
Втоматический анализ и синтез текста
Автоматический анализ текста включает ряд весьма сложных операций, которые компьютер выполняет над текстом на естественном человеческом языке согласно заданному алгоритму. При автоматическом анализе текст последовательно преобразуется в его лексемно-морфологические, синтаксические и семантические представления, понятные компьютеру [13, 14]. Обратный процесс преобразования лексемно-морфологических, синтаксических и семантических компьютерных представлений в текст на естественном языке называется автоматическим синтезом текста. Автоматический анализ и синтез текста являются важными задачами компьютерной лингвистики как с точки зрения развития теории (разработки лингвистических основ создания искусственного интеллекта), так и с точки зрения реализации практических нужд человека, например, создания эффективных систем машинного перевода. Автоматический анализ текста включает ряд этапов [ 1,94,106—107]: 1) графематический анализ: выделение границ слов, предложений, абзацев и других элементов текста (например, врезок в газетном тексте); 2) морфологический анализ: определение исходной формы каждого использованного в тексте слова и набора морфологических характеристик этого слова; 3) синтаксический анализ: выявление грамматической структуры предложений текста; 4) семантический анализ: определение смысла фраз. Графематический анализ определяется также как токенизация (от англ. token = отдельное слово, фраза или любой другой значимый элемент текста1). Формальными сигналами границ текстовых элементов выступают разделители различного рода: пробелы, обозначающие границы между словами, прописные буквы и знаки препинания, обозначающие границы между предложениями и составными частями предложений, абзацные отступы, обозначающие границы между связанными по смыслу группами предложений и т.п. [7, 79]. Однако формальный метод определения границ слов применим не всегда. Например, в китайском языке нет формальных границ слов [54]. Кроме того, даже в распространенных европейских языках существуют устойчивые сочетания слов, разделенные пробелом, которые следует воспринимать как одну лексему, например, New York. Очевидно, что такие случаи следует учитывать в системах гра- фематического анализа, например, путем создания списков многословных лексем. При морфологическом анализе каждое использованное в тексте слово возводится к его исходной форме и определяется набор морфологических характеристик текстовой формы слова: часть речи; род, число и падеж для существительных, число и лицо для глаголов и т.п. Каждое употребленное в тексте слово называется словоформой (или словоупотреблением). Для обеспечения связности текста требуется повтор тех же самых слов, поэтому нередко разные словоформы одного или нескольких предложений текста возводятся к одной и той же исходной форме, ср.: Вот моя деревня; Вот мой дом родной. Вот качусь я в санках По горе крутой (И.З. Суриков). Алфавитно-частотный словарь словоформ этого фрагмента стихотворения выглядит так: в — 1, вот — 3, горе — 1, деревня — 1, дом — 1, качусь — 1, крутой — 1, мой — 1, моя — \,по — 1, родной — 1, санках — \,я — 1. Кроме неизменяемой частицы вот, употребленной 3 раза, отмечаем также притяжательное местоимение 1-го лица ед. числа, употребленное в формах мой и моя. В привычных нам словарях обычно перечисляются не словоформы, а слова, приведенные к определенной исходной форме. В качестве такой исходной формы употребленных в тексте словоформ в зависимости от типа языка может служить лемма (словарная форма лексемы) или основа (ядерная часть слова без словоизменительных морфем). Например, английские словоформы swim, swims, swam и swimming восходят к одной лемме swim. Во флективных и агглютинативных языках с богатым словоизменением для сохранения всех возможных словоформ потребуются достаточно значительные ресурсы памяти. Например, русское суще- ствительное, изменяющееся по числам (2 числа) и падежам (6 падежей), имеет 12 словоформ. Русский глагол характеризуется еще более сложным набором грамматических характеристик и соответственно имеет достаточно значительное количество словоформ [20, 83]. В этом случае в качестве исходной формы, к которой возводится слово, удобнее использовать его основу. Правда, в морфологическом анализе термин «основа» не всегда имеет тот же смысл, который вкладывается в него в канонической (школьной) грамматике. Например, если в слове встречается чередование букв (сидеть — сижу, друг — друзья и т.п.), то основой (точнее, квазиосновой, или машинной основой) в этих случаях выступает часть слова не только без словоизменительных морфем, но и без чередующихся букв, т.е. си# и дру#, соответственно. Такой тип выделения основ получил название стемминга, т.е. возведения разных словоформ к одной квазиоснове. Стемминг вполне подходит для решения некоторых автоматических задач, например, для осуществления поиска в Интернете. Так, пользовательскому запросу фотографии в качестве полной или неполной квазиосновы соответствуют существительное фотография и прилагательное фотографический. В результате поиска пользователь получит список документов со словосочетанием фотографический портрет и со словосочетанием портретная фотография [46]. Для морфологического анализа важно не только понятие машинной основы, понимаемой как последовательность букв от начала словоформы, общая для всех словоформ, входящих в формообразовательную парадигму данного слова. Следующий шаг — это определение частеречной принадлежности слова (частеречный тегинг) и его морфологических характеристик, что чаще всего происходит с опорой на словоизменительные элементы слова (машинные окончания). Машинные окончания — элементы, описывающие формоизменение конкретной лексемы и представляемые в виде парадигм. Все возможные наборы машинных окончаний зафиксированы в типовой парадигме лексемы. При этом, с одной стороны, можно наблюдать совпадения типовых парадигм (и, соответственно, машинных окончаний) разных лексем, например, ручка и кочка, а с другой, совпадения машинных основ лексем, имеющих разные типовые парадигмы ср. типовые парадигмы машинной основы лож#, относящейся к лексемам ложь и ложиться [8, 144—145]. По машинным окончаниям, входящим в определенные типовые парадигмы, осуществляется полная морфологическая характеристика каждой словоформы, например: Девочка {девочка = S, жен, од = им, ед} мыла {мыть = V, несов = прош, ед, изъяв, жен, перех | мыло = S, сред, неод = им, мн | = S, сред, неод = род, ед | = S, сред, неод = вин, мн} пол {пол = S, муж, неод = им, ед | = S, муж, неод = вин, ед | = А, кратк, муж, им, ед}. В приведенном анализе можно увидеть лексико-морфологическую многозначность второго и третьего слова. Выбор правильной формы осуществляется человеком с учетом синтаксической роли слова в предложении и его смысла. Автоматическое разрешение многозначности или снятие омонимии, понимаемое как выбор правильной интерпретации словоформы, допускающей несколько вариантов толкований, происходит путем ручной разметки или автоматически, на основе вероятностных моделей (например, в английском языке наиболее вероятно сочетание неопределенного артикля и существительного, следующего за ним) или на основе правил, созданных автоматически или человеком. Примеры таких правил следующие: • Если словоформа может быть как глаголом, так и существительным, и перед ней стоит артикль, эта словоформа в данном случае является существительным. • Если словоформа может быть как предлогом, так и подчинительным союзом, и если после нее до конца предложения нет глагола, эта словоформа в данном случае является предлогом [46]. Для автоматического морфологического анализа применяются парсеры — специальные компьютерные программы для автоматического анализа слов [32]. Кроме морфологических существуют и синтаксические парсеры, применяемые для автоматического анализа синтаксических структур предложений. В целом морфологический анализ включает в себя следующие этапы [46]: 1) нормализация словоформ, имеющая вид лемматизации, т.е. сведения различных словоформ к некоторому единому представлению — к исходной форме (лемме) или стемминга, т.е. возведения разных словоформ к одной квазиоснове; 2) частеречный тэгинг, т.е. указание части речи для каждой словоформы в тексте; 3) полный морфологический анализ — приписывание грамматических характеристик словоформе. При синтаксическом анализе необходимо определить роли слов в предложении и их связи между собой. Результатом этого этапа автоматического анализа является представление синтаксических связей каждого предложения в виде моделей, например в виде дерева зависимостей. Проблемой синтаксического анализа выступает наличие альтернативных вариантов синтаксического разбора (синтаксической многозначности), ср.: три пальто —• (сколько?) три (чего?) пальто три пальто —• (что делай?) три (что?) пальто Возникновение синтаксической многозначности обусловливается лексико-морфологической многозначностью словоформ (одна и та же словоформа может восходить к различным исходным формам или к разным морфологическим формам одной лексемы), а также неоднозначностью самих правил разбора, которые могут иметь целью представление синтаксической структуры, например, в виде дерева непосредственных составляющих или дерева зависимостей. Так, предложение «Девочка мыла пол» описывается в первом случае моделью, представленной на рис. 4, а во втором — рис. 5. В модели непосредственно составляющих важно разбиение синтаксической структуры на пары ее элементов: предложение (S) разбивается на группу подлежащего (NP), представленную в данном случае одним существительным (N), и группу сказуемого (VP).
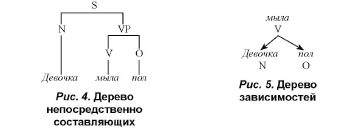
Вторая делится на изменяемый глагол (V) и дополнение (О). В дереве зависимостей исходным пунктом анализа выступает сказуемое (V). находящееся в вершине графа, от которого зависят подлежащее (N) и дополнение (О). В итоге в обоих типах анализа выделяются одни и те же синтаксические единицы — N, V и О — но синтаксические отношения между ними оказываются разными. Правда, в некоторых случаях на первый взгляд идентичная синтаксическая структура требует построения разных синтаксических моделей, ср. [3, 251]:
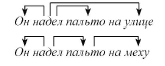
Чтобы выбрать правильную модель, отражающую синтаксические отношения в конкретном предложении, в подобных случаях необходимо привлечь семантику.
Чтобы выбрать правильную модель, отражающую синтаксические отношения в конкретном предложении, в подобных случаях необходимо привлечь семантику. Семантический анализ представляет собой, пожалуй, наиболее сложное направление автоматического анализа текста. В этом случае требуется установление семантических отношений между словами в тексте, объединение различных языковых выражений, относящихся к одному и тому же понятию, и т.п. Для семантического анализа предложений используются падежные грамматики и семантические падежи (валентности). В этом случае семантика предложения описывается через связи главного слова (глагола) с его семантическими актантами. Например, глагол передать описывается семантическими падежами дающего (агенса), адресата и объекта передачи [11, 96]. В основе семантического анализа лежит утверждение о том, что значение слова не является элементарной семантической единицей. Оно делится на более элементарные смыслы — единицы словаря семантического языка. Эти единицы семантического языка являются своеобразными атомами, из различных комбинаций которых складываются «молекулы» — значения реальных слов естественного языка [3, 254]. Например, если имеются элементарные смыслы «сам», «кто-то», «иметь», «заставлять», «переставать», «начинать» и «не», то с их помощью мы можем определить целую группу слов русского языка. Кроме семи названных слов, являющихся одновременно и элементами семантического языка, и словами русского языка, сюда относятся слова: 1) владеть = «иметь», 2) обладать = «иметь», 3) брать = «заставлять себя иметь», 4) давать = заставлять кого-то иметь» и т.д. [там же]. Именно семантический анализ позволяет решить проблемы многозначности (омонимии), возникающей при автоматическом анализе на всех языковых уровнях. • Лексическая омонимия: совпадение звучания и/или написания слов, не имеющих общих элементов смысла, например, рожа — лицо и вид болезни. • Морфологическая омонимия: совпадение форм одного и того же слова (лексемы), например, словоформа пол соответствует именительному и винительному падежам существительного пол. • Лексико-морфологическая омонимия (наиболее частый вид омонимии): совпадение словоформ двух разных лексем, например, мыла — глагол мыть в единственном числе женского рода прошедшего времени и существительное мыло в единственном числе, родительном падеже. • Синтаксическая омонимия: неоднозначность синтаксической структуры, имеющей несколько интерпретаций, например: Эти типы стали есть в цехе (словоформа стали может интерпретироваться как существительное или как глагол), Flying planes can be dangerous (известный пример Хомского, в котором словоформа Flying может интерпретироваться либо как прилагательное, либо как существительное) [11, 93—94]. Автоматический синтез представляет собой процесс производства связного текста, отдельные этапы которого являются теми же, что и при морфологическом анализе, но применяются в обратном порядке: сначала осуществляется семантический синтез, затем синтаксический, морфологический и графематический. Семантический синтез представляет собой переход от смысловой записи фразы к ее синтаксической структуре; синтаксический — переход от синтаксической структуры фразы к представляющей фразу цепочке лексико-грамматических характеристик словоформ; лексико-морфологический — переход от лексико-грамматической характеристики к реальной словоформе [27]. При морфологическом синтезе по нормальной форме слова и его параметрам программа находит соответствующую словоформу. Графематический синтез объединяет слова в единый текст, следит за соответствием фрагментов входного текста фрагментам выходного [21, 108]. Одной из первых компьютерных программ, синтезирующих письменный диалог на английском языке, явилась программа американского ученого Джозефа Вейценбаума «Элиза». Ее первый вариант был апробирован в 1966 году. Эта программа имитировала диалог с психотерапевтом, реализуя технику активного слушания. Программа была названа в честь Элизы Дулитл, героини из пьесы «Пигмалион» Бернарда Шоу, которую обучали языку «высшего класса людей». По сути, целью программы было не моделирование мышления в точном смысле, а моделирование речевого поведения, что было обусловлено ограниченными программными ресурсами, а также начальным уровнем лингвистического анализа и синтеза [4, 21]. Программа включала минимум лингвистической информации: 1) комплекс ключевых слов, которые актуализируют некоторые устойчивые речевые формулы, 2) способность трансформировать предыдущее высказывание в общий вопрос [там же]. Иллюстрацией работы программы «Элиза» выступает следующий фрагмент общения молодой женщины и программы «Элиза», опубликованный ее создателем Д. Вейценбаумом в 1966 г. Реплики, смоделированные программой, выделены прописными буквами. Men are all alike. IN WHAT WAY? They ‘re always bugging us about something or other. CAN YOU THINK OF A SPECIFIC EXAMPLE? Well, my boyfriend made me come here. YOUR BOYFRIEND MADE YOU COME HERE He says I’m depressed much of the time. I AM SORRY TO HEAR YOU ARE DEPRESSED It’s true. I am unhappy. DO YOU THINK COMING HERE WILL HELP YOU NOT TO BE UNHAPPY? I need some help, that much seems certain [цит. no: 57]. Несмотря на простоту алгоритмов, использованных в создании программы, с ее помощью практически удалось опровергнуть известный тест английского ученого Алана Тьюринга, предложенный в 1950 г. Сущность теста Тьюринга формулируется следующим образом: проблема создания искусственного интеллекта решена, если большинство участников общения не смогут установить, с кем они беседуют — с человеком или машиной. При проведении экспериментов с программой «Элиза» 62% испытуемых, которым было предложено определить, с кем они общаются, решили, что им отвечал человек [4, 21]. На современном этапе системы компьютерного моделирования письменных диалогов на естественном языке используют более сложные алгоритмы. В частности, создан специальный язык разметки для искусственного интеллекта AIML (Artificial Intelligence Markup Language), используемый для создания виртуальных агентов (или ботов). Боты, моделирующие диалог с собеседником, используются в компьютерных играх и на корпоративных веб-страницах, например, для ответов на вопросы пользователя о возможностях мобильного оператора или торговой сети
омпьютерная лексикография
Компьютерная лексикография представляет собой раздел прикладной лингвистики, нацеленный на создание компьютерных словарей, лингвистических баз данных и разработку программ поддержки лексикографических работ. Основными задачами традиционной и компьютерной лексикографии являются определение структуры словаря и зон словарной статьи, а также разработка принципов составления различных видов словарей. Словарь традиционно определяется как организованное собрание слов с комментариями, в которых описываются особенности структуры и/или функционирования этих слов [4, 55]. Электронный (автоматический, компьютерный) словарь — это собрание слов в специальном компьютерном формате, предназначенное для использования человеком или являющееся составной частью более сложных компьютерных программ (например, систем машинного перевода). Соответственно, различаются автоматические словари конечного пользователя-человека (АСКП) и автоматические словари для программ обработки текста (АСПОТ) [4, 86]. Автоматические словари, предназначенные для конечного пользователя, чаще всего являются компьютерными версиями хорошо известных обычных словарей, например: • Оксфордский словарь английского языка (www.oed.com), • автоматический толковый словарь английского языка издательства «Коллинз» (www.mycobuild.com), • автоматический вариант «Нового большого англо-русского словаря » под ред. Ю.Д. Апресяна и Э.М. Медниковой (http://eng-rus. slovaronline. com), • словарь Ожегова онлайн (http://slovarozhegova.ru). Автоматические словари такого типа практически повторяют структуру словарной статьи обычных словарей, однако они обладают функциями, недоступными своим прототипам, например, осуществляют сортировку данных по полям словарной статьи (ср. отбор всех прилагательных), проводят автоматический поиск всех вокабул, имеющих в толковании определенный семантический компонент, и т.д. [4, 86]. Пример статьи словаря такого типа представлен на рис. 6

Автоматические словари для систем машинного перевода, автоматического реферирования, информационного поиска и т.д. (АСПОТ) по интерфейсу и структуре словарной статьи существенно отличаются от АСКП. Особенности их структуры, сфера охвата словарного материала задаются теми программами, которые с ними взаимодействуют. Такой словарь может содержать от одной до сотни зон словарной статьи. Чрезвычайно разнообразны и области лексикографического описания: морфологическая, лексическая, синтаксическая, семантическая и т.д. [4, 86]. Структура традиционного словаря обычно включает следующие компоненты: • введение, объясняющее принципы пользования словарем и дающее информацию о структуре словарной статьи; • словник, включающий единицы словаря: морфемы, лексемы, словоформы или словосочетания; каждая такая единица с соответствующим комментарием представляет собой словарную статью; • указатели (индексы); • список источников; • список условных сокращений и алфавит [4, 75—76]. В электронных словарях из названных компонентов обязательным является, пожалуй, лишь словник, в онлайн-словарях нередко имеется также алфавит с заложенными за каждой буквой гиперссылками, ведущими к тексту словарной статьи. Практически в каждом электронном словаре, предлагаемом на диске (оффлайн-словарь) или в Интернете (онлайн-словарь) имеется функция автоматического поиска, позволяющая значительно экономить усилия пользователя при работе со словарем. Отличие электронных словарей от «бумажных» касается также их мультимедийности и гипертекстуальности: эти свойства выражены в электронных словарях в значительно большей степени, чем в печатных. Так, гиперссылки могут быть заложены за любым элементом словарной статьи или пунктом программного меню словаря. Это дает пользователю дополнительные возможности по поиску и быстрому переходу к необходимой словарной информации, позволяя найти синонимы и антонимы к заданному слову, слова той же семантической группы, парадигмы склонения и спряжения и т.д. Гиперссылки позволяют также легко связывать разные словари друг с другом, так что в итоге онлайн или оффлайн-словари оказываются коллекциями или порталами словарей. Получив необходимую информацию, например, о значении слова, пользователь одним нажатием ссылки может перейти к комментариям этого слова в других словарях и узнать особенности его толкования в специальных отраслях знания (терминологические словари) или получить дополнительную лингвистическую информацию о его форме. Отдельные электронные словари имеют также дополнительные возможности, например, электронный многоязычный словарь ABBYY Lingvo хЗ (© 2008 ABBYY) предоставляет функцию обучения (ABBYY Lingvo Tutor), позволяющую запоминать слова, отобранные по конкретной теме и представленные парами: русское и иностранное слово, составлять новые словари и словарные карточки, сохранять результаты обучения в файл и т.д. В итоге структура электронного словаря в значительной степени отличается от структуры словаря печатного, хотя основная часть словаря — словник со словарными статьями — продолжает составлять ядро словаря в обоих случаях. Структура словарной статьи достаточно типична и обычно включает следующие зоны словарной статьи, актуальные как для традиционной, так и для компьютерной лексикографии: • лексический вход (вокабула, лемма); • зона грамматической информации; • зона стилистических помет; • зона значения; • зона фразеологизмов; • зона этимологии; • зона примера и источника примера. Правда, можно выделить зоны словарной статьи, обязательные для всех словарных единиц, и факультативные зоны. Обязательной зоной словарной статьи для разных видов словарей является лишь лексический вход, все остальные зоны зависят от типа словаря: например, для толкового словаря необходима зона значения, а для орфоэпического она необязательна. Зона фразеологии отсутствует в комментариях слов, не используемых в устойчивых сочетаниях, а наличие зоны примера и его источника зависит от принципов, лежащих в основе создания словаря. Количество зон словарной статьи компьютерного словаря обычно превышает количество зон словарной статьи «бумажного» словаря, что обусловлено значительными ресурсами памяти и высокой скоростью обработки цифровой информации современными компьютерами. Но объем предлагаемой словарной информации должен соответствовать виду словаря: если читателю нужно произношение, то «лишняя» информация о переводе проверяемого слова или его контекстных значениях будет только мешать пользователю. Классификацию компьютерных словарей можно осуществлять на тех же принципах, что и классификацию обычных словарей. Традиционно выделяются лингвистические, энциклопедические и промежуточные (лингвострановедческие и терминологические) словари. В лингвистических словарях описываются сами слова — их значения, особенности употребления, структурные свойства, сочетаемость, соотношение с лексическими системами других языков и т.д. В энциклопедических словарях описываются понятия, факты и реалии окружающего мира, т.е. экстралингвистическая информация. Промежуточный тип словарей включает информацию и лингвистического, и экстралингвистического рода [4, 59—60]. Среди лингвистических словарей можно выделить несколько их видов [4, 59—74]: • толковые, имеющие целью толкование (объяснение) значений слов и их употребления в речи, включающие дескриптивные и нормативные словари, которые, кроме того, могут быть общими и частными, среди последних выделяются, например, фразеологические словари, словари иностранных слов и т.д.; • словари-тезаурусы, отличающиеся расположением словарной статьи, которое подчинено не алфавитному, а тематическому принципу, например, тезаурус русской идиоматики включает семантическое поле «УХОД, ОТЪЕЗД, БЕГСТВО», которое помещена в категорию «ДВИЖЕНИЕ», семантическое поле «ДАВНО» помещено в категорию «ВРЕМЯ» и т.д. [4, 65]; • двуязычные (переводные) словари, например, «Англо-русский словарь» В.К. Мюллера (1-е издание появилось в 1943 г.), «Французско- русский словарь активного типа» под ред. В.Г. Гака и Ж. Триомфа и др.; • ассоциативные словари, объектом которых является сфера ассоциативных отношений в лексике; словарная статья такого словаря включает лексему-стимул и список упорядоченных по частоте и алфавиту (с указанием частоты) реакций, полученных в психолингвистическом эксперименте, например: «Ассоциативный тезаурус современного русского языка» [39];
• исторические и этимологические словари, предоставляющие информацию об истории слов, начиная с определенной даты на протяжении некоторого периода, с указанием возникновения новых слов и значений, их отмирании и видоизменении, или объясняющие происхождение слов; • словари языковых форм, которые фиксируют особенности формы слов и в которых толкования значений отсутствуют или играют вспомогательную роль, например, орфографические и орфоэпические, словообразовательные и морфемные (показывают, как слова складываются из морфем и инвентаризуют их), грамматические (информация по каждому слову, позволяющая построить любую грамматически правильную форму), обратные словари; • словари речевого употребления: словари трудностей и сочетаемости слов; • ономастиконы: антропонимические словари и топонимические словари; • нетрадиционные, подвергающие словарному описанию нетипичные лингвистические объекты, например, «Словарь русских политических метафор» А.Н. Баранова и Ю.Н. Караулова [5], словари поэтических метафор, эпитетов, авторские словари и словари конкордансов. Например, известны такие электронные энциклопедии, как Энциклопедия Британника (www.britannica.com), «Большая энциклопедия Кирилла и Мефодия» (www.megabook.ru) и энциклопедия «Круго- свет» (www.krugosvet.ru). Примерами переводных электронных словарей выступают ABBYY Lingvo (www.lingvo.ru), Translatelt! (www.translateit.ru) и Multitran (www.multitran.ru). Электронные толковые словари — это, в частности, словарь Merriam Webster (www.merriam-webster.com) и словарь французского языка «Tresor de la langue francaise» (http://atilf. atilf.fr). Формальными электронными словарями являются орфографические словари русского (http://slovari.yandex.ru) и английского (www .spellcheckonline .com) языков. Большую коллекцию словарей разных видов на дисках и в Интернете предоставляет издательство Duden (немецкий язык, www. duden.de) и Larousse (французский язык, www.larousse.fr). Компьютерные словари обычно создаются на базе корпусов текстов с использованием средств автоматической обработки и поиска словарных единиц. Для этого привлекаются специальные программы — базы данных, компьютерные картотеки, программы обработки текста, которые позволяют автоматически формировать словарные статьи, хранить словарную информацию и обрабатывать ее. Так, создание электронного словаря, согласно А.Н. Баранову, включает следующие этапы [4, 84]: 1) формирование корпуса текстов и параллельно создание словника; 2) автоматическое формирование корпуса примеров; 3) написание словарных статей; 4) ввод словарных статей в базу данных (БД); 5) редактирование словарных статей в БД; 6) корректура текста в БД; 7) порождение текста словаря и формирование оригинал-макета; 8) печать словаря. Конечно, приведенное описание процесса создания электронного словаря может корректироваться в зависимости от его вида, исследовательских принципов и других факторов, ср. комментарии создателей электронного исторического словаря русского языка [48]. Но в любом случае использование компьютеров и уже готовых корпусов текстов в компьютерной лексикографии позволяет уменьшить количество этапов в процессе создания электронного словаря и сэкономить время практически на каждом из них. Так, вместо создания словарной карточки в компьютерной лексикографии используются базы данных. Записи баз данных дают возможность автоматически сортировать массив по выбранным параметрам, отбирать нужные примеры, объединять их в группы и т.д. Специализированных программных оболочек для лексикографических целей на рынке практически нет. Для этих целей вполне под- ходят современные базы данных типа ACCESS или PARADOX. Для поиска примеров создатели словарей могут использовать компьютерные программы построения конкордансов, например, DIALEX. Для создания оригинал-макета (верстки) словарей привлекаются издательские системы типа Page-Maker или WinWord, которые позволяют приписывать стили зонам словарных статей, алфавитизацию, создание указателей и т.д. [4, 82—85]. Пожалуй, единственный пример специализированной компьютерной программы, предназначенной для компьютерных лексикографических работ, является «Программа автоматизированного составления и обработки словников» (авторы: М.В. Литус, Е.В. Литус). Эта программа достаточно активно используется в филологических исследованиях и подробно представлена в учебном пособии А.Т. Хро- ленко и А.В. Денисова [52, 52—63]. Электронные словари имеют положительные стороны не только в процессе их создания, но и в процессе использования. В частности, выделяются следующие преимущества в использовании электронных словарей [40]: 1) электронные словари позволяют по-разному представить содержание словарной статьи (различные «проекции» словаря), в том числе с помощью разнообразных графических и мультимедийных средств, которые не используются в обычных словарях; 2) в выдаваемой информации находят отражение различные технологии компьютерной лингвистики, например морфологический и синтаксический анализ, полнотекстовый поиск, распознавание и синтез звука и т.п.; 3) становится возможным быстро получить информацию, которая содержится где-то в недрах словаря и непосредственно отвечает тому запросу, который сформулирован пользователем в удобной для него форме; 4) электронный словарь позволяет быстро реагировать на изменения в языке и мире, и выпуск каждой последующей его версии или внесение изменений в онлайн-версию не занимает много времени и труда. Несмотря на наличие значительного числа преимуществ использования электронных словарей, остаются нерешенными некоторые проблемы, актуальные как для традиционной, так и для компьютерной лексикографии. • В словарях должно найти отражение понятие лексической функции, позволяющее систематически описывать несвободную сочетаемость слов, иллюстрируемую следующими примерами русского языка: «войну ведут», а «экзамен — держат», «теории выдвигают », а «мысли подают» и т.п. • Не нашла отражение в массовой лексикографической практике проблема описания семантики и практической реализации грамматического словоизменения и словообразования. Каждый язык имеет свои собственные способы грамматического кодирования смысла, которые не описываются в массовых словарях систематически. Например, как передать по-английски смысл «довыпендриваться», даже если знаешь, как передать «выпендриваться»? • В словарях не существует даже системы понятий, с помощью которой синтаксическая информация могла бы быть доведена до обычного читателя. Решением этой проблемы могли бы стать интегральные словарные описания, основанные на формальных моделях, учитывающие прогрессивные лексикографические идеи. На этих же моделях следует организовать технологии доступа к словарному содержанию [40]. Названные проблемы могут быть решены при сотрудничестве лексикографов-теоретиков и практиков, а компьютерные инструменты, несомненно, облегчат рутинную работу по осуществлению монотонных лексикографических операций. В целом констатируем, что компьютерная лексикография, направленная на создание электронных словарей, представляет собой весьма перспективное и нужное направление компьютерной лингвистики, поскольку создаваемые ею продукты — электронные словари — отличаются многогранностью, мультимедийностью, интеграцией новейших технологических решений, актуальностью материала и отвечают потребностям пользователя в организации доступа к необходимой информации.
Список рекомендуемой литературы
1. Диалог: Международная русскоязычная конференция по компьютерной
лингвистике, http://dialog-21.ru
2. Лаборатория компьютерной лингвистики Института проблем передачи информации
РАН http://proling.iitp.ru/ru/node/l
3. Корпусная лингвистика. Машинный перевод. Прикладная лингвистика //
Фонд знаний «Ломоносов», http://www.lomonosov-mnd.ru/enc/ru/encyclopedia:
01206: article
4. Корпусная лингвистика: тематический сайт СП6ТУ и ИЛИ РАН. СПб., 2008.
http://corpora.iling.spb.ru
5. Информационные технологии в филологии // Викиверситет. http://ru.
wikiversity. о^^1кт/Информационные_технологии_в_филологии
6. Компьютерная лингвистика: научно-образовательный портал «Лингвистика
в России: ресурсы для исследователей», http://uisrussia.msu.ru/linguist/
_B_comput_ling.j sp
7. Прикладная лингвистика: портал «Единое окно доступа к образовательным
ресурсам», http://window.edu.ru/window/ catalog?p_rubr=2.2.73.12.15
8. Программы лингвистического анализа и обработки текста, http://asknet.ru/
Analytic s/programms. htm
9. Речевые технологии http://speech-soft.ru/index.php
10. Association for Computational Linguistics, http://www.aclweb.org
11. Cogprints: free software for Linguistics. University of Southampton, http://
cogprints. org/vie w/ subj ects/ling. html
12. Computational linguistics: MIT Press Journal, http://www.mitpressjournals.org/
loi/coli
13. Computer-Assisted Language Instruction Consortium. Texas State University.
14. GATES: free software. The University of Sheffield, 1995—2011. http://gate.ac.uk
15. Information and Communications Technology for Language Teachers (ICT4LT).
Slough, Thames Valley University, http://www.ict41t.org/en/en_home.htm
16. Institut fur Computerlinguistik an der Universitat Heidelberg. URL: http://www.
cl.uni-heidelberg.de
17. Language Technology World http://www.lt-world.org/
18. LINGUIST List. URL: http://lmguisthst.org
19. Stanford Engineering Everywhere (SEE): Artificial Intelligence. Stanford University,
1997—2009. http://see.stanford.edu/see/courses.aspx
Статьи к прочтению:
- Втоматический анализ и синтез звучащей речи этапы автоматического анализа речи.
- Вторая ступень рн sls block i .
Анализ текстов с помощью рекуррентных нейронных сетей | Глубокие нейронные сети на Python
Похожие статьи:
-
Втоматический анализ и синтез звучащей речи этапы автоматического анализа речи.
Одним из первых важных шагов использования информационных технологий в лингвистике является дигитализация текстов — переведение языкового материала,…
-
Так как в поле ввода может быть допущена ошибка, возможен ввод недопустимого значения. Прежде всего, программа анализирует выражение на отсутствие ошибок…