
Synchronousdynamicrandomaccessmemory (sdram)
Чтение из микросхем памяти DRAM могло осуществляться в любой момент времени. При этом время чтения данных могло быть различным. Для завершения цикла чтения-записи в заданное время была создана синхронная DRAM. Работа это микросхемы памяти была синхронизирована с интерфейсом памяти посредством подачи на микросхему синхросигнала. Чтение и запись могли производиться только по фронту или по срезу этого сигнала. В микросхемах DDR SDRAM (Double Data Rate SDRAM) чтение производится одновременно и по фронту и по спаду, что позволило увеличить в два раза скорость работы памяти по сравнению с обычной SDRAM.
Существенная отличительная особенность микросхем SDRAM от микросхем более ранних типов DRAM заключается в разбиении массива данных на несколько логических банков (как минимум — 2, обычно — 4). Разбиение массива памяти SDRAM на банки было введено, главным образом, для минимизации задержек поступления данных в систему. После осуществления любой операции со строкой памяти, требуется определенное время для осуществления ее «подзарядки». И преимущество «многобанковых» микросхем SDRAM заключается в том, что можно обращаться к строке одного банка, пока строка другого банка находится на «подзарядке». Можно расположить данные в памяти и организовать к ним доступ таким образом, что далее будут запрашиваться данные из второго банка, пока первый находится на «подзарядке». Такая схема доступа к памяти называется «доступом с чередованием банков» (Bank Interleave).
Статическая ОЗУ (SRAM).
Статическая память строится на триггерах – устройствах, способных бесконечно долго поддерживать своё состояние при условии наличия питания.
Устройство триггера.
Триггер – это элемент памяти, способный принимать и поддерживать пока на нём присутствует питание одно из двух состояний – «0» или «1».
Существует множество разновидностей триггеров: RS, D, JK и т.д. Названия этих триггеров происходит от названия их входов. В данном методическом пособии будет рассмотрен RS триггер.
Вид триггера на схеме представлен на рис 8.5.
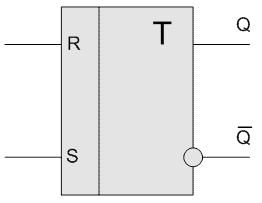
Рис 8.5
Вход R (reset) является сигналом сброса (установки нуля), а сигнал S (set) – установки единицы. Выход Q является прямым, а  – обратным.
– обратным.
Если на входе R устанавливается 1, то Q принимает значение 0, а – единица. Если на входе S устанавливается 1, то на Q принимает значение 1, а – 0. Если же оба значения равны нулю, то состояние триггера не меняется. Комбинация R=1 и S=1 в данном триггере не определена.
На таких триггерах построена статическая память. Её преимуществом является отсутствие необходимости возобновлять данные, более высокая скорость работы, по сравнению с динамической памятью. К недостаткам можно отнести более высокую себестоимость по сравнению с динамической памятью, большее энергопотребление и большую занимаемую площадь. В итоге данный вид памяти применяется только при построении кэш памяти процессоров.
Стек (Stack).
Стек — это часть оперативной памяти, предназначенная для временного хранения данных в режиме LIFO (Last In — First Out). Особенность стекапо сравнению с другой оперативной памятью — это заданный и неизменяемый способ адресации. При записи любого числа в стекчисло записывается по адресу, определяемому как содержимое регистрауказателя стека, предварительно уменьшенное (декрементированное) на единицу (или на два, если 16-ти разрядные слова расположены в памяти по четным адресам).
При чтении из стекачисло читается из адреса, определяемого содержимым указателя стека, после чего это содержимое указателя стекаувеличивается (инкрементируется) на единицу (или на два). В результате получается, что число, записанное последним, будет прочитано первым, а число, записанное первым, будет прочитано последним. Такая память называется LIFO. Принцип действия стекапоказан на рис. 8.5 (адреса ячеек памяти выбраны условно).
Рис 8.5
Пусть, например, текущее состояние указателя стека 1000008, и в него надо записать два числа (слова). Первое слово будет записано по адресу 1000006 (перед записью указатель стека уменьшится на два). Второе — по адресу 1000004. После записи содержимое указателя стека — 1000004. Если затем прочитать из стека два слова, то первым будет прочитано слово из адреса 1000004, а после чтения указатель стека станет равным 1000006. Вторым будет прочитано слово из адреса 1000006, а указатель стека станет равным 1000008. Все вернулось к исходному состоянию. Первое записанное слово читается вторым, а второе — первым.
Необходимость такой адресации становится очевидной в случае многократно вложенных подпрограмм. Пусть, например, выполняется основная программа, и из нее вызывается подпрограмма 1. Если нам надо сохранить значения данных и внутренних регистровосновной программы на время выполнения подпрограммы, мы перед вызовом подпрограммы сохраним их в стеке, а после ее окончания извлечем данные из него. Если же из подпрограммы 1 вызывается подпрограмма 2, то ту же самую операцию мы проделаем с данными и содержимым внутренних регистровподпрограммы 1. Понятно, что внутри подпрограммы 2 крайними в стеке(читаемыми в первую очередь) будут данные из подпрограммы 1, а данные из основной программы будут глубже. При этом в случае чтения из стекаавтоматически будет соблюдаться нужный порядок читаемой информации. То же самое будет и в случае, когда таких уровней вложения подпрограмм гораздо больше. То есть то, что надо хранить подольше, прячется поглубже, а то, что скоро может потребоваться с краю.
В системе команд любого процессора для обмена информацией со стекомпредусмотрены специальные команды записи в стек(PUSH) и чтения из стека(POP). В стекеможно прятать не только содержимое всех внутренних регистровпроцессоров, но и содержимое регистрапризнаков (слово состояния процессора, PSW). Это позволяет, например, при возвращении из подпрограммы контролировать результат последней команды, выполненной непосредственно перед вызовом этой подпрограммы.
Можно также хранить в стекеи данные. Это позволяет удобнее передавать их между программами и подпрограммами. В общем случае, чем больше область памяти, отведенная под стек, тем более сложные программы могут выполняться.
Таблица векторов прерываний.
Под прерыванием в общем случае понимается не только обслуживание запроса внешнего устройства, но и любое нарушение последовательной работы процессора. Например, может быть предусмотрено прерывание по факту некорректного выполнения арифметической операции типа деления на ноль. Или же прерывание может быть программным, когда в программе используется команда перехода на какую-то подпрограмму, из которой затем последует возврат в основную программу. В последнем случае общее с аппаратным прерыванием только то, как осуществляется переход на подпрограмму и возврат из нее.
Любое прерывание обрабатывается через таблицу векторов (указателей) прерываний. В этой таблице в простейшем случае находятся адреса начала программ обработки прерываний, которые и называются векторами. Длина таблицы может быть довольно большой (до нескольких сот элементов). Обычно таблица векторов прерываний располагается в начале пространства памяти (в ячейках памяти с малыми адресами). Адрес каждого вектора (или адрес начального элемента каждого вектора) представляет собой номер прерывания. В случае аппаратных прерываний номер прерывания или задается устройством, запросившим прерывание (при векторных прерываниях), или же задается номером линии запроса прерываний (при радиальных прерываниях).
Процессор, получив аппаратное прерывание, заканчивает выполнение текущей команды и обращается к памяти в область таблицы векторов прерываний, в ту ее строку, которая определяется номером запрошенного прерывания. Затем процессор читает содержимое этой строки (код вектора прерывания) и переходит в адрес памяти, задаваемый этим вектором. Начиная с этого адреса, в памяти должна располагаться программа обработки прерывания с данным номером. В конце программы обработки прерываний обязательно должна располагаться команда выхода из прерывания, выполнив которую, процессор возвращается к выполнению прерванной основной программы. Параметры процессора на время выполнения программы обработки прерывания сохраняются в стеке.
Прерывание в случае аварийной ситуации обрабатывается точно так же, только адрес вектора прерывания (номер строки в таблице векторов) жестко привязан к данному типу аварийной ситуации.
Программное прерывание тоже обслуживается через таблицу векторов прерываний, но номер прерывания указывается в составе команды, вызывающей прерывание.
Такая сложная, на первый взгляд, организация прерываний позволяет программисту легко менять программы обработки прерываний, располагать их в любой области памяти, делать их любого размера и любой сложности. Во время выполнения программы обработки прерывания может поступить новый запрос на прерывание. В этом случае он устанавливается в очередь и будет обработан после завершения предыдущего прерывания.
Отметим, что в более сложных случаях в таблице векторов прерываний могут находиться не адреса начала программ обработки прерываний, а так называемые дескрипторы (описатели) прерываний. Но конечным результатом обработки этого дескриптора все равно будет адрес начала программы обработки прерываний.
Так же в таблице векторов прерываний описывается приоритет прерываний. Это надо для обработки одновременно пришедших запросов на прерывание. В этом случае первым будет обработан тот запрос, приоритет у которого выше.
Внешняя память.
Зачастую случается, что микроконтроллеру не хватает памяти для решения поставленной задачи. В этом случае существует возможность подключения внешнего модуля памяти, с которой микроконтроллер будет взаимодействовать как со своей собственной. При этом обычно происходит адресное расширение памяти. Подключаемый модуль памяти может быть как ОЗУ, так и ПЗУ и располагаться в нём могут любые виды данных (программа, переменные, настройки системы и т.д.).
Иногда это пространство памяти используется как единое целое, без всяких границ. А иногда пространство памяти делится на сегменты с программно изменяемым адресом начала сегмента и с установленным размером сегмента.
Оба подхода имеют свои плюсы и минусы. Например, использование сегментов позволяет защитить область программ или данных, но зато границы сегментов могут затруднять размещение больших программ и массивов данных.
Адресация операндов
Большая часть команд процессора работает с кодами данных (операндами). Одни команды требуют входных операндов (одного или двух), другие выдают выходные операнды (чаще один операнд). Входные операнды называются еще операндами- источниками, а выходные называются операндами-приемниками. Все эти коды операндов (входные и выходные) должны где-то располагаться. Они могут находиться во внутренних регистрах процессора (наиболее удобный и быстрый вариант). Они могут располагаться в системной памяти (самый распространенный вариант). Наконец, они могут находиться в устройствах ввода/вывода (наиболее редкий случай). Определение места положения операндов производится кодом команды. Причем существуют разные методы, с помощью которых код команды может определить, откуда брать входной операнд и куда помещать выходной операнд. Эти методы называются методами адресации. Эффективность выбранных методов адресации во многом определяет эффективность работы всего процессора в целом.
Методы адресации
Количество методов адресации в различных процессорах может быть от 4 до 16. Рассмотрим несколько типичных методов адресации операндов, используемых сейчас в большинстве микропроцессоров.
Непосредственная адресация(рис. 3.1) предполагает, что операнд входной) находится в памяти непосредственно за кодом команды. Операнд обычно представляет собой константу, которую надо куда-то переслать, к чему-то прибавить и т.д. Например, команда может состоять в том, чтобы прибавить число 6 к содержимому какого-то внутреннего регистра процессора. Это число 6 будет располагаться в памяти, внутри программы в адресе, следующем за кодом данной команды сложения.
Прямая (она же абсолютная) адресация(рис. 3.2) предполагает, что перанд (входной или выходной) находится в памяти по адресу, код которого находится внутри программы сразу же за кодом команды. Например, команда может состоять в том, чтобы очистить (сделать нулевым) содержимое ячейки памяти с адресом 1000000. Код этого адреса 1000000 будет располагаться в памяти, внутри программы в следующем адресе за кодом данной команды очистки.
Регистровая адресация(рис. 3.3) предполагает, что операнд (входной или выходной) находится во внутреннем регистре процессора. Например, команда может состоять в том, чтобы переслать число из нулевого регистра в первый. Номера обоих регистров (0 и 1) будут определяться кодом команды пересылки.
Косвенно-регистровая (она же косвенная) адресацияпредполагает, что во внутреннем регистре процессора находится не сам операнд, а его адрес в памяти (рис. 3.4). Например, команда может состоять в том, чтобы очистить ячейку памяти с адресом, находящимся в нулевом регистре. Номер этого регистра (0) будет определяться кодом команды очистки.
Реже встречаются еще два метода адресации.
Автоинкрементная адресацияочень близка к косвенной адресации, но отличается от нее тем, что после выполнения команды содержимое используемого регистра увеличивается на единицу или на два. Этот метод адресации очень удобен, например, при последовательной обработке кодов из массива данных, находящегося в памяти. После обработки какого-то кода адрес в регистре будет указывать уже на следующий код из массива. При использовании косвенной адресации в данном случае пришлось бы увеличивать содержимое этого регистра отдельной командой.
Автодекрементная адресацияработает похоже на автоинкрементную, но только содержимое выбранного регистра уменьшается на единицу или на два перед выполнением команды. Эта адресация также удобна при обработке массивов данных. Совместное использование автоинкрементной и автодекрементной адресаций позволяет организовать память стекового типа (см. раздел 2.4.2). Из других распространенных методов адресации можно упомянуть об индексных методах, которые предполагают для вычисления адреса операнда прибавление к содержимому регистра заданной константы (индекса). Код этой константы располагается в памяти непосредственно за кодом команды. Отметим, что выбор того или иного метода адресации в значительной степени определяет время выполнения команды. Самая быстрая адресация — это регистровая, так как она не требует дополнительных циклов обмена по магистрали. Если же адресация требует обращения к памяти, то время выполнения команды будет увеличиваться за счет длительности необходимых циклов обращения к памяти. Понятно, что чем больше внутренних регистров у процессора, тем чаще и свободнее можно применять регистровую адресацию, и тем быстрее будет работать система в целом.
Адресация байтов и слов.
Многие процессоры, имеющие разрядность 16 или 32, способны адресовать не только целое слово в памяти (16-разрядное или 32-разрядное), но и отдельные байты. Каждому байту в каждом слове при этом отводится свой адрес. Так, в случае 16-разрядных процессоров все слова в памяти (16-разрядные) имеют четные адреса. А байты, входящие в эти слова, могут иметь как четные адреса, так и нечетные. Например, пусть 16-разрядная ячейка памяти имеет адрес 23420, и в ней хранится код 2А5Е (рис. 3.9).
Адресация слов и байтов. При обращении к целому слову (с содержимым 2А5Е) процессор выставляет адрес 23420. При обращении к младшему байту этой ячейки (с содержимым 5Е) процессор выставляет тот же самый адрес 23420, но использует команду, адресующую байт, а не слово. При обращении к старшему байту этой же ячейки (с содержимым 2А) процессор выставляет адрес 23421 и использует команду, адресующую байт. Следующая по порядку 16-разрядная ячейка памяти с содержимым 487F будет иметь адрес 23422, то есть опять же четный. Ее байты будут иметь адреса 23422 и 23423. Для различия байтовых и словных циклов обмена на магистрали в шине управления предусматривается специальный сигнал байтового обмена. Для работы с байтами в систему команд процессора вводятся специальные команды или предусматриваются методы байтовой адресации.
Задача:
Дано: Частота тактирование МК f=15 000 000 Гц. Необходимо настроить таймер, который выдаст прерывание через 1 мс. Задачу решить, если возможно, как для 8-ми разрядного, так и для 16-ти разрядного таймера. Оценить погрешность измерения 1 мс для каждого из таймеров.
Найти:
Определить требуемое значение предделителя, учитывая, что бывают следующие значения: 8, 16, 64, 256, 1024.
Определить число, до которого необходимо считать таймеру.
Статьи к прочтению:
- Thrashing. свойство локальности. модель рабочего множества
- Time boss стабильно работает бок о бок с антивирусными, антишпионскими и другими программами.
RAM Explained — Random Access Memory
Похожие статьи:
-
С точки зрения физического принципа действия — dram, sdram, ddr sdram.
Ячейки динамической памяти (DRAM – dynamic random access memory) можно представить в виде микроконденсаторов, способных накапливать заряд на своих…
-
Система команд эвм общего назначения
Методы адресации В машинах с регистрами общего назначения метод (или режим) адресации объектов, с которыми манипулирует команда, может задавать…