
Построение программы грамматического разбора для заданного синтаксиса
Программу, которая распознает какой-либо язык, легко построить на основе его детерминированного синтаксического графа (если таковой существует). Этот граф фактически представляет собой блок-схему программы, при ее разработке рекомендуется строго следовать правилам преобразования, подобным тем, с помощью которых можно предварительно получить из БНФ графическое представление синтаксиса. Применение данных правил предполагает наличие основной программы, содержащей процедуры, которые соответствуют различным подцелям, а также процедуру перехода к очередному символу. Для простоты мы будем считать, что предложение, которое нужно анализировать, представлено входным файлом input и что терминальные символы – отдельные значения типа char. Пусть символьная переменная char ch всегда содержит очередной читаемый символ. Тогда переход к следующему символу выражается оператором: ch = fgetc(input); Следует отметить, что функция char fgetc(FILE *fp) является стандартной функцией языка Си для чтения символа из файла и для ее использования необходимо в начале программы подключить соответствующий заголовочный файл директивой #includeОсновная программа будет состоять из оператора чтения первого символа, за которым следует оператор активации основной цели грамматического разбора. Отдельные процедуры, соответствующие целям грамматического разбора или графам, получаются по следующим правилам. Пусть оператор, полученный с помощью преобразования графа S, обозначается через T(S).
21) Построение таблично-управляемой программы грамматического разбора.
Конкретные грамматики задаются таблично-управляемой универсальной программе в виде исходных данных, предшествующих предложениям, которые нужно разобрать. Универсальная программа работает в строгом соответствии с методом простого нисходящего грамматического разбора; поэтому она довольно проста, если основана на детерминированном синтаксическом графе, т.е. если предложения можно анализировать с просмотром вперед на один символ без возврата. В данном случае грамматика (предположим, что она представлена в виде детерминированного множества синтаксических графов) преобразуется в подходящую структуру данных, а не в структуру программы. Естественный способ представить граф – это ввести узел для каждого символа и связать эти узлы с помощью ссылок. Следовательно, таблица – это не просто массив. Узлы этой структуры представляют собой структуры (struct) с объединениями (union). Объединение позволяет идентифицировать тип узла. Первый идентифицируется терминальным символом, который он обозначает (tsym), второй – ссылкой на структуру данных, представляющую соответствующий нетерминальный символ (nsym). Оба варианта объединения содержат две ссылки: одна указывает на следующий символ, последователь (suc), а другая связана со списком возможных альтернатив (alt). Графически узел можно изобразить следующим образом: 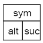
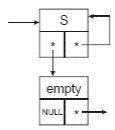
Также нужен элемент, представляющий пустую последовательность, символ пусто. Обозначим его с помощью терминального элемента, называемого empty.
Правила преобразования графов в структуре данных аналогичны правилам В1-В7.
Правила преобразования графов в структурах данных:
С1. Свести систему графов к как можно меньшему числу отдельных графов с помощью соответствующих подстановок.
С2. Преобразовать каждый граф в структуру данных согласно правилам С3-С5, приведенным ниже.
С3. Последовательность элементов (см. рис. к правилу В3) преобразуется в следующий список узлов:

С4. Список альтернатив (см. рис. к правилу В4) преобразуется в
следующую структуру данных:
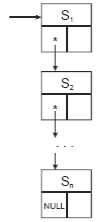
С5. Цикл (см. рис. к правилу В5) преобразуется в следующую структуру:
Статьи к прочтению:
Enterprise 2 | SB | Unit 6 | Упражнение на составление предложений на с.45
Похожие статьи:
-
В программе Excel термин диаграмма используется для обозначения всех видов графического представления числовых данных. Построение графического…
-
Построение синтаксического графа.
Для построения синтаксического анализатора можно использовать два различных метода. Один из них – это написать универсальную программу грамматического…