
Решение дифференциальных уравнений
Дифференциальные уравнения являются основной формой представления математических моделей. Напомним, что уравнение, в котором неизвестная функция входит под знаком производной или дифференциала, называется дифференциальным уравнением. Если неизвестная функция, входящая в дифференциальное уравнение, зависит только от одной независимой переменной, то уравнение называется обыкновенным. Обыкновенное дифференциальное уравнение в общем случае содержит независимую переменную (X), неизвестную функцию (Y(X)) и ее производные (dY/dX) до n-го порядка и имеет вид
F(X, Y, Y¢, Y?, … , Y(n))=0.
Порядком дифференциального уравнения называется наивысший порядок производной, входящей в уравнение.
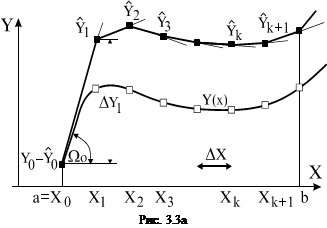 |
Здесь мы рассмотрим технику решения обыкновенных дифференциальных уравнений с начальными условиями, т.е. таких, для которых известны значения искомой функции и ее производных (до n-1 порядка) при Х=0. Решение уравнений в такой постановке называется задачей Коши. Известно, что аналитическое решение дифференциальных уравнений возможно лишь в небольшом числе случаев. В остальных случаях оно доступно только с помощью численных методов. Самый простой из них – метод Эйлера. Суть метода применительно к уравнению первого порядка dY/dX=Y(X,Y) с начальными условиями Y(X0)=Y0поясняет рис. 11.3а.
 Решением уравнения является такая функция Y(Х), которая, будучи подставленной в уравнение, превращает его в тождество. Само уравнение не известно. В начальных условиях задается только одна его точка Y(Х0). Разобьем весь диапазон интегрирования уравнения на участки с одинаковым шагом DХ и попытаемся найти значение искомой функции Y(Х) в точке Х1=Х0+DХ. Здесь искомая функция изображена линией с ординатами Y0,Y1,Y2,…, Yk+1 (пустые прямоугольники), а полученная по методу Эйлера – ломаной с ординатами Y0, Y1,Y2, …, Yk+1 (черные прямоугольники). Если DХ мало – можно полагать, что уравнение касательной к искомой функции в точке Х0 (прямая Y0Y1) не сильно отличается от Y(Х) на участке DХ (дуга Y0Y1). Найдем Y1
Решением уравнения является такая функция Y(Х), которая, будучи подставленной в уравнение, превращает его в тождество. Само уравнение не известно. В начальных условиях задается только одна его точка Y(Х0). Разобьем весь диапазон интегрирования уравнения на участки с одинаковым шагом DХ и попытаемся найти значение искомой функции Y(Х) в точке Х1=Х0+DХ. Здесь искомая функция изображена линией с ординатами Y0,Y1,Y2,…, Yk+1 (пустые прямоугольники), а полученная по методу Эйлера – ломаной с ординатами Y0, Y1,Y2, …, Yk+1 (черные прямоугольники). Если DХ мало – можно полагать, что уравнение касательной к искомой функции в точке Х0 (прямая Y0Y1) не сильно отличается от Y(Х) на участке DХ (дуга Y0Y1). Найдем Y1
Y1=Y0+DY1=Y0+DХ?Tg(W0).
Тангенс W0равен значению производной функции Y(Х) в точке Х0, которую легко вычислить
TgW0=Y’0=Z(X0,Y0). И можем записать Y=Y0+DХ?Z(X0,Y0).
Следующий шаг – проведение касательной к Y(Х1), т.е. построение участка с тангенсом наклона, равным Z(X1,Y1). Однако поскольку нам известно не точное значение Y1, а приближенное Y1, проведем линию с тангенсом угла наклона, равным Z(X1,Y1). Тогда
Y 2=Y1+DХ?Z(Х1,Y1).
Отсюда можем получить рабочие формулы метода
Хk+1=Хk+DХ и Yk+1=Yk+DХ?Z(Хk,Yk).
Метод является весьма приблизительным (сравните вычисленную и настоящую функции на рисунке). Уменьшив шаг интегрирования DХ, можно добиться приемлемой погрешности. При DХ?0 решение сходится к точному.
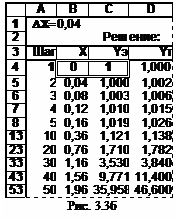
На рис.3.3б и 3в представлены (в числовом и формульном виде) таблицы решения дифференциального уравнения (начальные условия Y(0)=1) вида:
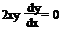 |
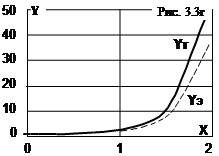
Решение Y=exp(X2) такого простого уравнения известно, что позволит нам оценить точность вычислений в таблице. Здесь в ячейке В1 установлен шаг интегрирования 0,4, в В4 и С4 – начальные условия уравнения. Текущие значения номера шага и значения Х вычисляются аналогично предыдущему. В колонке Yэ находится решение по методу Эйлера, а в колонке Yт – предъявляется точное решение с непосредственным использованием функции exp(X2). Решение доведено до Х=1,96 (50 шагов). Видим (рис. 3.3б), что точное решение и решение, полученное с помощью метода Эйлера, достаточно близки. Это подтверждает и график на рис.3.3г, построенный также средствами Excel (тип диаграммы: “точечная”, вид: “Точечная диаграмма со значениями, соединенными отрезками без маркеров”). Дальнейшее снижение погрешности может быть достигнуто уменьшением шага интегрирования. Увеличение предела интегрирования может быть осуществлено, как и в предыдущем случае, копированием последней строки до достижения нужного значения аргумента Х.
| A | B | C | D | |
| DC= | 0,04 | |||
| Р е ш е | н и е: | |||
| Шаг | X | Yэ | Yт | |
| =EXP(B4^2) | ||||
| =A4+1 | =B4+B$1 | =C4+B$1*2*B4*C4 | =EXP(B5^2) | |
| =A5+1 | =B5+B$1 | =C5+B$1*2*B5*C5 | =EXP(B6^2) | |
| Рис. 3.3в |
Конечно, при такой организации вычислений, к которой нам пришлось прибегнуть для интегрирования и решения дифференциальных уравнений, мы ограничены числом строк в рабочем листе Excel. И хотя мы можем продолжить вычисления на другом листе, нам вряд ли потребуется и такое число строк.
 Как уже указывалось, метод Эйлера является самым простым (и самым грубым) средством решения дифференциальных уравнений. Здесь можно воспользоваться и более точными методами, например, методом Рунге-Кутта.
Как уже указывалось, метод Эйлера является самым простым (и самым грубым) средством решения дифференциальных уравнений. Здесь можно воспользоваться и более точными методами, например, методом Рунге-Кутта.
Тест. 3.3.1. Что мы получим при решении дифференциального уравнения? 1). число, 2). функцию.
4.
АППРОКСИМАЦИЯ
ЗАВИСИМОСТЕЙ
Задача аппроксимации возникает при необходимости аналитически описать явления, имеющие место в жизни и заданные в виде таблиц, содержащих значения аргумента/аргументов и функции. Если зависимость удается найти, можно сделать прогноз о поведении исследуемой системы в будущем и, возможно, выбрать оптимальное направление ее развития. Такая аналитическая функция (называемая еще трендом) может иметь разный вид и разный уровень сложности в зависимости от сложности системы и желаемой точности представления.
ЛИНЕЙНАЯ РЕГРЕССИЯ
Самый простой и популярной является аппроксимация прямой линией – линейная регрессия.
 Пусть мы имеем фактическую информацию об уровнях прибыли Y в зависимости от размера X капиталовложений – Y(X). На рис. 4.1-1 показаны четыре такие точки М(Y,X). Пусть также у нас имеются основания предполагать, что зависимость эта линейная, т.е. имеет вид Y=А+ВX.Если бы нам удалось найти коэффициенты A и B и по ним построить прямую (например, такую, как на рисунке), в дальнейшем мы могли бы сделать осознанные предположения о динамике бизнеса и возможном коммерческом состоянии предприятия в будущем. Нас бы устроила прямая, находящаяся как можно ближе к известным точкам М(Y,X), т.е. имеющая минимальную сумму отклонений или сумму ошибок (на рисунке отклонения показаны пунктирами). Известно, что существует только одна такая прямая. Для решения этой задачи используют метод наименьших квадратов ошибок. Разность (ошибка) между известным значением Y1точки М1(Y1,X1) и значением Y(X1), вычисленным по уравнению прямой для того же значения X1, составит
Пусть мы имеем фактическую информацию об уровнях прибыли Y в зависимости от размера X капиталовложений – Y(X). На рис. 4.1-1 показаны четыре такие точки М(Y,X). Пусть также у нас имеются основания предполагать, что зависимость эта линейная, т.е. имеет вид Y=А+ВX.Если бы нам удалось найти коэффициенты A и B и по ним построить прямую (например, такую, как на рисунке), в дальнейшем мы могли бы сделать осознанные предположения о динамике бизнеса и возможном коммерческом состоянии предприятия в будущем. Нас бы устроила прямая, находящаяся как можно ближе к известным точкам М(Y,X), т.е. имеющая минимальную сумму отклонений или сумму ошибок (на рисунке отклонения показаны пунктирами). Известно, что существует только одна такая прямая. Для решения этой задачи используют метод наименьших квадратов ошибок. Разность (ошибка) между известным значением Y1точки М1(Y1,X1) и значением Y(X1), вычисленным по уравнению прямой для того же значения X1, составит
D1= Y1– A – B•X1.
Такая же разность
для X=X2 составит D2= Y2– A – B•X2;
для X=X3 D3= Y3– A – B•X3;
и для X=X4 D4= Y4– A – B•X4.
Запишем выражение для суммы квадратов этих ошибок
Ф(A,В)=(Y1–A–B•X1)2+(Y2–A–B•X2)2+(Y3–A–B•X3)2+(Y4–A–B•X4)2
или сокращенно Ф(B,A)=a(Yi – A – BXi)2.
i=1
Здесь нам известны все X и Y и неизвестны коэффициенты A и B. Проведем искомую прямую так (т.е. выберем A и B такими), чтобы эта сумма квадратов ошибок Ф(A,B) была минимальной. Условиями минимальности являются известные соотношения
¶Ф(A,B)/¶A=0 и ¶Ф(A,B)/¶B=0.
Выведем эти выражения (индексы при знаке суммы опускаем):
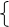 ¶[a(Yi–A–B•Xi)2]/¶A = a(Yi–A–B•Xi)(–1)
¶[a(Yi–A–B•Xi)2]/¶A = a(Yi–A–B•Xi)(–1)
¶[a(Yi–A–B•Xi)2]/¶B = a(Yi–A–B•Xi)(–Xi).
Преобразуем полученные формулы и приравняем их нулю
2a(–Yi +B•Xi +A) = 0
2a(–Xi•Yi +B•Xi2 +A•Xi) = 0.
Сократим выражения на 2 и раскроем скобки. Тогда
–aYi + BaXi + Aa1 = 0
–aXi•Yi + BaXi2 +AaXi = 0.
Мы получили систему из двух линейных алгебраических уравнений, в которой неизвестными являются A и B, а сумма N единиц равна N (в нашем случае a1=4). Перенесем свободные члены в правую часть и для упрощения записи опустим индексы при знаке суммирования. Окончательно получим:
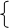 BaX + NA = aY
BaX + NA = aY
BaX2+AaX =aXY.
Решив эту систему с помощью любого известного метода линейной алгебры, получим
В=(N•aXY–aX•aY)/( N•aX2–X•aX), А=(N•aX2–aX•aX)/(N•aX2–aX•aX).
В случае, если величина Y зависит не от одного, а от нескольких параметров Y(x,z, …w), задача нахождения коэффициентов решается аналогично и называется задачей множественной регрессии.
Оценить функциональную близость (в линейном смысле) значений Х и Y можно с помощью коэффициента корреляции R, который находится по следующей формуле
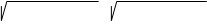 R=(N•aXY – aX•aY)/( N•aX2–aX•aX • N•aY2–aY•aY ).
R=(N•aXY – aX•aY)/( N•aX2–aX•aX • N•aY2–aY•aY ).
Cчитается что при R?0,3 наблюдается слабая линейная связь, при R= 0,3¸0,7 – средняя, при R³0,7 – сильная, при R³0,9 – весьма сильная связь, при R=1 – полная функциональная связь (все точки Y(X) лежат на одной прямой).
В Excel имеются функции для нахождения коэффициентов уравнения линейной регрессии.
u ЛИНЕЙН(известное Y; известное X) – вычисляет два коэффициента линейного уравнения регрессии для множества значений независимой переменной Х и зависимой переменной Y. Результат выводится в две смежные ячейки – сначала коэффициент при Х, затем – свободный член. Функция должна вводиться как функция обработки массива: выделяются две ячейки для результата, вводится функция и нажимаются клавиши Ctrl+Shift+Enter (вместо обычного Enter).
Пример. Если исходные данные расположены, как показано на рис. 4.1-2, и в C3:D3 введена функция {=ЛИНЕЙН(B2:B11;A1:A11)},результаты в C3 и D3 можно интерпретировать как коэффициенты линейного уравнения регрессии y=0,6364x+1,8. Таким образом, если нам понадобится вычислить ожидаемое значение прибыли Y в будущем, например, при капиталовложениях в сумме 20 единиц, нужно подставить их в найденную функцию Y=0,64+1,8*20=36,64.
u ТЕНДЕНЦИЯ(известное Y; известное X; новое X) – вычисляет ожидаемое новое значение Y для нового Х, если известны некоторые опытные значения X и Y и в предположении, что Х и Y зависят линейно.
| А | В | С | D | |
| Х | Y | |||
| ЛИНЕЙН | ||||
| 0,64 | 1,8 | |||
| ТЕНДЕНЦИЯ | ||||
| 9,44 | ||||
| 4,5 | 4,66 | |||
| Ри | с.4.1.2 |

Пример: Исходные данные расположены (рис. 4.1-2) в C7 и C8, результаты – в
D7=ТЕНДЕНЦИЯ(B2:B11;A1:A11;G4)и
D8=ТЕНДЕНЦИЯ( B2:B11; A1:A11;G5).
Таким образом, при Х=12 ожидается Y=9,44, а при Х=4,5; Y=4,66.
Используя значения X и Y с помощью Excel, построим график, совмещенный с линией регрессии (линией тренда), как показано на рис.4.1.3.
@ В Excel имеется очень простой способ строить линейную аппроксимацию равноотстоящих значений аргумента. Для этого нужно выделить известные значения прогнозируемой величины и потянуть за маркер заполнения, удерживая правую кнопку мыши. Затем, из появившегося контекстного меню выбрать пункт Линейное приближение. В заполняемых клетках мы обнаружим значения, вычисленные системой для самостоятельно найденного ею линейного уравнения регрессии. На рис.4.1.4 исходными значениями являются 2, 4, 5. Остальные числа являются вычисленным прогнозом в предположении линейной связи аргументов в соответствии с найденным Excel уравнением. Здесь же (рис.10.1.5), при необходимости, можно выбрать и Экспоненциальное приближение.
 5 5 | 6,67 | 8,17 | 9,67 | 11,17 | 12,67 | Рис. 4.1.4 | ||
 5 5 | 8,55 | 13,52 | 21,37 | 33,80 | 53,44 | Рис. 4.1.5 |
 С помощью средств деловой графики Excel можно не только построить необходимые кривые, но получить линии тренда и соответствующие им уравнения Y(X) (здесь y=1,5x+0,6667 для линейного закона, y=1,368e0,4581x– для экспоненты). Экспоненциальная аппроксимация обозначена прямоугольными точками, линейная – кружками. Исходные точки обведены овалом.
С помощью средств деловой графики Excel можно не только построить необходимые кривые, но получить линии тренда и соответствующие им уравнения Y(X) (здесь y=1,5x+0,6667 для линейного закона, y=1,368e0,4581x– для экспоненты). Экспоненциальная аппроксимация обозначена прямоугольными точками, линейная – кружками. Исходные точки обведены овалом.
Статьи к прочтению:
- Решение задач бизнес-анализа средствами аппарата сводных таблиц ms excel
- Решения нелинейных уравнений.
Основные понятия дифференциальных уравнений от bezbotvy
Похожие статьи:
-
Многие уравнения, например трансцендентные, не имеют аналитических решений. Однако они могут решаться численными методами с заданной погрешностью. Для…
-
В.20модели, описываемые дифференциальными уравнениями в частных
Производных. Сеточные методы решения. Проекционные методы. Проекционно-сеточные методы (метод конечных элементов). Стандартные пакеты. Методы…