
Алгоритмы создания цепочек
Первая задача, с которой мы столкнемся при шифровании данных криптоалгоритмом – это данные с длиной, неравной длине 1 блока криптоалгоритма. Эта ситуация будет иметь место практически всегда.
Первый вопрос:
– Что можно сделать, если мы хотим зашифровать 24 байта текста, если используется криптоалгоритм с длиной блока 8 байт?
– Последовательно зашифровать три раза по 8 байт и сложить их в выходной файл так, как они лежали в исходном.
– А если данных много и некоторые блоки по 8 байт повторяются, это значит, что в выходном файле эти же блоки будут зашифрованы одинаково — это очень плохо.
Второй вопрос :
– А что если данных не 24, а 21 байт.
Не шифровать последние 5 байт или чем-то заполнять еще 3 байта, – а потом при дешифровании их выкидывать.
– Первый вариант вообще никуда не годится, а второй применяется, но чем заполнять ?
Для решения этих проблем и были введены в криптосистемы алгоритмы создания цепочек (англ. chaining modes). Самый простой метод мы уже в принципе описали. Это метод ECB (Electronic Code Book). Шифруемый файл временно разделяется на блоки, равные блокам алгоритма, каждый из них шифруется независимо, а затем из зашифрованных пакетов данных компонуется в той же последовательности файл, который отныне надежно защищен криптоалгоритмом. Название алгоритм получил из-за того, что в силу своей простоты он широко применялся в простых портативных устройствах для шифрования – электронных шифрокнижках. Схема данного метода приведена на рис.1.
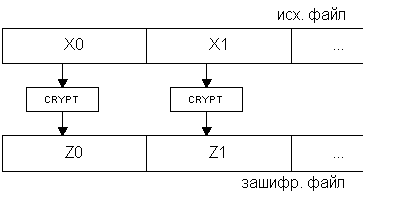
Рис.1.
В том случае, когда длина пересылаемого пакета информации не кратна длине блока криптоалгоритма возможно расширение последнего (неполного) блока байт до требуемой длины либо с помощью генератора псевдослучайных чисел, что не всегда безопасно в отношении криптостойкости, либо с помощью хеш-суммы передаваемого текста. Второй вариант более предпочтителен, так как хеш-сумма обладает лучшими статистическими показателями, а ее априорная известность стороннему лицу равносильна знанию им всего передаваемого текста.
Указанным выше недостатком этой схемы является то, что при повторе в исходном тексте одинаковых символов в течение более, чем 2*N байт (где N – размер блока криптоалгоритма), в выходном файле будут присутствовать одинаковые зашифрованные блоки. Поэтому, для более мощной защиты больших пакетов информации с помощью блочных шифров применяются несколько обратимых схем создания цепочек. Все они почти равнозначны по криптостойкости, каждая имеет некоторые преимущества и недостатки, зависящие от вида исходного текста.
Все схемы создания цепочек основаны на идее зависимости результирующего зашифровываемого блока от предыдущих, либо от позиции его в исходном файле. Это достигается с помощью блока памяти – пакета информации длины, равной длине блока алгоритма. Блок памяти (к нему применяют термин IV – англ. Initial Vector) вычисляется по определенному принципу из всех прошедших шифрование блоков, а затем накладывается с помощью какой-либо обратимой функции (обычно XOR) на обрабатываемый текст на одной из стадий шифрования. В процессе раскодирования на приемной стороне операция создания IV повторяется на основе принятого и расшифрованного текста, вследствие чего алгоритмы создания цепочек полностью обратимы.
Два наиболее распространенных алгоритма создания цепочек – CBC и CFB. Их структура приведена на рис.2 и рис.3. Метод CBC получил название от английской аббревиатуры Cipher Block Chaining – объединение в цепочку блоков шифра, а метод CFB – от Cipher FeedBack – обратная связь по шифроблоку.
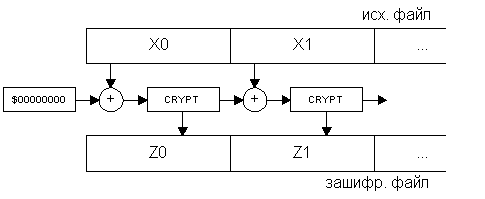
Рис.2.
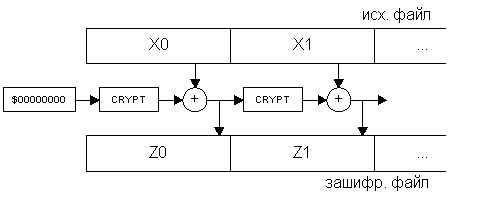
Рис.3.
Еще один метод OFB (англ. Output FeedBack – обратная связь по выходу) имеет несколько иную структуру (она изображена на рис.4.) : в нем значение накладываемое на шифруемый блок не зависит от предыдущих блоков, а только от позиции шифруемого блока (в этом смысле он полностью соответствует скремблерам), и из-за этого он не распространяет помехи на последующие блоки. Очевидно, что все алгоритмы создания цепочек однозначно восстановимы. Практические алгоритмы создания и декодирования цепочек будут разработаны на практическом занятии.
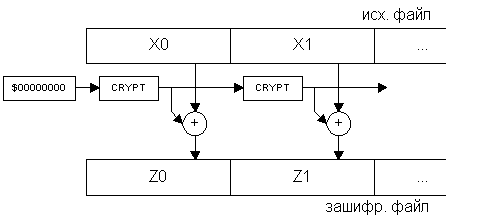
Рис.4.
Сравним характеристики методов создания цепочек в виде таблицы.
| Метод | Шифрование блока зависит от | Искажение одного бита при передаче | Кодируется ли некратное блоку число байт без дополнения? | На выход криптосистемы поступает |
| ECB | текущего блока | портит весь текущий блок | нет | выход криптоалгоритма |
| CBC | всех предыдущих блоков | портит весь текущий и все последующие блоки | нет | выход криптоалгоритма |
| CFB | всех предыдущих блоков | портит один бит текущего блока и все последующие блоки | да | XOR маска с исходным текстом |
| OFB | позиции блока в файле | портит только один бит текущего блока | да | XOR маска с исходным текстом |
Хеширование паролей
От методов, повышающих криптостойкость системы в целом, перейдем к блоку хеширования паролей – методу, позволяющему пользователям запоминать не 128 байт, то есть 256 шестнадцатиричных цифр ключа, а некоторое осмысленное выражение, слово или последовательность символов, называющуюся паролем. Действительно, при разработке любого криптоалгоритма следует учитывать, что в половине случаев конечным пользователем системы является человек, а не автоматическая система. Это ставит вопрос о том, удобно, и вообще реально ли человеку запомнить 128-битный ключ (32 шестнадцатиричные цифры). На самом деле предел запоминаемости лежит на границе 8-12 подобных символов, а, следовательно, если мы будем заставлять пользователя оперировать именно ключом, тем самым мы практически вынудим его к записи ключа на каком-либо листке бумаги или электронном носителе, например, в текстовом файле. Это, естественно, резко снижает защищенность системы.
Для решения этой проблемы были разработаны методы, преобразующие произносимую, осмысленную строку произвольной длины – пароль, в указанный ключ заранее заданной длины. В подавляющем большинстве случаев для этой операции используются так называемые хеш-функции (от англ. hashing – мелкая нарезка и перемешивание). Хеш-функцией называется такое математическое или алгоритмическое преобразование заданного блока данных, которое обладает следующими свойствами:
- хеш-функция имеет бесконечную область определения,
- хеш-функция имеет конечную область значений,
- она необратима,
- изменение входного потока информации на один бит меняет около половины всех бит выходного потока, то есть результата хеш-функции.
Эти свойства позволяют подавать на вход хеш-функции пароли, то есть текстовые строки произвольной длины на любом национальном языке и, ограничив область значений функции диапазоном 0..2N-1, где N – длина ключа в битах, получать на выходе достаточно равномерно распределенные по области значения блоки информации – ключи.
Нетрудно заметить, что требования, подобные 3 и 4 пунктам требований к хеш-функции, выполняют блочные шифры. Это указывает на один из возможных путей реализации стойких хеш-функций – проведение блочных криптопреобразований над материалом строки-пароля. Этот метод и используется в различных вариациях практически во всех современных криптосистемах. Материал строки-пароля многократно последовательно используется в качестве ключа для шифрования некоторого заранее известного блока данных – на выходе получается зашифрованный блок информации, однозначно зависящий только от пароля и при этом имеющий достаточно хорошие статистические характеристики. Такой блок или несколько таких блоков и используются в качестве ключа для дальнейших криптопреобразований.
Характер применения блочного шифра для хеширования определяется отношением размера блока используемого криптоалгоритма и разрядности требуемого хеш-результата.
Если указанные выше величины совпадают, то используется схема одноцепочечного блочного шифрования. Первоначальное значение хеш-результата H0 устанавливается равным 0, вся строка-пароль разбивается на блоки байт, равные по длине ключу используемого для хеширования блочного шифра, затем производятся преобразования по реккурентной формуле:
Hj=Hj-1 XOR EnCrypt(Hj-1,PSWj),
где EnCrypt(X,Key) – используемый блочный шифр (рис.1).
Последнее значение Hk используется в качестве искомого результата.
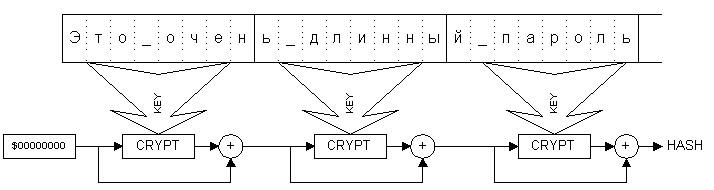
Рис.1.
В том случае, когда длина ключа ровно в два раза превосходит длину блока, а подобная зависимость довольно часто встречается в блочных шифрах, используется схема, напоминающая сеть Фейштеля. Характерным недостатком и приведенной выше формулы, и хеш-функции, основанной на сети Фейштеля, является большая ресурсоемкость в отношении пароля. Для проведения только одного преобразования, например, блочным шифром с ключом длиной 128 бит используется 16 байт строки-пароля, а сама длина пароля редко превышает 32 символа. Следовательно, при вычислении хеш-функции над паролем будут произведено максимум 2 полноценных криптопреобразования.
Решение этой проблемы можно достичь двумя путями : 1) предварительно размножить строку-пароль, например, записав ее многократно последовательно до достижения длины, скажем, в 256 символов; 2) модифицировать схему использования криптоалгоритма так, чтобы материал строки-пароля медленнее тратился при вычислении ключа.
По второму пути пошли исследователи Девис и Майер, предложившие алгоритм также на основе блочного шифра, но использующий материал строки-пароля многократно и небольшими порциями. В нем просматриваются элементы обеих приведенных выше схем, но криптостойкость этого алгоритма подтверждена многочисленными реализациями в различных криптосистемах. Алгоритм получил название Tandem DM (рис.2):
G0=0; H0=0 ;FOR J = 1 TO N DO BEGIN TMP=EnCrypt(H,[G,PSWj]); H’=H XOR TMP; TMP=EnCrypt(G,[PSWj,TMP]); G’=G XOR TMP; END;Key=[Gk,Hk]
Квадратными скобками (X16=[A8,B8]) здесь обозначено простое объединение (склеивание) двух блоков информации равной величины в один – удвоенной разрядности. А в качестве процедуры EnCrypt(X,Key) опять может быть выбран любой стойкий блочный шифр. Как видно из формул, данный алгоритм ориентирован на то, что длина ключа двукратно превышает размер блока криптоалгоритма. А характерной особенностью схемы является тот факт, что строка пароля считывается блоками по половине длины ключа, и каждый блок используется в создании хеш-результата дважды. Таким образом, при длине пароля в 20 символов и необходимости создания 128 битного ключа внутренний цикл хеш-функции повторится 3 раза.
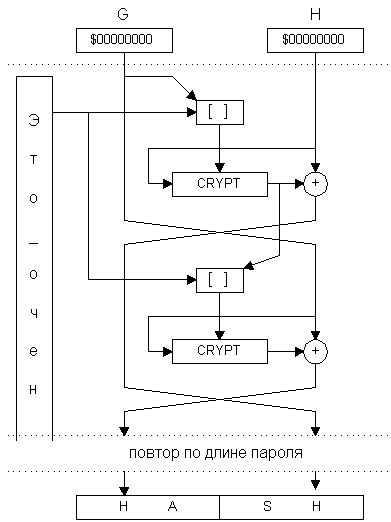
Рис.2.
Транспортное кодирование
Поскольку системы шифрования данных часто используются для кодирования текстовой информации : переписки, счетов, платежей электронной коммерции, и при этом криптосистема должна быть абсолютно прозрачной для пользователя, то над выходным потоком криптосистемы часто производится транспортное кодирование, то есть дополнительное кодирование (не шифрование !) информации исключительно для обеспечения совместимости с протоколами передачи данных.
Все дело в том, что на выходе криптосистемы байт может принимать все 256 возможных значений, независимо от того был ли входной поток текстовой информацией или нет. А при передаче почтовых сообщений многие системы ориентированы на то, что допустимые значения байтов текста лежат в более узком диапазоне : все цифры, знаки препинания, алфавит латиницы плюс, возможно, национального языка. Первые 32 символа набора ASCII служат для специальных целей. Для того, чтобы они и некоторые другие служебные символы никогда не появились в выходном потоке используется транспортное кодирование.
Наиболее простой метод состоит в записи каждого байта двумя шестнадцатиричными цифрами-символами. Так байт 252 будет записан двумя символами ‘FC’; байт с кодом 26, попадающий на специальный символ CTRL-Z, будет записан двумя допустимыми символами ‘1A’. Но эта схема очень избыточна : в одном байте передается только 4 бита информации.
На самом деле практически в любой системе коммуникации без проблем можно передавать около 68 символов (латинский алфавит строчный и прописной, цифры и знаки препинания). Из этого следует, что вполне реально создать систему с передачей 6 бит в одном байте (26
Процесс кодирования преобразует 4 входных символа в виде 24-битной группы, обрабатывая их слева направо. Эти группы затем рассматриваются как 4 соединенные 6-битные группы, каждая из которых транслируется в одиночную цифру алфавита base64. При кодировании base64 входной поток байтов должен быть упорядочен старшими битами вперед.
Каждая 6-битная группа используется как индекс для массива 64-х печатных символов. Символ, на который указывает значение индекса, помещается в выходную строку. Эти символы выбраны так, чтобы быть универсально представимыми и исключают символы, имеющие специальное значение (., CR, LF).
Алфавит Base64 Значение Код Значение Код Значение Код Значение Код 0 A 17 R 34 i 51 z 1 B 18 S 35 j 52 0 2 C 19 T 36 k 53 1 3 D 20 U 37 l 54 2 4 E 21 V 38 m 55 3 5 F 22 W 39 n 56 4 6 G 23 X 40 o 57 5 7 H 24 Y 41 p 58 6 8 I 25 Z 42 q 59 7 9 J 26 a 43 r 60 8 10 K 27 b 44 s 61 9 11 L 28 c 45 t 62 + 12 M 29 d 46 u 63 / 13 N 30 e 47 v заполнитель = 14 O 31 f 48 w 15 P 32 g 49 x 16 Q 33 h 50 y
Выходной поток (закодированные байты) должен иметь длину строк не более 76 символов. Все признаки перевода строки и другие символы, отсутствующие в таблице 1, должны быть проигнорированы декодером base64. Среди данных в Base64 символы, не перечисленные в табл. 1, переводы строки и т.п. должны говорить об ошибке передачи данных, и, соответственно, программа-декодер должна оповестить пользователя о ней.
Если в хвосте потока кодируемых данных осталось меньше, чем 24 бита, справа добавляются нулевые биты до образования целого числа 6-битных групп. А до конца 24-битной группы может оставаться только от 0 до 3-х недостающих 6-битных групп, вместо каждой из которых ставится символ-заполнитель =. Поскольку весь входной поток представляет собой целое число 8-битных групп (т.е., просто байтных значений), то возможны лишь следующие случаи:
- Входной поток оканчивается ровно 24-битной группой (длина файла кратна 3). В таком случае выходной поток будет оканчиваться четырьмя символами Base64 без каких либо дополнительных символов.
- Хвост входного потока имеет длину 8 бит. Тогда в конце выходного кода будут два символа Base64, с добавлением двух символов =.
- Хвост входного потока имеет длину 16 бит. Тогда в конце выходного будут стоять три символа Base64 и один символ =.
Так как символ = является хвостовым заполнителем, его появление в теле письма может означать только то, что конец данных достигнут. Но опираться на поиск символа = для обнаружения конца файла неверно, так как, если число переданных битов кратно 24, то в выходном файле не появится ни одного символа =
Статьи к прочтению:
- Алгоритм lru (выталкивание дольше всего не использовавшейся страницы)
- Алгоритм. основные принципы составления алгоритмов. примеры.
Решение цепочек превращений по химии
Похожие статьи:
-
Алгоритм создания открытого и секретного ключей
RSA-ключи генерируются следующим образом:[14] 1. Выбираются два различных случайных простых числа и заданного размера (например, 1024 бита каждое). 2….
-
Алгоритм работы оператора цикла с постусловием
Вначале выполняются операторы цикла, затем проверяется логическое условие. В случае, когда условие ложно (False), происходит вычисление логического…