис. 11.10 приведены компоненты кластеров ошибок, расположенных на палитре Controls = ArrayCluster.
Statusявляется логической величиной, принимающей значение Trueв случае возникновения ошибки. Большинство ВП, функций и структур, которые принимают логические данные, используют этот параметр. При возникновении ошибки кластер ошибок передает функции значение True.
• codeявляется целым 32-х битным числом со знаком, которое соответствует ошибке. В случае если statusимеет значение False,a code отличен от нуля, то, скорее всего, это предупреждение, а не фатальная ошибка.
• sourceявляется строкой, которая определяет место возникновения ошибки. Для создания входа и выхода ошибок в подпрограммах ВП используются кластеры ошибок из элементов управления и индикации.
| Напишите способы работы с графическимпредставлением данных |
В LabVIEW имеются разнообразные и достаточно гибкие средства для графического представления данных. Можно использовать различные графики, на которых можно отображать одну или несколько кривых, настроить цвет, тип представления, масштаб шкал и т.д
.
График диаграмм
График диаграмм (Waveform Chart)-специальный элемент индикации в виде одного и более графиков. График диаграмм расположен на палитре Controls = Graph. График диаграмм использует три различных режима отображения данных: strip chart, scope chart и sweep chart(см. рис. 12.2). Режим по умолчанию — strip chart.
Задание режима осуществляется щелчком правой клавишей мыши по диаграмме и выбором пункта Advanced = Update Modeиз контекстного меню. Режим stripchart представляет собой экран, прокручиваемый слева направо, подобно бумажной ленте. Режимы scope chart и sweep chartподобны экрану осциллографа и отличаются большей скоростью отображения данных по сравнению с strip chart.В режиме scope chartпо достижении правой границы поле графика очищается, и заполнение диаграммы начинается с левой границы. Режим sweep chart, в отличие от режима scope chart,не очищает поле графика, а отделяет новые данные от старых вертикальной линией — маркером.
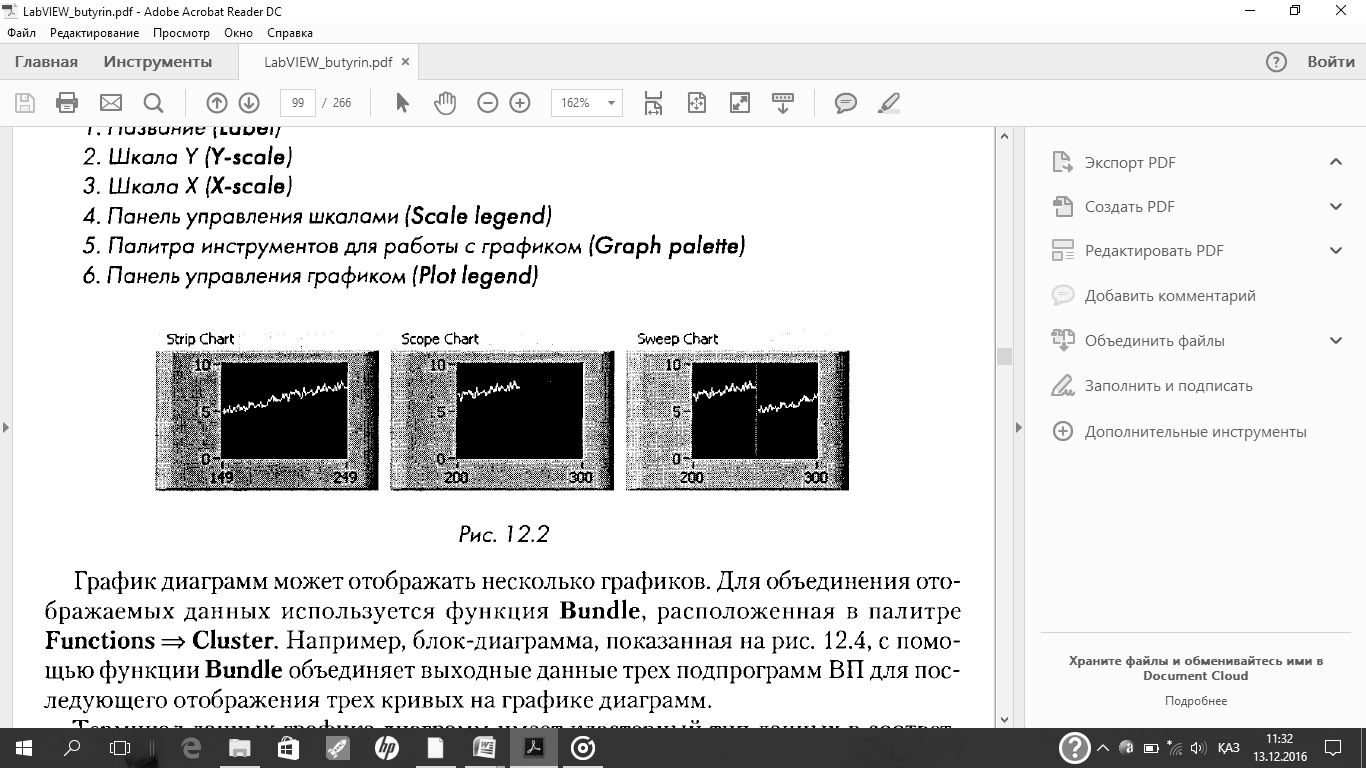
График диаграмм может отображать несколько графиков. Для объединения отображаемых данных используется функция Bundle,расположенная в палитре Functions = Cluster.Терминал данных графика диаграмм имеет кластерный тип данных в соответствии с полем вывода функции Bundle.Для увеличения количества полей ввода данных функции Bundleнеобходимо с помощью инструмента перемещение изменить ее размер.
Имеется два типа отображения данных Stack Plots(кривые расположены друг под другом) и Overlay Plots(все кривые на одном графике), выбрать требуемый тип можно через контекстное меню.
График осциллограмм и двухкоординатный график осциллограмм
График осциллограмм (Waveform Graph)и двухкоординатный график осциллограмм (XY Graph)также расположены на палитре Controls =? Graph.График осциллограмм отображает только однозначные функции, такие как у =f(x), с точками, равномерно распределенными по оси X. Двухкоординатный график осциллограмм отображает любой наборточек, будь то равномерно распределенная выборка или нет.
Для изображения множества осциллограмм необходимо изменить размер панели Plot legend.График множества осциллограмм используется с целью экономии пространства на лицевой панели и для сравнения осциллограмм данных между собой. График осциллограмм и двухкоординатный график осциллограмм автоматически поддерживают режим отображения множества осциллограмм.
Одиночный график осциллограмм
Одиночный график осциллограмм работает с одномерными массивами и представляет данные массива в виде точек на графике, с приращением по оси X равным 1 и началом в точке х = 0. Графики также отображают кластеры, с установленным начальным значением х, Дд: и массивом данных по шкале у.
График множества осциллограмм
График множества осциллограмм работает с двумерными массивами данных, где каждая строка массива есть одиночная осциллограмма данных и представляет данные массива в виде точек на графике, с приращением по оси X равным 1 и началом в точке х = 0.
Одиночные двухкоординатные графики осциллограмм
Одиночный двухкоординатный график осциллограмм работает с кластерами, содержащими массивы х и у. Двухкоординатный график осциллограмм также воспринимает массивы точек, где каждая точка является кластером, содержащим значения по шкалам х и у.
Двухкоординатные графики множества осциллограмм
Двухкоординатные графики множества осциллограмм работают с массивами осциллограмм, в которых осциллограмма данных является кластером, содержащим массивы значений х и у. Двухкоординатные графики множества осциллограмм
воспринимают также массивы множества осциллограмм, где каждая осциллограмма представляет собой массив точек. Каждая точка — это группа данных, содержащая значения по х и у.
Графики интенсивности
Графики и таблицы интенсивности (Intensity graphs and charts)удобны для представления двумерных данных. Например, для представления топографии местности, где амплитудой является высота над уровнем моря.
| Перечислите функции работы со строками |
Строки представляют собой некоторый набор символов. Этот набор может быть привычным для чтения текстом. А может быть и специальным кодом. В первом случае строка на экране отображается в том же виде, в котором она записана. Во втором случае на экране отображается то, что было закодировано (например, знак табуляции или знак абзаца). Строки используются при решении следующих наиболее распространенных задач:
• Вывод на экран или принтер текстовых сообщений.
• Преобразование различных типов данных в строки и наоборот.
• Сохранение различных типов данных в файл. Обычно требуется сохранить числовые данные. Перед записью в файл числовые данные необходимо преобразовать в строки.
• Выбор входных данных функций, которые не могут быть представлены каким-либо типом данных и не имеют своего. Например IP адрес. В некоторых случаях путь к файлам и папкам также представляется строками.
• Использование сообщений в диалоговых окнах.
На лицевой панели строки появляются в виде таблиц, полей ввода текста и меток.
Функции работы со строками
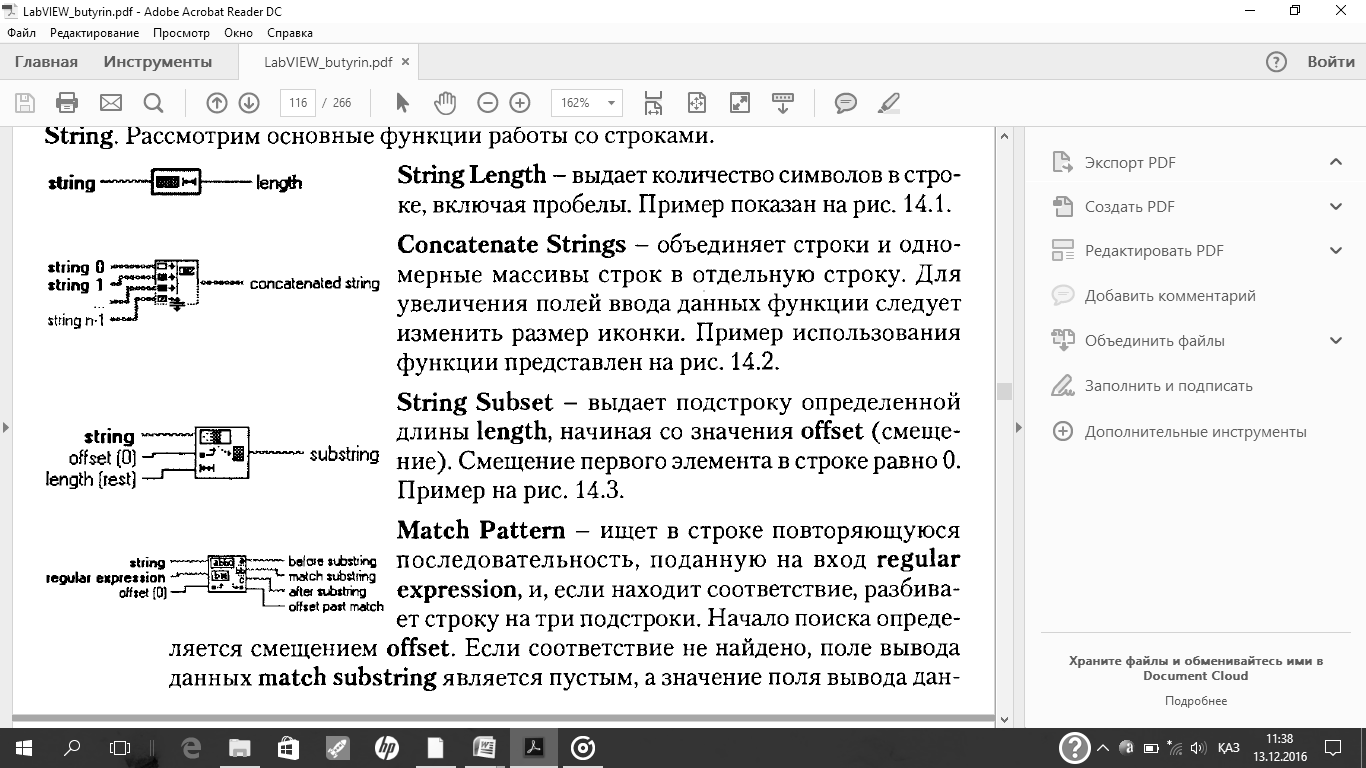
Для редактирования строк и управления ими на блок-диаграмме следует пользоваться функциями обработки строк, расположенными в палитре Functions =String.Рассмотрим основные функции работы со строками.
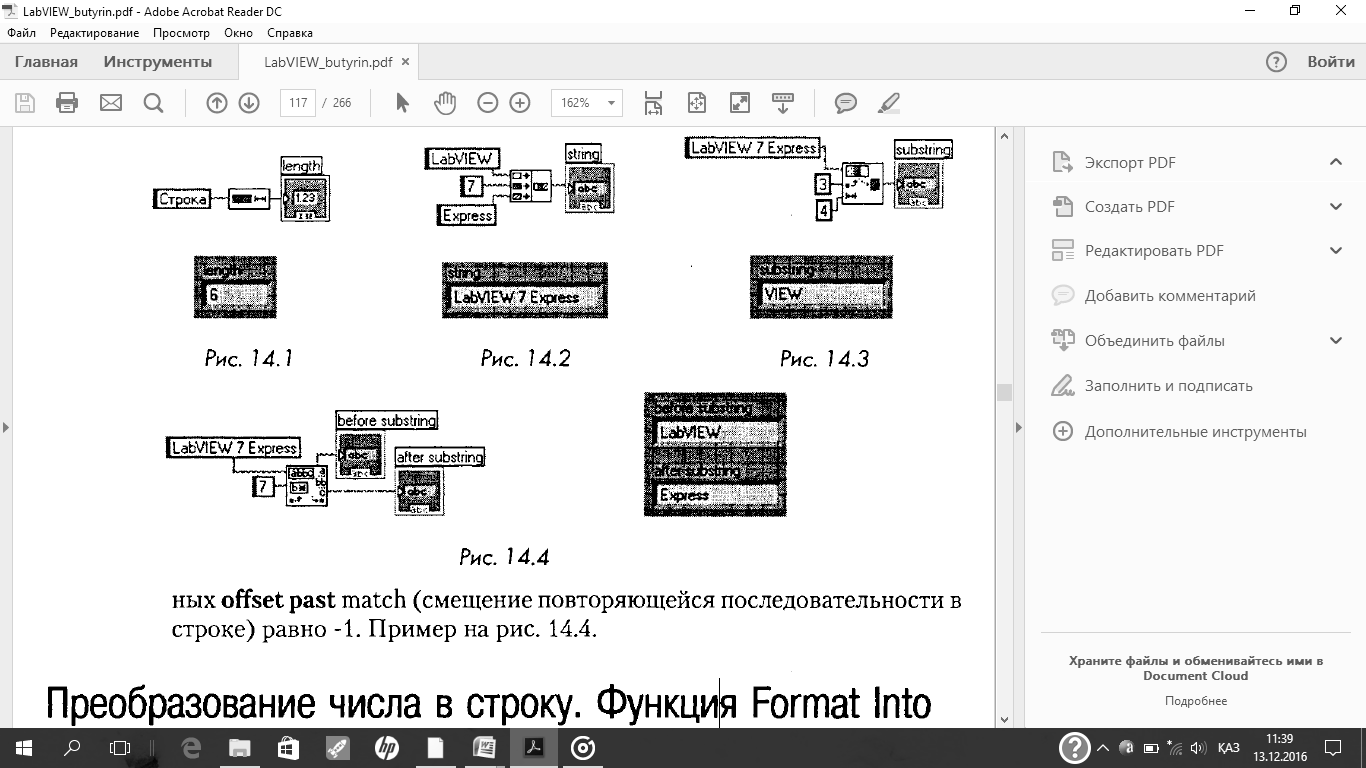
Функция Format Into Stringпреобразует данные различных типов в строку.
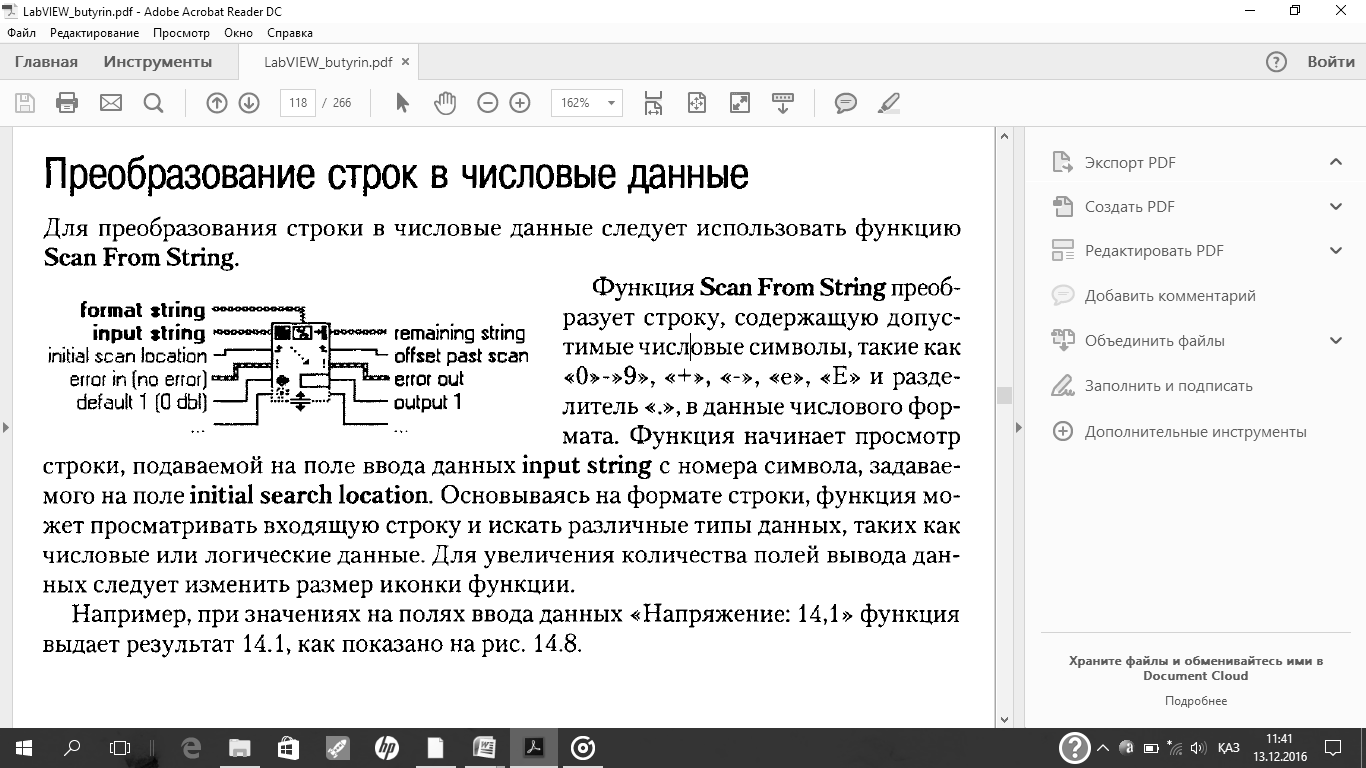
| Объясните функции работы с файлами |
Функции файлового ввода/вывода производят операции с файлами записи и считывания данных. Функции файлового ввода/вывода расположены в палитре Functions = File I/Oи предназначены для:
• Открытия и закрытия файла.
• Считывания и записи из файла и записи данных в файл.
• Считывания и записи данных в виде таблицы символов.
• Перемещения и переименования файлов и каталогов.
• Изменения характеристик файла.
• Создания, изменения и считывания файлов конфигурации
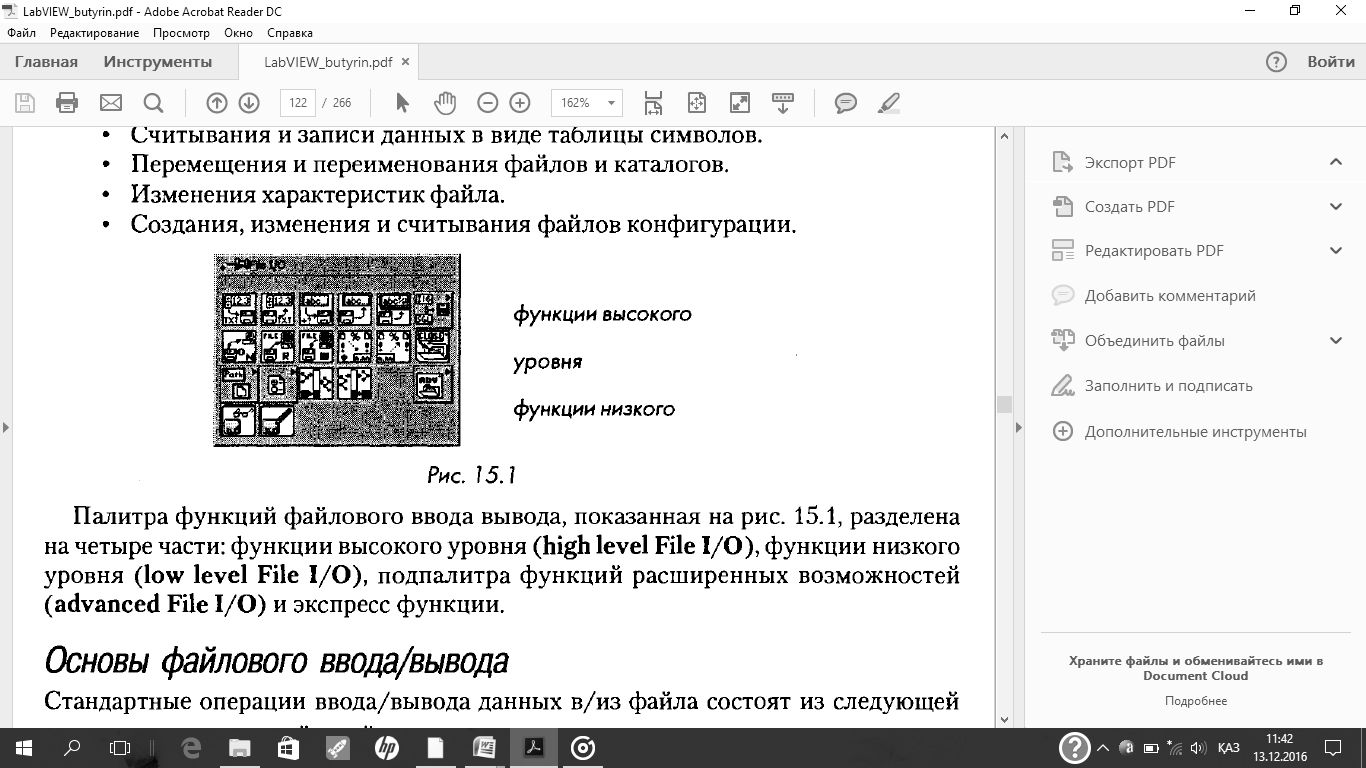
Функции файлового ввода/вывода низкого уровня
Функции файлового ввода/вывода низкого уровня расположены в средней строке палитры Functions = File I/O.Дополнительные функции работы с файлами (Advanced File I/O)расположены в палитре Functions = File I/O = Advanced File Functionsи предназначены для управления отдельными операциями над файлами. Функции файлового ввода/вывода низкого уровня используются для создания нового или обращения к ранее созданному файлу, записи и считывания данных и закрытия файла. Функции низкого уровня работы с файлами поддерживают все операции, необходимые при работе с файлами. Для осуществления основных операций файлового ввода/вывода используются следующие ВП и функции:
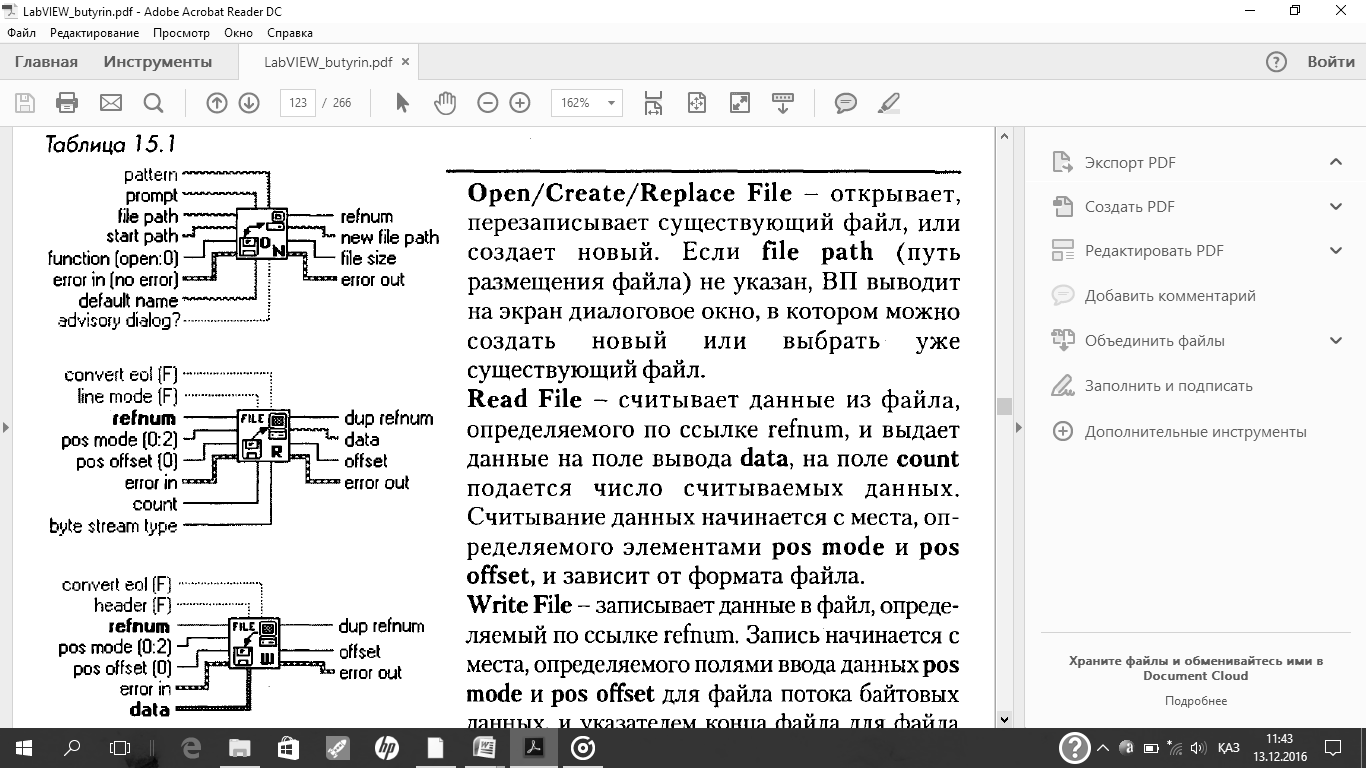
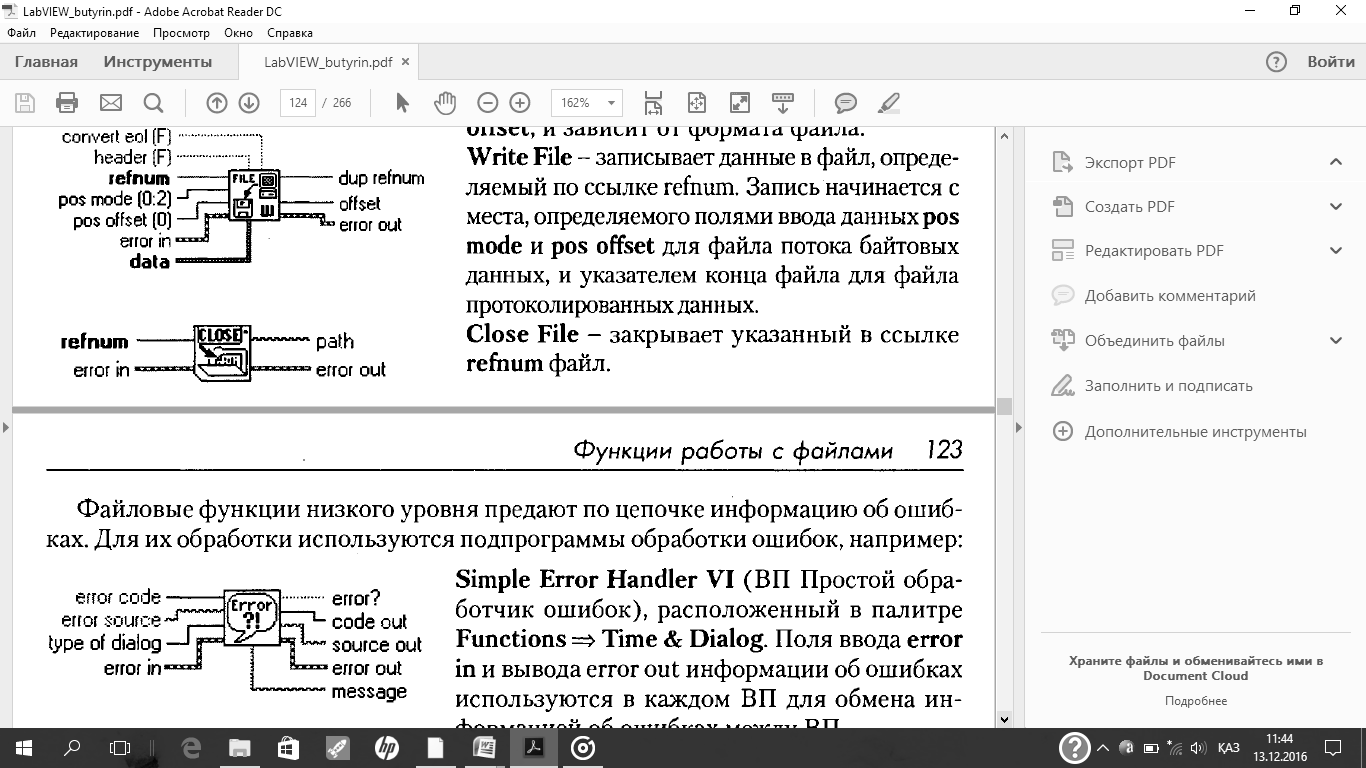
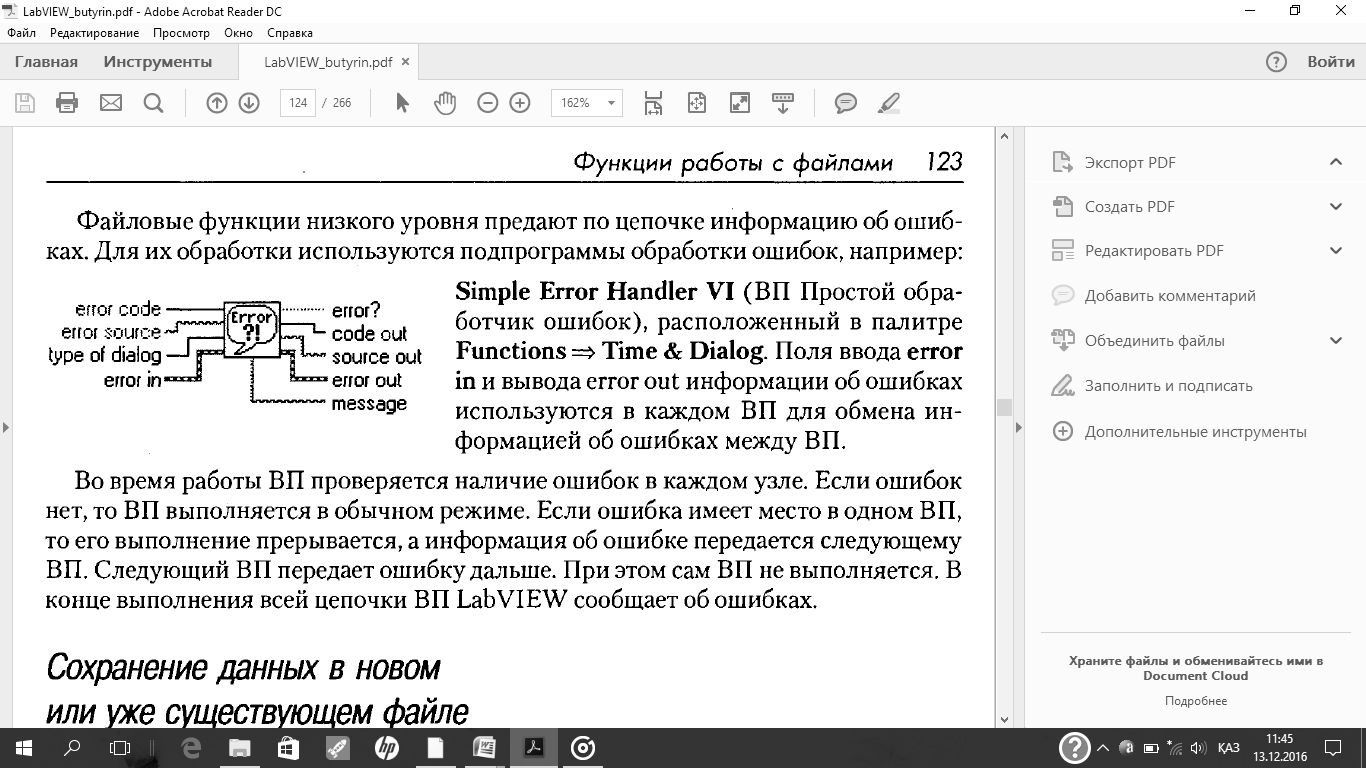
Функции файлового ввода/вывода высокого уровня
Функции файлового ввода/вывода высокого уровня расположены в верхней строке палитры Functions = File I/O.Они предназначены для выполнения основных операций по вводу/выводу данных. Использование функций файлового ввода/вывода высокого уровня позволяет сократить время и усилия программистов при записи и считывании данных в/из файл(а). Функции файлового ввода/вывода высокого уровня выполняют запись и считывание данных и операции закрытия и открытия файла. При наличии ошибок файловые функции высокого уровня отображают диалоговое окно с описанием
ошибок, в котором пользователю предлагается продолжить выполнение программы или остановить ее. Однако из-за того, что функции данного класса объединяют весь процесс работы с файлами в один ВП, переделать их под определенную задачу бывает трудно. Для специфических задач следует использовать функции файлового ввода/вывода низкого уровня.
| Напишите функции файлового ввода/выводанизкого уровня |
Функции файлового ввода/вывода низкого уровня
Функции файлового ввода/вывода низкого уровня расположены в средней строке палитры Functions = File I/O.Дополнительные функции работы с файлами (Advanced File I/O)расположены в палитре Functions = File I/O = Advanced File Functionsи предназначены для управления отдельными операциями над файлами. Функции файлового ввода/вывода низкого уровня используются для создания нового или обращения к ранее созданному файлу, записи и считывания данных и закрытия файла. Функции низкого уровня работы с файлами поддерживают все операции, необходимые при работе с файлами. Для осуществления основных операций файлового ввода/вывода используются следующие ВП и функции:
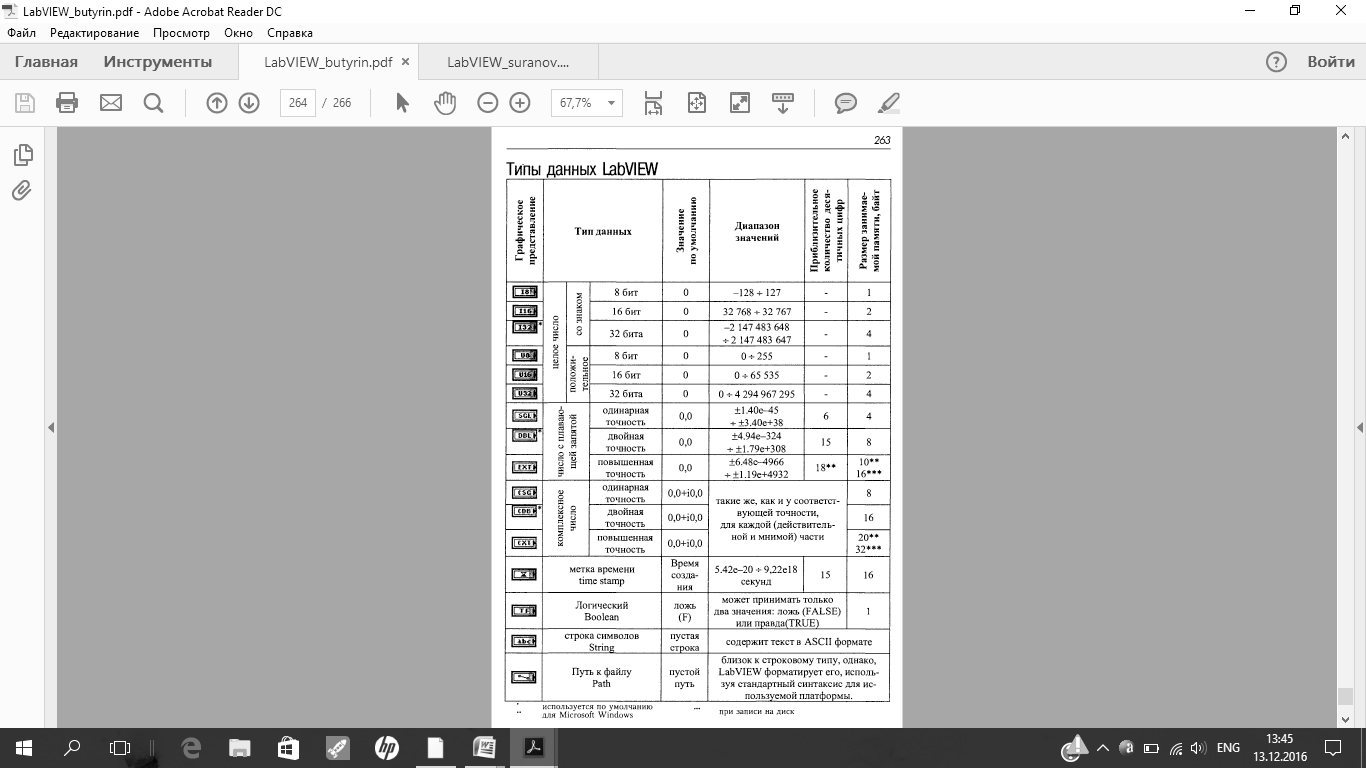
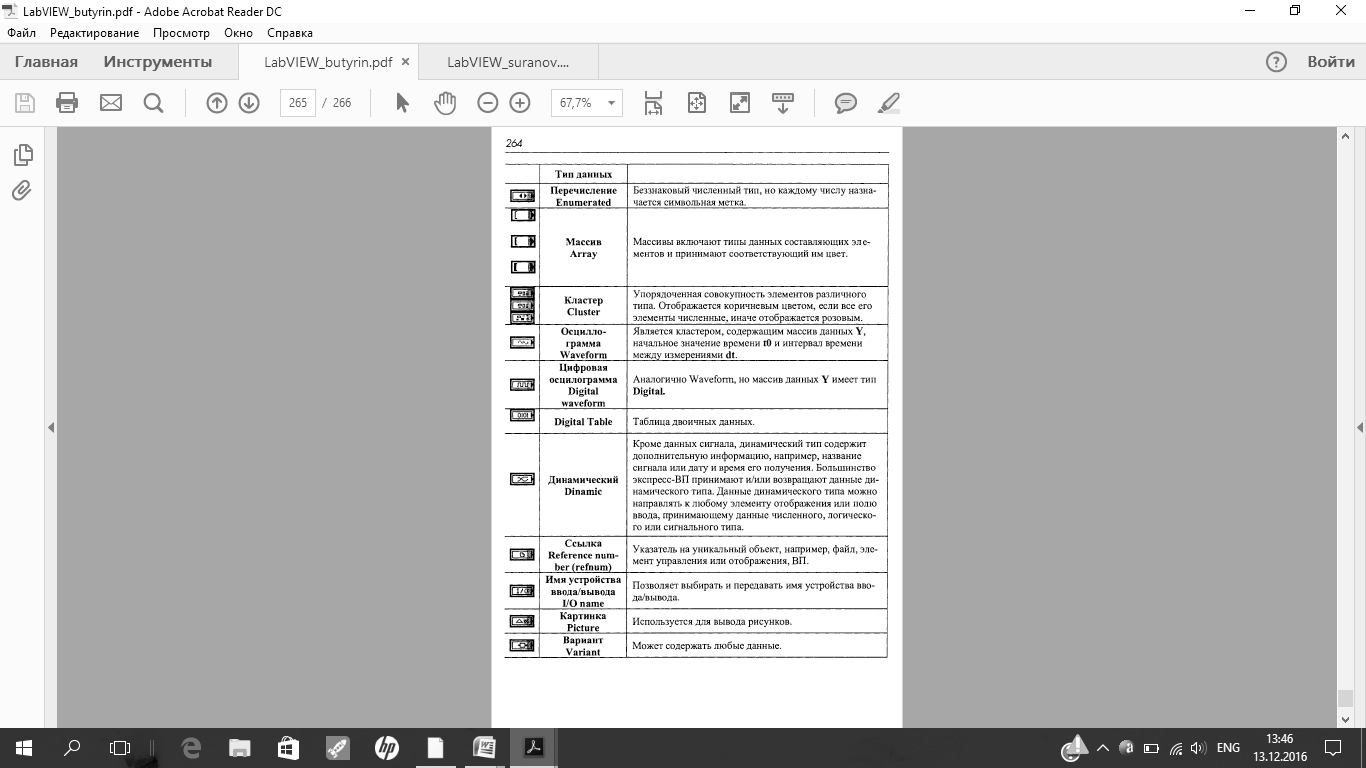
| Опишите типы данных в LabVIEW |
| Объясните способ сбора данных на базетрадиционного NI-DAQ |
Среда LabVIEW включает в себя набор подпрограмм ВП, позволяющих конфигурировать, собирать и посылать данные на DAQ-устройства. Сама аббревиатура DAQ расшифровывается как Data Acquisition и переводится на русский язык как сбор данных. DAQ-устройства могут выполнять разнообразные функции: аналого-цифровое преобразование (A/D), цифро-аналоговое преобразование (D/A), цифровой ввод/вывод (I/O) и управление счетчиком/таймером. Каждое устройство имеет свой набор возможностей, у каждого устройства своя скорость обработки данных.
Статьи к прочтению:
- Оплата за неотработанное время.
- Оплата за участие в дополнительной номинации составляет 320 руб/номинация.
Vending SCP-261 Pan-dimensional e Experimento Log 261 Ad De + completa +
Похожие статьи:
-
Обработку массивов удобно организовывать с помощью специальных функций. Для обработки массива в качестве аргументов функции необходимо передать адрес…
-
Массив Массив (или массив данных) – это набор однородных(одного типа) элементов, к которым можно обратиться по их порядковому номеру (индексу). Массив…