
Выражения и их составные части
Содержание
| стр. | |
| Введение | |
| Раздел 1 Структурное программирование | |
| Тема 1.1 Синтаксис языка С++ | |
| Тема 1.2 Стандартные типы данных | |
| Тема 1.3 Программа на языке С++ | |
| Тема 1.4 Ввод/вывод данных | |
| Тема 1.5 Выражения и их составные части | |
| Тема 1.6 Преобразование типов: неявное преобразование и преобразование «в стиле С» | |
| Тема 1.7 Операторы и их классификация | |
| Тема 1.8 Операторы ветвления | |
| Тема 1.9 Операторы цикла | |
| Тема 1.10 Операторы передачи управления | |
| Тема 1.11 Указатели | |
| Тема 1.12 Операции с указателями | |
| Тема 1.13 Ссылки | |
| Тема 1.14 Массивы | |
| Тема 1.15 Функции | |
| Тема 1.16 Параметры функции | |
| Тема 1.17 Перегрузка функций | |
| Тема 1.18 Шаблоны функций | |
| Тема 1.19 Работа со строками | |
| Тема 1.20 Потоки и доступ к файлам | |
| Тема 1.21 Пользовательские типы данных | |
| Тема 1.22 Динамические структуры данных | |
| Тема 1.23 Область действия идентификаторов | |
| Тема 1.24 Директивы препроцессора | |
| Раздел 2 Объектно-ориентированное программирование | |
| Тема 2.1 Введение в объектно-ориентированное программирование | |
| Тема 2.2 Описание классов и объектов класса | |
| Тема 2.3Указатель this | |
| Тема 2.4 Конструкторы | |
| Тема 2.5 Деструкторы | |
| Тема 2.6 Статические элементы класса | |
| Тема 2.7 Дружественные функции и классы | |
| Тема 2.8 Перегрузка операций | |
| Тема 2.9 Указатели на элементы классов | |
| Тема 2.10 Реализация с помощью классов динамических структур данных | |
| Тема 2.11 Шаблоны классов | |
| Тема 2.12 Наследование | |
| Тема 2.13 Виртуальные методы и абстрактные классы | |
| Тема 2.14 Множественное наследование | |
| Тема 2.15 Обработка исключительных ситуаций | |
| Тема 2.16 Преобразование типов: преобразование с помощью функций языка С++ | |
| Литература |
Введение
Данное учебное пособие содержит материал, предназначеный для обучения программированию на языке С++. Оно состоит из двух разделов: первый включает описание средств языка, используемых в рамках структурной парадигмы программирования, второй — в рамках объектной.
Данное учебное пособие может быть использовано преподавателями МДК.01.02 «Прикладное программирование» специальности 09.02.03 «Программирование в компьютерных системах» в качестве источника лекционного материала, а также студентами 2 и 3 курса данной специальности при подготовке к самостоятельным и лабораторным работам.
Учебное пособие должно использоваться совместно со сборником заданий для проведения самостоятельных работ по всем темам, рассмотренным в учебном пособии.
РАЗДЕЛ 1
СТРУКТУРНОЕ ПРОГРАММИРОВАНИЕ
Тема 1.1
Синтаксис языка С++
Алфавит языка С++ включает:
- прописные и строчные латинские буквы
- арабские цифры от 0 до 9
- знак подчеркивания
- специальные знаки: . , : ; ! ? + — * /= % \ |# ~ ^ ‘ { } [ ] ( )
- пробельные символы: пробел, символы табуляции и перехода на новую строку
Из символов алфавита формируются лексемыязыка:
- идентификаторы
- ключевые (зарезервированные) слова
- константы
- знаки операций
- разделители (скобки, точка, запятая, пробельные символы)
Границы лексем определяются разделителями и знаками операций.
Идентификатор – имя программного объекта (переменной, функции, типа). Он создается на этапе объявления программного объекта, после этого его можно использовать в последующих операторах программы.
В идентификаторе могут использоваться буквы, цифры и знак подчеркивания. Первым символом может быть буква или знак подчеркивания, но не цифра. Пробелы внутри имен не допускаются.
Прописные и строчные буквы различаются. Длина идентификатора по стандарту не ограничена, но некоторые компиляторы и компоновщики налагают на нее ограничения.
При выборе идентификатора необходимо иметь в виду следующее:
- идентификатор не должен совпадать с ключевыми словами и именами используемых стандартных объектов языка;
- не рекомендуется начинать идентификаторы с символа подчеркивания, т.к. они могут совпасть с именами системных функций или переменных, и, кроме того, это снижает мобильность программы;
- на имена внешних переменных, налагаются ограничения компоновщика.
Для улучшения читаемости программы следует давать объектам осмысленные имена. При этом можно придерживаться венгерской нотации, по которой каждое слово в составе идентификатора, начинается с прописной буквы, а вначале ставится префикс, соответствующий типу величины (iMaxLength). Также можно разделять слова знаками подчеркивания (max_length).
Ключевые слова – зарезервированные идентификаторы, имеющие специальное значение для компилятора. Их можно использовать только в том смысле, в котором они определены. Ниже приведен список ключевых слов:
asm dynamic_cast namespace switch volatile
auto else new mutable wchar_t
bool enum operator template while
break explicit private this
case export protected throw
catch extern public true
char false register try
class float reinterpret_cast typedef
const for return typeid
const_cast friend short typename
continue goto signed union
default if sizeof unsigned
delete inline static using
do int static_cast virtual
double long struct void
Константа – неизменяемая величина. Типы и форматы констант приведены в таблице 1.1.
Таблица 1.1 – Константы в языке C++
| Тип | Формат | Примеры |
| Целая | Десятичный: последовательность десятичных цифр, начинающаяся не с нуля, если это не число нуль. | 8, 0, 199226 |
| Восьмеричный: нуль, за которым следуют восьмеричные цифры (0 – 7). | 01, 020, 07155 | |
| Шестнадцатеричный: символы 0x или 0X, за которыми следуют шестнадцатеричные цифры (0 – 9, A, B, C, D, E, F). | 0xА, 0x1В8, 0X00FF | |
| Вещественная | Десятичный: [целая часть].[дробная часть] Может отсутствовать либо целая часть, либо дробная, но не обе сразу. | 5.7, .001, 35. |
| Экспоненциальный:[целая часть мантиссы][.][дробная часть мантиссы]{Е|е}[+|-][порядок] У мантиссы может отсутствовать целая часть, либо дробная, но не обе сразу. | 0.2Е6, .11е-3, 5Е10 | |
| Символьная | Один символ, заключенный в апострофы. | ‘А’, ‘ю’, ‘*’, ‘db’, ‘\0’, ‘\n’, ‘\012’, ‘\x07\x07’ |
| Строковая | Последовательность символов, заключенная в кавычки. | “Здесь был Vasia”, “\tЗначение r = \0xF5\n” |
Вещественная константа в экспоненциальном формате представляется в виде мантиссыи порядка.Мантисса записывается слева от знака экспоненты (Е или е), порядок – справа. Значение константы определяется как произведение мантиссы и числа 10, возведенного в указанную в порядке степень.
Отрицательные целые и вещественные константы предваряются знаком «-» (например: -218, -022, -0xЗС, -4.8, -0.1е4).
Пробелы внутри целых и вещественных констант не допускаются. Допустимый диапазон значений (объем занимаемой памяти) таких констант определяются их типом. Если тип явно не указан, компилятор определяет его по внешнему виду константы.
Символьные константы, состоящие из одного символа, занимают в памяти один байт и имеют стандартный тип char. Двухсимвольные константы занимают два байта и имеют тип int, при этом первый символ размещается в байте с меньшим адресом.
В конце строковых констант (строковых литералов) компилятор добавляет нуль-символ — управляющую последовательность ‘\0’(про управляющие последовательности будет рассказано ниже). Нуль-символ является признаком конца строки. Поэтому строковые константы занимают в памяти число байт на единицу большее, чем число символов. Строковый литерал из одного символа (например, “А”), и символьная константа (‘А’) имеют различный тип и длину. Пустая строка “” имеет длину 1 байт. Пустая символьная константа недопустима.
В строковых константах могут использоваться управляющие последовательности (escape-последовательности) – последовательности символов, начинающиеся с символа «\». Они интерпретируется как одиночный символ. В таблице 1.2 приведены допустимые значения управляющих последовательностей. Для других символов, следующих после знака \, результат не определен.
Таблица 1.2 — Управляющие последовательности в языке C++
| Последовательность | Наименование | |
| \а | Звуковой сигнал | Символы, не имеющие графического изображения |
| \b | Возврат на шаг | |
| \f | Перевод страницы | |
| \n | Перевод строки | |
| \r | Возврат каретки | |
| \t | Горизонтальная табуляция | |
| \v | Вертикальная табуляция | |
| \\ | Обратная косая черта | Символы, являющиеся специальными |
| \’ | Апостроф | |
| \” | Кавычка | |
| \? | Вопросительный знак | |
| \055 | Восьмеричный код символа | Обозначение символа его кодом |
| \0xdd | Шестнадцатеричный код символа |
Например, если внутри строки требуется записать кавычку, ее предваряют косой чертой, чтобы компилятор отличил ее от кавычки, ограничивающей строку: “Издательский дом \“Питер\””.
При отображении символа с помощью его кода числовое значение данного кода должно находиться в диапазоне от 0 до 255. Если в последовательности цифр встречается недопустимый символ, он считается концом цифрового кода.
Строковые константы, разделенные только пробельными символами, при компиляции объединяются в одну.
Длинную строковую константу можно разместить на нескольких строках, используя в качестве знака переноса обратную косую черту, за которой следует перевод строки. Эти символы игнорируются компилятором и следующая строка воспринимается как продолжение предыдущей.
Например, строка
“Никто не доволен своей \
внешностью, но все довольны \
своим умом”
полностью эквивалентна строке
“Никто не доволен своей внешностью, но все довольны своим умом”
Знак операции – один или более символов, определяющих действие над операндами. Знак операции может интерпретироваться по-разному в зависимости от контекста. Все знаки операций кроме [ ], ( ) и ? : представляют собой отдельные лексемы, внутри которых не допускаются пробелы.
По числу участвующих операндов операции делятся на унарные, бинарные и тернарную.
Большинство стандартных операций может быть перегружено (переопределено).
Программа на языке С++ может сопровождаться комментариями. Они игнорируются компилятором, поэтому внутри комментариев можно использовать не только символы из алфавита языка C++, но и любые другие символы допустимые на данном компьютере.
Комментарии бывают двух типов:
- начинающиеся с символов «//» и заканчивающиеся переходом на новую строку,
- заключенные между скобками /* */
Первый тип рекомендуется использовать для пояснений, второй – для временного исключения блоков кода при отладке. Вложенные комментарии-скобки не допускаются стандартом, но разрешены некоторых компиляторах.
Тема 1.2
Стандартные типы данных
Каждая константа, переменная, результат вычисления выражения или функции имеют конкретный тип, который определяет:
- внутреннее представление данных в памяти компьютера;
- машинные команды, используемые для обработки данных;
- множество значений, которые могут принимать величины данного типа;
- операции и функции, которые можно применять к величинам данного типа.
Обязательное описание типа позволяет компилятору производить проверку допустимости различных программных конструкций.
Типы данных языка C++ делятся на стандартные и составные. Стандартныетипы данных часто называют арифметическими,т.к. их можно использовать в арифметических операциях. Составные типы строятся на основе стандартных типов. К составным типам относятся массивы, перечисления, функции, структуры, ссылки, указатели, объединения и классы.
К стандартным типам языка С++ относятся:
- int (целый)
- bool (логический)
- char (символьный)
- wchar_t (расширенный символьный)
- float (вещественный)
- double (вещественный с двойной точностью)
Первые четыре типа называют целочисленными (целыми), последние два – типами с плавающей точкой. Компилятор формирует для их обработки различный код.
Перед типом для уточнения внутреннего представления и диапазона значений могут использоваться следующие спецификаторы:
- short (короткий)
- long (длинный)
- signed (знаковый)
- unsigned (беззнаковый)
Целый тип (int)
Размертипа int зависит от компьютера: для 16-разрядного процессора – это 2 байта, для 32-разрядного – 4 байта. Если используется спецификатор short (тип short int) под величину выделяется 2 байта независимо от разрядности процессора, если спецификатор long (тип long int) – 4 байта.
Внутреннее представлениевеличины целого типа – целое число в двоичном коде. Если используется спецификатор signed, старший бит числа интерпретируется как знаковый (0 – положительное число, 1 – отрицательное), если спецификатор unsigned – как часть кода числа (можно представлять только положительные числа).
По умолчанию все целочисленные типы считаются знаковыми (спецификатор signed можно опускать). Типы short int, long int, signed int и unsigned int можно сокращать до short, long, signed и unsigned соответственно.
Символьный тип (char)
Под величину типа char отводится количество байт, достаточное для размещения любого символа из набора символов компьютера. Для кодировки ASCII – это 1 байт. Величины типа char применяются также для хранения целых чисел, входящих в допустимый диапазон (от 0 до 255). Тип char, как и другие целые типы, может быть со знаком или без знака.
Расширенный символьный тип (wchar_t)
Тип wchar_t предназначен для работы с набором символов, для хранения которых необходимо 2 байта (например, кодировка Unicode). Строковые константы типа wchar_t записываются с префиксом L, например, L“Gates”.
Логический тип (bool)
Величины логического типа могут принимать только значения true и false (зарезервированные слова). Внутренняя форма представления величины типа bool – числа 1 и 0 соответственно. Под них выделяется 1 байт. При преобразовании целого числа к типу bool любое ненулевое значение интерпретируется как true, нулевое – как false.
Типы с плавающей точкой (float, double и long double)
Внутреннее представление вещественного числа состоит мантиссы и порядка. Мантисса – это число, большее 1.0, но меньшее 2.0. Поскольку старшая цифра мантиссы всегда равна 1, она не хранится.
Величины типа float занимают 4 байта (32 разряда): один двоичный разряд отводится под знак мантиссы, 23 – под мантиссу, 8 – под порядок.
Величины типа double занимают 8 байт (64 разряда): 11 и 52 разряда отводятся под порядок и мантиссу соответственно. Спецификатор long (тип long double) указывает, что под величину отводится 10 байт (80 разрядов): 11 и 68 разрядов под мантиссу и порядок соответсвенно.
Длина мантиссы определяет точность числа, а длина порядка – его диапазон. При одинаковом количестве байт, отводимом под величины типа float и long int, диапазоны их допустимых значений сильно различаются из-за внутренней формы представления (таблица 1.3).
Таблица 1.3 – Диапазоны значений стандартных типов данных для IBM PC
| Тип | Диапазон значений | Размер (байт) |
| bool | true и false | |
| signed char | -128 … 127 | |
| unsigned char | 0 … 255 | |
| signed short int | -32 768 … 32 767 | |
| unsigned short int | 0 … 65 535 | |
| signed long int | -2 147 483 648 … 2 147 483 647 | |
| unsigned long int | 0 … 4 294 967 295 | |
| float | 3.4e-38 … 3.4e+38 | |
| double | 1.7e-308 … 1.7c+308 | |
| long double | 3.4e-4932 … 3.4e+4932 |
В стандарте ANSI диапазоны значений для основных типов не задаются, определяются только соотношения между их размерами, например:
sizeof (float)sizeof (double)sizeof(long double)
sizeof (char)sizeof (short)sizeof (int)sizeof(long)
Минимальные и максимальные допустимые значения для целых типов приведены в заголовочном файле(), характеристики вещественных типов – в файле(), а также в шаблоне класса numeric_limits.
Тип void
К стандартным типам относится также тип void. Множество значений этого типа пусто. Он используется для определения функций, которые не возвращают значения, для указания пустого списка аргументов функции, как базовый тип для указателей и в операции приведения типов.
Типы констант
Константам приписывается тип в соответствии с их видом. Если этот тип не устраивает программиста, он может явно указать требуемый тип с помощью суффиксов.
Целые константы по умолчанию имеют тип int. Для целочисленных констант используются суффиксы L, l (long) и U, u (unsigned). Например, константа 32L будет иметь тип long и занимать 4 байта. Можно использовать суффиксы L и U одновременно (0x22UL или 05Lu).
Константы с плавающей точкой имеют по умолчанию тип double. Для вещественных констант используются суффиксы F, f (float) и L, l (long). Например, константа 2E+6L будет иметь тип long double, а константа 1.82f – тип float.
Тема 1.3
Программа на языке С++
Этапы создания программы на языке С++
Создание программ осуществляется с помощью систем программирования. Система программирования – это совокупность средств для автоматизации составления и отладки программ. На рисунке 1.1 представлена структура абстрактной компилирующей системы программирования и процесс разработки приложений в ней.
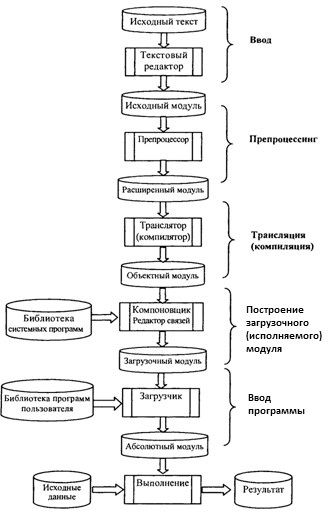
Рисунок 1.1 – Структура абстрактной компилирующей системы программирования и процесс разработки приложений в ней.
Исходный модуль-текстовый файл или раздел библиотеки на исходном языке.
Препроцессинг (препроцессорная обработка) — необязательная фаза, включающая анализ исходного текста, извлечение из него директив препроцессора и их выполнение.
Директивы препроцессора — помеченные специальными символами строки, содержащие символические обозначения конструкций, включаемых в состав исходной программы перед ее обработкой компилятором.
Трансляция – процесс, включающий синтаксический и семантический анализ, а также генерацию объектного кода в случае отсутствия ошибок.
Объектный модуль — текст программы на машинном языке, включающий машинные инструкции, словари, служебную информацию. Такой модуль не работоспособен, т.к. содержит неразрешенные ссылки на вызываемые подпрограммы библиотек, а также на другие программы пользователей или средства пакетов прикладных программ.
Если программа состоит из нескольких исходных файлов, они транслируются по отдельности и объединяются на этапе компоновки.
Компоновка – процесс объединения в единый загрузочный модуль всех объектных модулей, в том числе библиотек. Такой модуль после сборки помещается в файл или в качестве раздела в пользовательскую библиотеку.
Загрузочный модуль необходимо настроить и загрузить в оперативную память, а затем передать ему управление. Образ загрузочного модуля в памяти называется абсолютным модулем, т.к. все команды ЭВМ приобретают окончательную форму и получают абсолютные адреса в памяти.
Рисунке 1.2 иллюстрирует процесс построения исполняемого модуля для языка C++.
С помощью директив препроцессора в текст могут добавляться заголовочные (включаемые) файлы — текстовые файлы, в которых содержатся описания используемых в программе элементов.
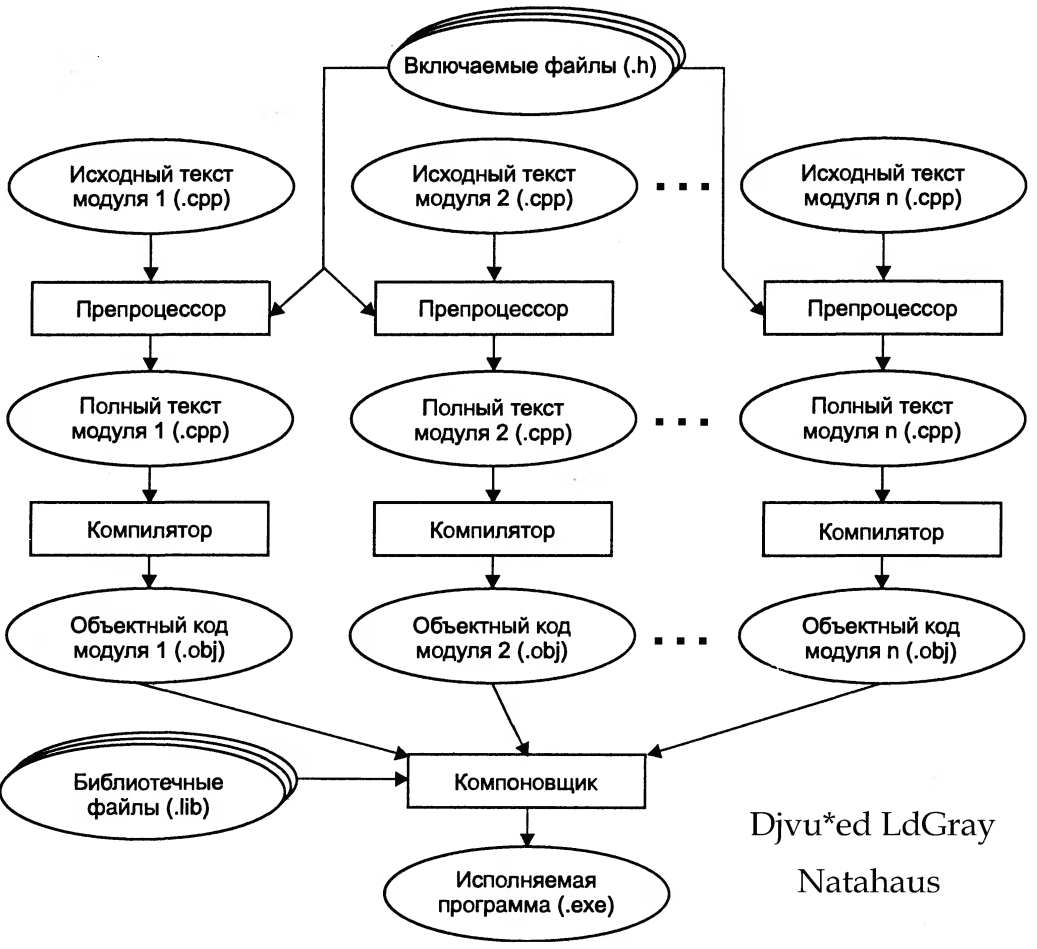
Рисунок 1.2 — Этапы создания исполняемой программы на C++
Структура программы на языке С++
Программа на языке C++ состоит из директив препроцессора, описания глобальных объектов и функций.
Директивы препроцессора управляют препроцессорной обработкой. Каждая директива располагается в отдельной строке и начинается с символа #. Этот символ должен быть первым отличным от пробела символом в строке с препроцессорной директивой.
Наиболее распространенной является директива #include, которая вставляет описания из указанного файла в текст программы, в ту точку, где эта директива записана. Данная директива имеет две формы записи:
#include
#include “имя_файла”
Имя файла может быть указано с расширением. Файлы с расширением .h, называются заголовочными файлами (header file).
В форме заголовочных файлов оформляются описания функций стандартных библиотек, а также описания типов и констант, используемых при работе с библиотеками компилятора. Например, заголовочный файл stdio.h содержит описание функции ввода/вывода printf, scanf и др. Каталог заголовочных файлов поставляется вместе со стандартными библиотеками компилятора.
Для подключения стандартных заголовочных файлов, используется первая форма записи: #include .
Программист может самостоятельно создать собственные заголовочные файлы, используя вторую форму записи.
Описание может выполняться в виде определения или объявления. Определения вводят функции и объекты (переменные и константы). Объекты хранят обрабатываемые данные, функции определяют выполняемые действия. Объявления лишь уведомляют компилятор о свойствах и именах тех объектов и функций, которые будут определены в других частях программы (ниже по тексту или в другом файле).
Простейшее определение функции имеет вид:
тип имя ([параметры]) {
тело функции
}
Указанный тип является типом значения, вычисляемого функцией. Если функция не должна возвращать значение, указывается тип void. Тело функции задает выполняемые функцией действия и состоит из исполняемых операторов, а также локальных описаний объектов.
В программе обязательно должна быть определена главная функция с именем main. Выполнение программы начинается с первого ее оператора. Она запускается командами операционной системы, возвращаемое ей значение также передается операционной системе. Для функции main указывается либо тип void (тогда операционная система не будет анализировать результат выполнения программы), либо тип int. По умолчанию функция main возвращает значение типа int.
Описания и определения, записанные вне функции main, называются глобальными.
Тема 1.4
Ввод/вывод данных
В языке C++ ввод/вывод осуществляется с помощью функций стандартной библиотеки одним из двух способов: с помощью функций, унаследованных из языка С, или с помощью потоков ввода/вывода С++.
Ввод-вывод в стиле С (форматированный)
Форматированный вывод на экран осуществляется с помощью функции printf. Оператор ее вызова имеет следующую структуру:
printf (форматная_строка, список_аргументов);
Форматная строка – это выводимая на экран строковая константа (ограничена двойными кавычками), включающая в себя произвольный текст, управляющие символы и спецификаторы формата. Список аргументов и спецификаторы формата могут отсутствовать.
На место спецификаторов формата помещаются в соответствующем порядке элементы из списка аргументов (соответствие устанавливается в порядке их записи слева направо). Список аргументов состоит в общем случае из выражений, в частном случае – из констант и переменных.
Спецификатор формата определяет форму внешнего представления выводимой величины и начинаются со знака %. Наиболее распространенными спецификаторами являются:
%с – символ;
%s – строка;
%d и %i – целое десятичное число (тип int);
%u – целое десятичное число без знака (тип unsigned);
%f – вещественное число в форме с фиксированной точкой;
%е и %E – вещественное число в форме с плавающей точкой.
Перед спецификаторами могут использоваться префиксы l (long) и h (short):
%ld – число типа long int;
%hd – число типа short int;
%lf – число типа long double.
Пример:
float m,p;
int k;
m = 84.3;
k = -12;
p = 32.15;
printf (m=%f\tk=%d\tp=%e, m,k,p);
На экран выведется строка:
m=84.299999 k=-12 p=3.21500e+01
Управляющий символ табуляции \t разделяет выводимые значения.
К спецификатору формата могут быть добавлены числовые параметры: ширина поляи точность.Ширина – это число позиций, отводимых на экране под величину, а точность – число позиций под дробную часть. Параметры записываются между значком % и символом формата и отделяются друг от друга точкой.
Внесем изменения в оператор вывода для рассмотренного выше примера:
printf(m=%5.2f\tk=%5d\tp=%11.4е, m,k,p);
В результате на экране получим:
m=84.30 k= -12 р= 3.2150е+01
Если выводимое значение не помещается в пределы указанной ширины поля, то этот параметр игнорируется, и величина выводится полностью.
Для форматированного ввода данных с клавиатуры предназначена функция scanf. Она осуществляет чтение символов, вводимых с клавиатуры, и преобразование их во внутреннее представление в соответствии с типом величин. Оператор вызова данной функции имеет следующую структуру:
scanf (форматная_строка, список_аргументов) ;
В функции scanf( ) форматная строка и список аргументов присутствуют обязательно. Список аргументов – это перечень вводимых переменных (перед именем каждой из них ставится знак ).
Символьная последовательность, вводимая с клавиатуры, называется входным потоком.Функция scanf разделяет этот поток на отдельные величины и интерпретирует их в соответствии с заданным типом и форматом и присваивает переменным, указаным в списке аргументов.
Разделителем между значениями в потоке ввода может быть любое количество пробелов, знак табуляции, конец строки. После нажатия на клавишу Enter вводимые значения присвоятся соответствующим переменным. До этого входной поток помещается в буфер клавиатуры и может редактироваться.
Форматная строка заключается в двойные кавычки и состоит из cпецификаций, начинающихся со знака %, после которого могут следовать
*[ширина поля] [модификатор] спецификатор
Обязательным элементом является лишь спецификатор. Значения спецификаторов и модификаторов, аналогичны используемым для функции printf. Ширина поля – целое положительное число, задающее число символов из входного потока, принадлежащих значению соответствующей вводимой переменной. Оставшиеся символы игнорируются. Звездочка позволяет пропустить во входном потоке определенное количество символов.
Для использования в программе функций printf() и scanf() необходимо включить в текст программы заголовочный файл stdio.h, содержащий описание данных функций.
Пример:
#include
int i, j;
void main ( ) {
printf (“Введите два целых числа\n”);
scanf (“%d%d”, i, j);
printf (“Вы ввели числа %d и %d”, i, j);
}
Первая строка содержит директиву препроцессора для включения в текст программы заголовочного файла stdio.h. Во второй строке описываются глобальные целые переменные i и j. Третья строка представляет собой заголовок главной функции. Функция printf в четвертой строке выводит на экран текст «Введите два целых числа» и переводит курсор на новую строку в соответствии с управляющей последовательностью \n. Функция scanf в пятой строке заносит введенные с клавиатуры целые числа в переменные i и j. Функция printf в шестой строке выводит на экран указанную форматную строку, заменив спецификации на значение введенных чисел.
Потоковый ввод-вывод
В С++ для ввода/вывода используются стандартные символьные потоки: cin – поток ввода с клавиатуры и cout – поток вывода на экран. Ввод данных интерпретируется как извлечение из потокаcin и присваивание значений соответствующим переменным. Знак операции извлечения из стандартного потока . Вывод данных интерпретируется как помещениев поток coutвыводимых значений. Знак операции помещения в поток
Для использования стандартных потоков cin и cout необходимо включить в текст программы заголовочный файл iostream.h.
Пример:
#include
void main ( ) {
int i, j;
cout
cinij;
cout
}
Знаки операцийи
В процессе потокового ввода/вывода происходит преобразование из формы внешнего символьного представления во внутренний формат и обратно. Тип данных и необходимый формат определяются автоматически. Стандартные форматы задаются специальными флагами форматирования. Кроме того, на формат отдельных выводимых данных можно влиять путем применения манипуляторов.
Тема 1.5
Выражения и их составные части
Выражения используются для вычисления в программе некоторого значения определенного типа. Они состоят из операндов, знаков операций и скобок.
Операнды задают данные для вычислений. Каждый операнд является, в свою очередь, выражением или одним из его частных случаев — константой или переменной.
Операции задают действия, которые необходимо выполнить.
Операции выполняются в соответствии с приоритетами. Для изменения порядка выполнения операций используются круглые скобки.
После каждого выражения в программе ставится точка с запятой.
Рассмотрим составные части выражений и правила их вычисления.
Переменные
Переменная — это именованная область памяти, в которой хранятся данные определенного типа. Обращение к области памяти осуществляется по имени переменной. Значение переменной может быть изменено во время выполнения программы.
Оператор описания переменной имеет вид:
[класс памяти] [const] тип имя [инициализатор]
Необязательный класс памяти может принимать одно из значений auto, extern, static и register.
Модификатор const показывает, что значение переменной изменять нельзя. Такую переменную называют именованной константой, или просто константой.
При описании можно выполнить инициализацию переменой — присвоить ей начальное значение.Инициализатор можно записывать в двух формах:
- со знаком равенства — имя = значение
- в круглых скобках — имя ( значение )
Константадолжна быть инициализирована при объявлении.
В одном операторе можно описать несколько переменных одного типа, разделяя их запятыми.
Примеры:
short int а = 1; // целая переменная а
const char С = ‘С’; // символьная константа С
char s, sf = ‘f’; // инициализация относится только к sf
char t(54);
float с = 0.22, x(3), sum;
Если тип инициализирующего значения не совпадает с типом переменной, выполняются преобразования типа.
Описание переменной, кроме типа и класса памяти, явно или по умолчанию задает ее область действия.Класс памяти и область действия зависят не только от собственно описания, но и от места его размещения в тексте программы.
Область действия идентификатора — это часть программы, в которой его можно использовать для доступа к связанной с ним области памяти.
В зависимости от области действия переменная может быть локальной или глобальной.
Если переменная определена внутри блока, она называется локальной,область ее действия — от точки описания до конца блока, включая все вложенные блоки.
Если переменная определена вне любого блока, она называется глобальнойи областью ее действия считается файл, в котором она определена, от точки описания до его конца.
Класс памятиопределяет время жизни и область видимости программного объекта. Если класс памяти не указан явным образом, он определяется компилятором исходя из контекста объявления.
Время жизниможет быть постоянным (в течение выполнения программы) и временным (в течение выполнения блока).
Областью видимости идентификатораназывается часть текста программы, из которой допустим обычный доступ к связанной с идентификатором области памяти.
Чаще всего область видимости совпадает с областью действия. Исключением является ситуация, когда во вложенном блоке описана переменная с таким же именем. В этом случае внешняя переменная во вложенном блоке невидима, хотя он и входит в ее область действия. Тем не менее, к этой переменной, если она глобальная, можно обратиться, используя операцию доступа к области видимости ::.
Для задания класса памятииспользуются следующие спецификаторы:
auto — автоматическаяпеременная. Память под нее выделяется в стеке и при необходимости инициализируется каждый раз при выполнении оператора, содержащего ее определение. Освобождение памяти происходит при выходе из блока, в котором описана переменная. Время ее жизни — с момента описания до конца блока. Для глобальных переменных этот спецификатор не используется, а для локальных он принимается по умолчанию, поэтому задавать его явным образом большого смысла не имеет.
extern — внешняя переменная, которая определяется в другом месте программы (в другом файле или дальше по тексту). Используется для создания переменных, доступных во всех модулях программы, в которых они объявлены. Если переменная в том же операторе инициализируется, спецификатор extern игнорируется.
static — статическаяпеременная. Время жизни — постоянное. Инициализируется один раз при первом выполнении оператора, содержащего определение переменной. В зависимости от расположения оператора описания статические переменные могут быть глобальными и локальными. Глобальные статические переменные видны только в том модуле, в котором они описаны.
register — аналогично auto, но память выделяется по возможности в регистрах процессора. Если такой возможности у компилятора нет, переменные обрабатываются как auto.
Пример:
int a; // 1 глобальная переменная а
int main( ){
int b; // 2 локальная переменная b
extern int x; // 3 переменная х определена в другом месте
static int с; // 4 локальная статическая переменная с
а = 1; // 5 присваивание глобальной переменной
int a; // 6локальная переменная а
а = 2; // 7присваивание локальной переменной
::а = 3; // 8 присваивание глобальной переменной
return 0;
}
int x = 4; // 9определение и инициализация х
В этом примере глобальная переменная a определена вне всех блоков. Память под нее выделяется в сегменте данных в начале работы программы, областью действия является вся программа. Область видимости — вся программа, кроме строк 6-8, так как в первой из них определяется локальная переменная с тем же именем, область действия которой начинается с точки ее описания и заканчивается при выходе из блока.
Переменные b и с — локальные, область их видимости — блок, но время жизни различно: память под b выделяется в стеке при входе в блок и освобождается при выходе из него, а переменная с располагается в сегменте данных и существует все время, пока работает программа.
Если при определении начальное значение переменных явным образом не задается, компилятор присваивает глобальным и статическим переменным нулевое значение соответствующего типа. Автоматические переменные не инициализируются.
Имя переменной должно быть уникальным в своей области действия (например, в одном блоке не может быть двух переменных с одинаковыми именами).
Имя должно отражать смысл хранимой величины, быть легко распознаваемым и, желательно, не содержать символов, которые можно перепутать друг с другом, например, 1, l (строчная L) или I (прописная i). Для разделения частей имени можно использовать знак подчеркивания. Как правило, переменным с большой областью видимости даются более длинные имена (желательно с префиксом типа), а для переменных, вся жизнь которых проходит на протяжении нескольких строк исходного текста, хватит и одной буквы с комментарием при объявлении.
Описание переменной может выполняться в форме объявления или определения.Объявлениеинформирует компилятор о типе переменной и классе памяти, а определениесодержит, кроме этого,указание компилятору выделить память в соответствии с типом переменной. В C++ большинство объявлений являются одновременно и определениями. В приведенном выше примере только описание 3 является объявлением, но не определением.
Переменная может быть объявлена многократно, но определена только в одном месте программы, поскольку объявление просто описывает свойства переменной, а определение связывает ее с конкретной областью памяти.
Операции
По числу операндов операции делятся на унарные (один операнд), бинарные (два операнда) и тернарную (три операнда). Рассмотрим основные операции подробнее.
Операции инкремента (увеличения на 1) ++ и декремента (уменьшения на 1) —
Эти операции имеют две формы записи — префиксную,когда операция записывается перед операндом, и постфиксную — когда после операнда.В префиксной форме сначала изменяется операнд, а затем его значение становится результирующим значением выражения. В постфиксной форме значением выражения является исходное значение операнда, после чего он изменяется.
Пример:
#include
int main( ){
int x = 3, у = 3;
printf (“Значение префиксного выражения: %d\n”, ++x);
printf (“Значение постфиксного выражения: %d\n”, y++);
printf (“Значение х после приращения: %d\n”, x);
printf (“Значение у после приращения: %d\n, у);
return 0;
}
Результат работы программы:
Значение префиксного выражения: 4
Значение постфиксного выражения: 3
Значение х после приращения: 4
Значение у после приращения: 4
Операндом операций инкремента и декремента в общем случае является так называемое L-значение (L-value).Так обозначается любое выражение, адресующее некоторый участок памяти, в который можно занести значение. Название произошло от операции присваивания, поскольку именно ее левая (Left) часть определяет, в какую область памяти будет занесен результат операции. Переменная является частным случаем L-значения.
Статьи к прочтению:
Математика 5 класс. 8 октября. Числовые и буквенные выражения
Похожие статьи:
-
Библиографическая запись составной части электронного ресурса
Дата введения 2002—07—01 1 Область применения Настоящий стандарт устанавливает общие требования и правила составления библиографического описания…
-
Схема базы данных, понятие и составные части. понятие о метаданных.
Базовые понятия реляционной организации данных. Э.Кодд (Kodd E.F.) предложил использовать для обработки данных аппарат теории множеств(объединение,…