
Define идентификатор замена
Концепция типа данных
Основная цель любой программы состоит в обработке данных. Данные различного типа хранятся и обрабатываются по-разному. В любом алгоритмическом языке каждая константа, переменная, результат вычисления выражения или функции должны иметь определенный тип.
Тип данных определяет:
- внутреннее представление данных в памяти компьютера;
- множество значений, которые могут принимать величины этого типа;
- операции и функции, которые можно применять к величинам этого тина.
Исходя из этих характеристик, программист выбирает тип каждой величины, используемой в программе для представления реальных объектов. Обязательное описание типа позволяет компилятору производить проверку допустимости различных конструкций программы. От типа величины зависят машинные команды, которые будут использоваться для обработки данных.
Все типы языка C++ можно разделить на основные и составные. В языке C++ определено шесть основных типов данных для представления целых, вещественных, символьных и логических величин. На основе этих типов программист может вводить описание составных типов. К ним относятся массивы, перечисления, функции, структуры, ссылки, указатели, объединения и классы.
Основные типы данных в C++
Основные (стандартные) типы данных часто называют арифметическими, поскольку их можно использовать в арифметических операциях. Для описания основных типов определены следующие ключевые слова:
- int (целый);
- char (символьный);
- wchar_t (расширенный символьный);
- bool (логический);
- float (вещественный);
- double (вещественный с двойной точностью).
Первые четыре тина называют целочисленными (целыми), последние два — типами с плавающей точкой. Код, который формирует компилятор для обработки целых величин, отличается от кода для величин с плавающей точкой.
Существует четыре спецификатора типа, уточняющих внутреннее представление и диапазон значений стандартных типов:
- short (короткий);
- long (длинный);
- signed (знаковый);
- unsigned (беззнаковый).
Целый тип (int)
Размер типа int не определяется стандартом, а зависит от компьютера и компилятора. Для 16-разрядного процессора под величины этого типа отводится 2 байта, для 32-разрядного — 4 байта.
Спецификатор short перед именем типа указывает компилятору, что под число требуется отвести 2 байта независимо от разрядности процессора. Спецификатор long означает, что целая величина будет занимать 4 байта. Таким образом, на 16-разрядном компьютере эквиваленты int и short int, а на 32-разрядном — int и long int.
Внутреннее представление величины целого типа — целое число в двоичном коде. При использовании спецификатора signed старший бит числа интерпретируется как знаковый (0 — положительное число, 1 — отрицательное). Спецификатор unsigned позволяет представлять только положительные числа, поскольку старший разряд рассматривается как часть кода числа. Таким образом, диапазон значений типа int зависит от спецификаторов. Диапазоны значений величин целого типа с различными спецификаторами для IBM PC-совместимых компьютеров приведены в таблице «Диапазоны значений простых типов данных» в конце записи.
По умолчанию все целочисленные типы считаются знаковыми, то есть спецификатор signed можно опускать.
Константам, встречающимся в программе, приписывается тот или иной тип в соответствии с их видом. Если этот тип по каким-либо причинам не устраивает программиста, он может явно указать требуемый тип с помощью суффиксов L, l (long) и U, u (unsigned). Например, константа 32L будет иметь тип long и занимать 4 байта. Можно использовать суффиксы L и U одновременно, например, 0x22UL или 05Lu.
Примечание
Типы short int, long int, signed int и unsigned int можно сокращать до short, long, signed и unsigned соответственно.
Символьный тип (char)
Под величину символьного типа отводится количество байт, достаточное для размещения любого символа из набора символов для данного компьютера, что и обусловило название типа. Как правило, это 1 байт. Тип char, как и другие целые типы, может быть со знаком или без знака. В величинах со знаком можно хранить значения в диапазоне от -128 до 127. При использовании спецификатора unsigned значения могут находиться в пределах от О до 255. Этого достаточно для хранения любого символа из 256-символьного набора ASCII. Величины типа char применяются также для хранения целых чисел, не превышающих границы указанных диапазонов.
Расширенный символьный тип (wchar_t)
Тип wchar_t предназначен для работы с набором символов, для кодировки которых недостаточно 1 байта, например, Unicode. Размер этого типа зависит от реализации; как правило, он соответствует типу short. Строковые константы типа wchar_t записываются с префиксом L, например, L»Gates».
Логический тип (bool)
Величины логического типа могут принимать только значения true и false, являющиеся зарезервированными словами. Внутренняя форма представления значения false — 0 (нуль). Любое другое значение интерпретируется как true. При преобразовании к целому типу true имеет значение 1.
Типы с плавающей точкой (float, double и long double)
Стандарт C++ определяет три типа данных для хранения вещественных значений: float, double и long double.
Типы данных с плавающей точкой хранятся в памяти компьютера иначе, чем целочисленные. Внутреннее представление вещественного числа состоит из двух частей — мантиссы и порядка. В IBM PC-совместимых компьютерах величины типа float занимают 4 байта, из которых один двоичный разряд отводится под знак мантиссы, 8 разрядов под порядок и 23 под мантиссу. Мантисса — это число, большее 1.0, но меньшее 2.0. Поскольку старшая цифра мантиссы всегда равна 1, она не хранится.
Для величин типа double, занимающих 8 байт, под порядок и мантиссу отводится 11 и 52 разряда соответственно. Длина мантиссы определяет точность числа, а длина порядка — его диапазон. Как можно видеть из таблицы в конце записи, при одинаковом количестве байт, отводимом под величины типа float и long int, диапазоны их допустимых значений сильно различаются из-за внутренней формы представления.
Спецификатор long перед именем типа double указывает, что под его величину отводится 10 байт.
Константы с плавающей точкой имеют по умолчанию тип double. Можно явно указать тип константы с помощью суффиксов F, f (float) и L, l (long). Например, константа 2E+6L будет иметь тип long double, а константа 1.82f — тип float.
Для написания переносимых на различные платформы программ нельзя делать предположений о размере типа int. Для его получения необходимо пользоваться операцией sizeof, результатом которой является размер типа в байтах. Например, для операционной системы MS-DOS sizeof (int) даст в результате 2, а для Windows 98 или OS/2 результатом будет 4.
В стандарте ANSI диапазоны значений для основных типов не задаются, определяются только соотношения между их размерами, например:
sizeof(float) ? slzeof(double) ? sizeof(long double)
sizeof(char) ? slzeof(short) ? sizeof(int) ? sizeof(long)
Примечание
Минимальные и максимальные допустимые значения для целых типов зависят от реализации и приведены в заголовочном файле(), характеристики вещественных типов — в файле(), а также в шаблоне класса numeric_limits
Тип void
Кроме перечисленных, к основным типам языка относится тип void, но множество значений этого типа пусто. Он используется для определения функций, которые не возвращают значения, для указания пустого списка аргументов функции, как базовый тип для указателей и в операции приведения типов.
Диапазоны значений простых типов данных в C++ для IBM PC-совместимых компьютеров
Q: Что означает термин IBM PC-совместимый компьютер?
A: IBM PC-совместимый компьютер (англ. IBM PC compatible) — компьютер, архитектурно близкий к IBM PC, XT и AT. IBM PC-совместимые компьютеры построены на базе микропроцессоров, совместимых с Intel 8086 (а, как известно, все выпущенные позднее процессоры Intel имеют полную обратную совместимость с 8086). По сути это практически все современные компьютеры.
Различные виды целых и вещественных типов, различающиеся диапазоном и точностью представления данных, введены для того, чтобы дать программисту возможность наиболее эффективно использовать возможности конкретной аппаратуры, поскольку от выбора типа зависит скорость вычислений и объем памяти. Но оптимизированная для компьютеров какого-либо одного типа программа может стать не переносимой на другие платформы, поэтому в общем случае следует избегать зависимостей от конкретных характеристик типов данных.
| Тип | Диапазон значений | Размер (байт) |
| bool | true и false | |
| signed char | -128 … 127 | |
| unsigned char | 0 … 255 | |
| signed short int | -32 768 … 32 767 | |
| unsigned short int | 0 … 65 535 | |
| signed long int | -2 147 483 648 … 2 147 483 647 | |
| unsigned long int | 0 … 4 294 967 295 | |
| float | 3.4e-38 … 3.4e+38 | |
| double | 1.7e-308 … 1.7C+308 | |
| long double | 3.4e-4932 … 3.4e+4932 |
Для вещественных типов в таблице приведены абсолютные величины минимальных и максимальных значений.
Вопрос 2:Динамические структуры данных в C.Создание элементов. Примеры.
1) Динамические структуры данных в C
это структуры данных, память под которые выделяется и освобождается по мере необходимости.
Динамические структуры данных в процессе существования в памяти могут изменять не только число составляющих их элементов, но и характер связей между элементами. При этом не учитывается изменение содержимого самих элементов данных. Такая особенность динамических структур, как непостоянство их размера и характера отношений между элементами, приводит к тому, что на этапе создания машинного кода программа-компилятор не может выделить для всей структуры в целом участок памяти фиксированного размера, а также не может сопоставить с отдельными компонентами структуры конкретные адреса. Для решения проблемы адресации динамических структур данных используется метод, называемый динамическим распределением памяти, то есть память под отдельные элементы выделяется в момент, когда они начинают существовать в процессе выполнения программы, а не во время компиляции. Компилятор в этом случае выделяет фиксированный объем памяти для хранения адреса динамически размещаемого элемента, а не самого элемента.
Динамическая структура данных характеризуется тем что:
- она не имеет имени;
- ей выделяется память в процессе выполнения программы;
- количество элементов структуры может не фиксироваться;
- размерность структуры может меняться в процессе выполнения программы;
- в процессе выполнения программы может меняться характер взаимосвязи между элементами структуры.
Каждой динамической структуре данных сопоставляется статическая переменная типа указатель (ее значение – адрес этого объекта), посредством которой осуществляется доступ к динамической структуре.
Сами динамические величины не требуют описания в программе, поскольку во время компиляции память под них не выделяется. Во время компиляции память выделяется только под статические величины. Указатели – это статические величины, поэтому они требуют описания.
Необходимость в динамических структурах данных обычно возникает в следующих случаях.
- Используются переменные, имеющие довольно большой размер (например, массивы большой размерности), необходимые в одних частях программы и совершенно не нужные в других.
- В процессе работы программы нужен массив, список или иная структура, размер которой изменяется в широких пределах и трудно предсказуем.
- Когда размер данных, обрабатываемых в программе, превышает объем сегмента данных.
Динамические структуры, по определению, характеризуются отсутствием физической смежности элементов структуры в памяти, непостоянством и непредсказуемостью размера (числа элементов) структуры в процессе ее обработки.
Поскольку элементы динамической структуры располагаются по непредсказуемым адресам памяти, адрес элемента такой структуры не может быть вычислен из адреса начального или предыдущего элемента. Для установления связи между элементами динамической структуры используются указатели, через которые устанавливаются явные связи между элементами. Такое представление данных в памяти называется связным.
Достоинства связного представления данных – в возможности обеспечения значительной изменчивости структур:
- размер структуры ограничивается только доступным объемом машинной памяти;
- при изменении логической последовательности элементов структуры требуется не перемещение данных в памяти, а только коррекция указателей;
- большая гибкость структуры.
Вместе с тем, связное представление не лишено и недостатков, основными из которых являются следующие:
- на поля, содержащие указатели для связывания элементов друг с другом, расходуется дополнительная память;
- доступ к элементам связной структуры может быть менее эффективным по времени.
Последний недостаток является наиболее серьезным и именно им ограничивается применимость связного представления данных. Если в смежном представлении данных для вычисления адреса любого элемента нам во всех случаях достаточно было номера элемента и информации, содержащейся в дескрипторе структуры, то для связного представления адрес элемента не может быть вычислен из исходных данных. Дескриптор связной структуры содержит один или несколько указателей, позволяющих войти в структуру, далее поиск требуемого элемента выполняется следованием по цепочке указателей от элемента к элементу. Поэтому связное представление практически никогда не применяется в задачах, где логическая структура данных имеет вид вектора или массива – с доступом по номеру элемента, но часто применяется в задачах, где логическая структура требует другой исходной информации доступа (таблицы, списки, деревья и т.д.).
Порядок работы с динамическими структурами данных следующий:
1. создать (отвести место в динамической памяти);
2. работать при помощи указателя;
3. удалить (освободить занятое структурой место).с
Билет 18
Вопрос 1:Работа с файлами в языке C.Примеры
Для программиста открытый файл представляется как последовательность считываемых или записываемых данных. При открытии файла с ним связывается поток ввода-вывода. Выводимая информация записывается в поток, вводимая информация считывается из потока.
Когда поток открывается для ввода-вывода, он связывается со стандартной структурой типа FILE, которая определена в stdio.h. Структура FILE содержит необходимую информацию о файле.
Открытие файла осуществляется с помощью функции fopen(), которая возвращает указатель на структуру типа FILE, который можно использовать для последующих операций с файлом.
FILE *fopen(name, type);
name – имя открываемого файла (включая путь),
type — указатель на строку символов, определяющих способ доступа к файлу:
- r — открыть файл для чтения (файл должен существовать);
- w — открыть пустой файл для записи; если файл существует, то его содержимое теряется;
- a — открыть файл для записи в конец (для добавления); файл создается, если он не существует;
- r+ — открыть файл для чтения и записи (файл должен существовать);
- w+ — открыть пустой файл для чтения и записи; если файл существует, то его содержимое теряется;
- a+ — открыть файл для чтения и дополнения, если файл не существует, то он создаётся.
Возвращаемое значение — указатель на открытый поток. Если обнаружена ошибка, то возвращается значение NULL.
Функция fclose() закрывает поток или потоки, связанные с открытыми при помощи функции fopen() файлами. Закрываемый поток определяется аргументом функции fclose().
Возвращаемое значение: значение 0, если поток успешно закрыт; константа EOF, если произошла ошибка.
#include
int main() {
FILE *fp;
char name[]=my.txt;
if(fp = fopen(name, r)!=NULL) { // открыть файл удалось?
… // требуемые действия над данными
} else printf(Не удалось открыть файл);
fclose(fp);
return 0;
}
Чтение символа из файла:
char fgetc(поток);
Аргументом функции является указатель на поток типа FILE. Функция возвращает код считанного символа. Если достигнут конец файла или возникла ошибка, возвращается константа EOF.
Запись символа в файл:
fputc(символ,поток);
Аргументами функции являются символ и указатель на поток типа FILE. Функция возвращает код считанного символа.
Функции fscanf() и fprintf() аналогичны функциям scanf() и printf(), но работают с файлами данных, и имеют первый аргумент — указатель на файл.
fscanf(поток, ФорматВвода, аргументы);
fprintf(поток, ФорматВывода, аргументы);
Функции fgets() и fputs() предназначены для ввода-вывода строк, они являются аналогами функций gets() и puts() для работы с файлами.
fgets(УказательНаСтроку,КоличествоСимволов,поток);
Символы читаются из потока до тех пор, пока не будет прочитан символ новой строки ‘\n’, который включается в строку, или пока не наступит конец потока EOF или не будет прочитано максимальное символов. Результат помещается в указатель на строку и заканчивается нуль- символом ‘\0’. Функция возвращает адрес строки.
fputs(УказательНаСтроку,поток);
Копирует строку в поток с текущей позиции. Завершающий нуль- символ не копируется.
Пример Ввести число и сохранить его в файле s1.txt. Считать число из файла s1.txt, увеличить его на 3 и сохранить в файле s2.txt.
#include
#include
int main() {
FILE *S1, *S2;
int x, y;
system(chcp 1251);
system(cls);
printf(Введите число: );
scanf(%d, x);
S1 = fopen(S1.txt, w);
fprintf(S1, %d, x);
fclose(S1);
S1 = fopen(S1.txt, r);
S2 = fopen(S2.txt, w);
fscanf(S1, %d, y);
y += 3;
fclose(S1);
fprintf(S2, %d\n, y);
fclose(S2);
return 0;
}
Результат выполнения — 2 файла

Билет 19
Вопрос 1:Перечислимый тип данных языка C.Примеры
Вси выделен отдельный тип перечисление (enum), задающий набор всех возможных целочисленных значений переменной этого типа. Синтаксис перечисления
?
| enum{,,…}; //здесть стоит ;! |
Например
?
| #include #includeenum Gender {MALE,FEMALE}; void main() {enum Gender a, b;a = MALE;b = FEMALE;printf(a = %d\n, a);printf(b = %d\n, b);getch();} |
В этой программе объявлено перечисление с именем Gender. Переменная типа enum Gender может принимать теперь только два значения – это MALE И FEMALE.
По умолчанию, первое поле структуры принимает численное значение 0, следующее 1, следующее 2 и т.д. Можно задать нулевое значение явно:
?
| #include #includeenum Token {SYMBOL, //0NUMBER, //1EXPRESSION = 0, //0OPERATOR, //1UNDEFINED //2}; void main() {enum Token a, b, c, d, e;a = SYMBOL;b = NUMBER;c = EXPRESSION;d = OPERATOR;e = UNDEFINED;printf(a = %d\n, a);printf(b = %d\n, b);printf(c = %d\n, c);printf(d = %d\n, d);printf(e = %d\n, e);getch();} |
Будут выведены значения 0 1 0 1 2. То есть, значение SYMBOL равно значению EXPRESSION, а NUMBER равно OPERATOR. Если мы изменим программу и напишем
?
| enum Token {SYMBOL, //0NUMBER, //1EXPRESSION = 10, //10OPERATOR, //11UNDEFINED //12}; |
То SYMBOL будет равно значению 0, NUMBER равно 1, EXPRESSION равно 10, OPERATOR равно 11, UNDEFINED равно 12.
Принято писать имена полей перечисления, как и константы, заглавными буквами. Так как поля перечисления целого типа, то они могут быть использованы в операторе switch.
Заметьте, что мы не можем присвоить переменной типа Token просто численное значение. Переменная является сущностью типа Token и принимает только значения полей перечисления. Тем не менее, переменной числу можно присвоить значение поля перечисления.
Обычно перечисления используются в качестве набора именованных констант. Часто поступают следующим образом — создают массив строк, ассоциированных с полями перечисления. Например
?
| #include #include #includestatic char *ErrorNames[] = {Index Out Of Bounds,Stack Overflow,Stack Underflow,Out of Memory}; enum Errors {INDEX_OUT_OF_BOUNDS = 1,STACK_OVERFLOW,STACK_UNDERFLOW,OUT_OF_MEMORY}; void main() {//ошибка случиласьprintf(ErrorNames[INDEX_OUT_OF_BOUNDS-1]);exit(INDEX_OUT_OF_BOUNDS);} |
Так как поля принимают численные значения, то они могут использоваться в качестве индекса массива строк. Команда exit(N) должна получать код ошибки, отличный от нуля, потому что 0 — это плановое завершение без ошибки. Именно поэтому первое поле перечисления равно единице.
Перечисления используются для большей типобезопасности и ограничения возможных значений переменной. Для того, чтобы не писать enum каждый раз, можно объявить новый тип. Делается это также, как и в случае структур.
?
| typedef enum enumName {FIELD1,FIELD2} Name; |
Например
?
| typedef enum Bool {FALSE,TRUE} Bool; |
Вопрос 2:Ввод/вывод в C++.Примеры
В С++, как и в С, нет встроенных в язык средств ввода-вывода.
В С для этих целей используется библиотека stdio.h.
В С++ разработана новая библиотека ввода-вывода iostream, использующая концепцию объектно-ориентированного программирования:
#include
Библиотека iostream определяет три стандартных потока:
- cin стандартный входной поток (stdin в С)
- cout стандартный выходной поток (stdout в С)
- cerr стандартный поток вывода сообщений об ошибках (stderr в С)
Для их использования в Microsoft Visual Studio необходимо прописать строку:
using namespace std;
Для выполнения операций ввода-вывода переопределены две операции поразрядного сдвига:
- получить из входного потока
Вывод информации
cout
Здесь значение преобразуется в последовательность символов и выводится в выходной поток:
cout
Возможно многократное назначение потоков:
cout
int n;
char j;
cinnj;
cout
Ввод информации
cinидентификатор;
При этом из входного потока читается последовательность символов до пробела, затем эта последовательность преобразуется к типу идентификатора, и получаемое значение помещается в идентификатор:
int n;
cinn;
Возможно многократное назначение потоков:
cinпеременная1переменная2 … переменнаяn;
При наборе данных на клавиатуре значения для такого оператора должны быть разделены символами (пробел, \n, \t).
int n;
char j;
cinnj;
Особого внимания заслуживает ввод символьных строк. По умолчанию потоковый ввод cin вводит строку до пробела, символа табуляции или перевода строки.
Пример
#include
using namespace std;
int main() {
char s[80];
cins;
cout
system(pause);
return 0;
}
Результат выполнения

Для ввода текста до символа перевода строки используется манипулятор потока getline():
#include
using namespace std;
int main() {
char s[80];
cin.getline(s,80);
cout
system(pause);
return 0;
}
Результат выполнения

Манипуляторы потока
Функцию — манипулятор потока можно включать в операции помещения в поток и извлечения из потока ().
В С++ имеется ряд манипуляторов. Рассмотрим основные:
| Манипулятор | Описание |
| endl | Помещение в выходной поток символа конца строки ‘\n’ |
| dec | Установка основания 10-ой системы счисления |
| oct | Установка основания 8-ой системы счисления |
| hex | Установка основания 16-ой системы счисления |
| setbase | Вывод базовой системы счисления |
| width(ширина) | Устанавливает ширину поля вывода |
| fill(‘символ’) | Заполняет пустые знакоместа значением символа |
| precision(точность) | Устанавливает количество значащих цифр в числе (или после запятой) в зависимости от использования fixed |
| fixed | Показывает, что установленная точность относится к количеству знаков после запятой |
| showpos | Показывает знак + для положительных чисел |
| scientific | Выводит число в экспоненциальной форме |
| get() | Ожидает ввода символа |
| getline(указатель, количество) | Ожидает ввода строки символов. Максимальное количество символов ограничено полем количество |
Пример Программа ввода-вывода значения переменной в C++
#include
using namespace std;
int main() {
int n;
cout
cinn;
cout
cin.get(); cin.get();
return 0;
}
Та же программа, написанная на языке Си
#include
int main() {
int n;
printf(Введите n:);
scanf(%d,n);
printf(Значение n равно: %d\n,n);
getchar(); getchar();
return 0;
}
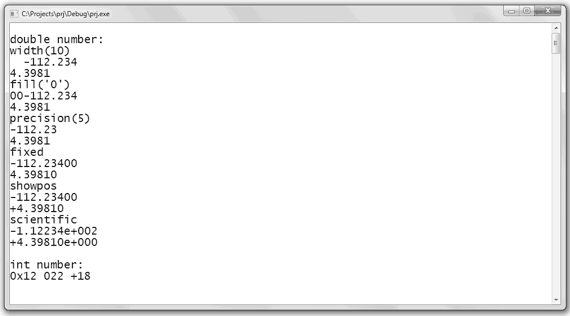
Пример Использование форматированного вывода
#include
using namespace std;
int main()
{
double a = -112.234;
double b = 4.3981;
int c = 18;
cout
cout
cout.width(10);
cout
cout
cout.fill(‘0’);
cout.width(10);
cout
cout.precision(5);
cout
cout
cout
cout
cout
cout
cout
cin.get();
return 0;
}
Результат выполнения
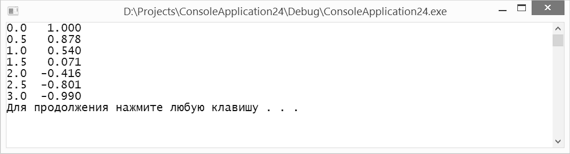
Еще один пример использования форматированного вывода: для t?[0;3] с шагом 0,5 вычислить значение y=cos(t).
#include
using namespace std;
int main() {
cout
for (double t = 0; t
cout.width(3);
cout.precision(1);
cout
cout.width(8);
cout.precision(3);
cout
}
system(pause);
return 0;
}
Результат выполнения
Билет 20
Вопрос 1:Препроцессор языка С. Примеры.
Препроцессор — это специальная программа, являющаяся частью компилятора языка Си. Она предназначена для предварительной обработки текста программы. Препроцессор позволяет включать в текст программы файлы и вводить макроопределения.
Работа препроцессора осуществляется с помощью специальных директив (указаний). Они отмечаются знаком решетка #. По окончании строк, обозначающих директивы в языке Си, точку с запятой можно не ставить.
Основные директивы препроцессора
#include — вставляет текст из указанного файла
#define — задаёт макроопределение (макрос) или символическую константу
#undef — отменяет предыдущее определение
#if — осуществляет условную компиляцию при истинности константного выражения
#ifdef — осуществляет условную компиляцию при определённости символической константы
#ifndef — осуществляет условную компиляцию при неопределённости символической константы
#else — ветка условной компиляции при ложности выражения
#elif — ветка условной компиляции, образуемая слиянием else и if
#endif — конец ветки условной компиляции
#line — препроцессор изменяет номер текущей строки и имя компилируемого файла
#error — выдача диагностического сообщения
#pragma — действие, зависящее от конкретной реализации компилятора.
Директива #include
Директива #include позволяет включать в текст программы указанный файл. Если файл является стандартной библиотекой и находится в папке компилятора, он заключается в угловые скобки. Если файл находится в текущем каталоге проекта, он указывается в кавычках. Для файла, находящегося в другом каталоге необходимо в кавычках указать полный путь.
#include
#include func.c
Директива #define
Директива #define позволяет вводить в текст программы константы и макроопределения.
Общая форма записи
define идентификатор замена
Поля идентификатор и замена разделяются одним или несколькими пробелами. Директива #defineуказывает компилятору, что нужно подставить строку, определенную аргументом замена, вместо каждого аргумента идентификатор в исходном файле. Идентификатор не заменяется, если он находится в комментарии, в строке или как часть более длинного идентификатора.
#include
#define A 3
int main(){
printf(%d + %d = %d, A, A, A+A); // 3 + 3 = 6
getchar();
return 0;
}
В зависимости от значения константы компилятор присваивает ей тот или иной тип. С помощью суффиксов можно переопределить тип константы:
- U или u представляет целую константу в беззнаковой форме (unsigned);
- F (или f) позволяет описать вещественную константу типа float;
- L/span (или l) позволяет выделить целой константе 8 байт (long int);
- L/span (или l) позволяет описать вещественную константу типа long double
#define A 280U // unsigned int
#define B 280LU // unsigned long int
#define C 280 // int (long int)
#define D 280L // long int
#define K 28.0 // double
#define L 28.0F // float
#define M 28.0L // long double
Вторая форма синтаксиса определяет макрос, подобный функции, с параметрами. Эта форма допускает использование необязательного списка параметров, которые должны находиться в скобках. После определения макроса каждое последующее вхождение
идентификатор(аргумент1, …, агрументn)
замещается версией аргумента замена, в которой вместо формальных аргументов подставлены фактические аргументы.
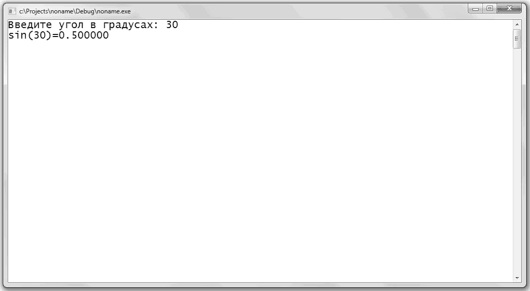
Пример Вычисление синуса угла
#include
#include
#include
#define PI 3.14159265
#define SIN(x) sin(PI*x/180)
int main() {
int c;
system(chcp 1251);
system(cls);
printf(Введите угол в градусах: );
scanf(%d, c);
printf(sin(%d)=%lf, c, SIN(c));
getchar(); getchar();
return 0;
}
Результат выполнения
Отличием таких макроопределений от функций в языке Си является то, что на этапе компиляции каждое вхождение идентификатора замещается соответствующим кодом. Таким образом, программа может иметь несколько копий одного и того же кода, соответствующего идентификатору. В случае работы с функциями программа будет содержать 1 экземпляр кода, реализующий указанную функцию, и каждый раз при обращении к функции ей будет передано управление.
Отменить макроопределение можно с помощью директивы #undef.
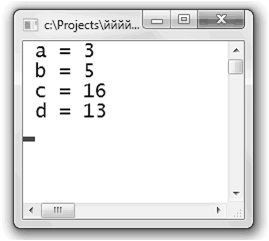
Однако при использовании таких макроопределений следует соблюдать осторожность, например
#include
#define sum(A,B) A+B
int main(){
int a,b,c,d;
a=3; b=5;
c = (a + b)*2; // c = (a + b)*2
d = sum(a, b) * 2; // d = a + b*2;
printf( a = %d\n b = %d\n, a, b);
printf( c = %d \n d = %d \n, c, d);
getchar();
return 0;
}
Результат выполнения:
Условная компиляция
Директивы #if или #ifdef/#ifndef вместе с директивами #elif, #else и #endif управляют компиляцией частей исходного файла.Если указанное выражение после #if имеет ненулевое значение, в записи преобразования сохраняется группа строк, следующая сразу за директивой #if. Синтаксис условной директивы следующий:
Статьи к прочтению:
- Действия, приводящие к неправомерному овладению конфиденциальной информацией.
- Делаем текст из светодиодов в фотошоп
Dom Dolla & Go Freek — Define
Похожие статьи:
-
Определяющее-тип-имя идентификатор
Typedef. В пределах области действия описания со спецификатором typedef каждыйидентификатор, являющийся частью любого описателя в этом…
-
Использование директивы #define
С помощью директивы #define можно вводить собственные обозначения базовых или производных типов. Пример: Директива #define REAL long double вводит имя…