
Динамическое повышение приоритета
Планировщик принимает решения на основе текущего приоритета потока, который может быть выше базового. Есть несколько ситуаций, когда имеет смысл повысить приоритет потока.
Например, после завершения операции ввода-вывода увеличивают приоритет потока, чтобы дать ему возможность быстрее начать выполнение и, может быть, вновь инициировать операцию ввода-вывода. Таким способом система поощряет интерактивные потоки и поддерживает занятость устройств ввода-вывода. Величина, на которую повышается приоритет, не документирована и зависит от устройства (рекомендованные значения для диска и CD — это 1, для сети — 2, клавиатуры и мыши — 6 и звуковой карты — 8). В дальнейшем в течение нескольких квантов времени приоритет плавно снижается до базового.
Другими примерами подобных ситуаций могут служить: пробуждение потока после состояния ожидания семафора или иного события; получение потоком доступа к оконному вводу.
Динамическое повышение приоритета решает также проблему голодания потоков, долго не получающих доступ к процессору. Обнаружив такие потоки, простаивающие в течение примерно 4 сек., система временно повышает их приоритет до 15 и дает им два кванта времени. Побочным следствием применения этой технологии может быть решение известной проблемы инверсии приоритетов [ Таненбаум ] . Эта проблема возникает, когда низкоприоритетный поток удерживает ресурс, блокируя высокоприоритетные потоки, претендующие на этот ресурс. Решение состоит в искусственном повышении его приоритета на некоторое время.
Динамическое повышение приоритетов призвано оптимизировать общую пропускную способность системы, однако от него выигрывают далеко не все приложения. Отключение динамического повышения приоритета можно осуществить при помощи функций SetProcessPriorityBoost и SetThreadPriorityBoost.
Величина кванта времени
Величина кванта времени имеет критическое значение для эффективной работы системы в целом. Необходимо сохранить интерактивные качества системы и при этом избежать слишком частого переключения контекстов. Вероятно оптимальное значение кванта (доля секунды) должно обеспечивать обслуживание без переключения запроса пользователя, который занимает процессор ненадолго, после чего обычно генерирует запрос на ввод-вывод. В этом случае расходы на диспетчеризацию сводятся к минимуму и обеспечиваются приемлемые времена откликов.
По умолчанию начальная величина кванта в Windows Professional равна двум интервалам таймера, а в Windows Server эта величина увеличена до 12, чтобы свести к минимуму переключение контекста. Длительность интервала таймера определяется HAL и составляет примерно 10 мс для однопроцессорных x86 систем и 15 мс — для многопроцессорных. Величину интервала системного таймера можно определить с помощью свободно распространяемой утилиты Clockres (сайт http://sysinternals.com).
Выбор между короткими и длинными значениями можно сделать с помощью панели свойства Моего компьютера. Величина кванта задается в параметре HKLM\SYSTEM\CurrentControlSet\Control\PriorityControl\Win32PrioritySeparation реестра.
- Что такое относительный приоритетпотока?
Относительный приоритет
Второй составляющей общего приоритета потока является относительный приоритет отдельного потока. Следует подчеркнуть, что приоритет класса связан с процессом, а от носительный приоритет — с отдельными потоками внутри процесса. Потоку можнона значить один из семи возможных относительных приоритетов: Idle (ожидание), Lowest (низший), Below Normal (ниже нормального), Normal (нормальный), Above Normal (выше нормального), Highest (высший) или Time Critical (критический по времени).
Таблица 5.2. Относительные приоритеты потока
| TThreadPriority | Константа | Значение |
| tpIdle | THREAD_PRIORITY_IDLE | -15* |
| tpLowest | THREAD_PRIORITY_LOWEST | -2 |
| tpBelow Normal | THREAD_PRIORITY_BELOW_NORMAL | -1 |
| tpNormal | THREAD_PRIORITY_NORMAL | |
| tpAbove Normal | THREAD_PRIORITY_ABOVE_NORMAL | |
| tpHighest | THREAD_PRIORITY_HIGHEST | |
| tpTimeCritical | THREAD_PRIORITY_TIME_CRITICAL | 15* |
- Что такое «динамический приоритет»потока?
Во многих ОС предусматривается возможность изменения приоритетов в течение жизни потока. Изменение приоритета может происходить по инициативе самого потока, когда он обращается с соответствующим вызовом к операционной системе, или по инициативе пользователя, когда он выполняет соответствующую команду. Кроме того, ОС сама может изменять приоритеты потоков в зависимости от ситуации, складывающейся в системе. В последнем случае приоритеты называются динамическими в отличие от неизменяемых, фиксированных, приоритетов.
- Понятие кэширование и кэш-памяти.
Кэш-память
Кэш-память представляет собой быстродействующее ЗУ, размещенное на одном кристалле с ЦП или внешнее по отношению к ЦП. Кэш служит высокоскоростным буфером между ЦП и относительно медленной основной памятью. Идея кэш-памяти основана на прогнозировании наиболее вероятных обращений ЦП к оперативной памяти. В основу такого подхода положен принцип временной и пространственной локальности программы.
Если ЦП обратился к какому-либо объекту оперативной памяти, с высокой долей вероятности ЦП вскоре снова обратится к этому объекту. Примером этой ситуации может быть код или данные в циклах. Эта концепция описывается принципом временной локальности, в соответствии с которым часто используемые объекты оперативной памяти должны быть ближе к ЦП (в кэше).
Для согласования содержимого кэш-памяти и оперативной памяти используют три метода записи:
- сквозная запись (write through) — одновременно с кэш-памятью обновляется оперативная память.
- буферизованная сквозная запись (buffered write through) — информация задерживается в кэш-буфере перед записью в оперативную память и переписывается в оперативную память в те циклы, когда ЦП к ней не обращается.
- обратная запись (write back) — используется бит изменения в поле тега, и строка переписывается в оперативную память только в том случае, если бит изменения равен 1.
Как правило, все методы записи, кроме сквозной, позволяют для увеличения производительности откладывать и группировать операции записи в оперативную память.
В структуре кэш-памяти выделяют два типа блоков данных:
- память отображения данных (собственно сами данные, дублированные из оперативной памяти);
- память тегов (признаки, указывающие на расположение кэшированных данных в оперативной памяти).
Пространство памяти отображения данных в кэше разбивается на строки — блоки фиксированной длины (например, 32, 64 или 128 байт). Каждая строка кэша может содержать непрерывный выровненный блок байт из оперативной памяти. Какой именно блок оперативной памяти отображен на данную строку кэша, определяется тегом строки и алгоритмом отображения. По алгоритмам отображения оперативной памяти в кэш выделяют три типа кэш-памяти:
полностью ассоциативный кэш;
кэш прямого отображения;
множественный ассоциативный кэш.
Для полностью ассоциативного кэша характерно, что кэш-контроллер может поместить любой блок оперативной памяти в любую строку кэш-памяти (рис. Полностью ассоциативный кэш 8х8 для 10-битного адреса ). В этом случае физический адрес разбивается на две части: смещение в блоке (строке кэша) и номер блока. При помещении блока в кэш номер блока сохраняется в теге соответствующей строки. Когда ЦП обращается к кэшу за необходимым блоком, кэш-промах будет обнаружен только после сравнения тегов всех строк с номером блока.
Одно из основных достоинств данного способа отображения — хорошая утилизация оперативной памяти, т.к. нет ограничений на то, какой блок может быть отображен на ту или иную строку кэш-памяти. К недостаткам следует отнести сложную аппаратную реализацию этого способа, требующую большого количества схемотехники (в основном компараторов), что приводит к увеличению времени доступа к такому кэшу и увеличению его стоимости.
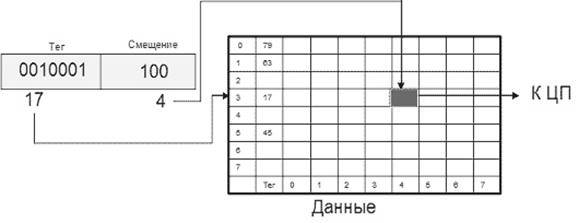
Рис. Полностью ассоциативный кэш 8х8 для 10-битного адреса
Альтернативный способ отображения оперативной памяти в кэш — это кэш прямог отображения (или одновходовый ассоциативный кэш). В этом случае адрес памяти (номер блока) однозначно определяет строку кэша, в которую будет помещен данный блок. Физический адрес разбивается на три части: смещение в блоке (строке кэша), номер строки кэша и тег. Тот или иной блок будет всегда помещаться в строго определенную строку кэша, при необходимости заменяя собой хранящийся там другой блок. Когда ЦП обращается к кэшу за необходимым блоком, для определения удачного обращения или кэш-промаха достаточно проверить тег лишь одной строки.
Очевидными преимуществами данного алгоритма являются простота и дешевизна реализации. К недостаткам следует отнести низкую эффективность такого кэша из-за вероятных частых перезагрузок строк. Например, при обращении к каждой 64-й ячейке памяти в системе на рис.Кэш прямого отображения 8х8 для 10-битного адреса кэш-контроллер будет вынужден постоянно перегружать одну и ту же строку кэш-памяти, совершенно не задействовав остальные.
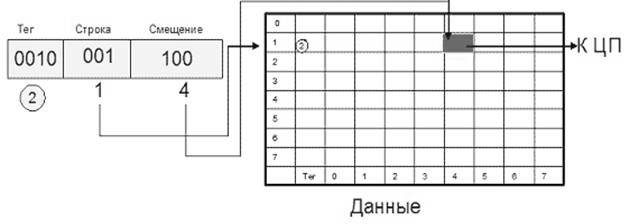
Рис. Кэш прямого отображения 8х8 для 10-битного адреса
Несмотря на очевидные недостатки, данная технология нашла успешное применение, например, в МП Motorola MC68020, для организации кэша инструкций первого уровня (Рис. Схема организации кэш-памяти в МП Motorola MC68020 ). В данном микропроцессоре реализован кэш прямого отображения из 64 строк по 4 байт. Тег строки, кроме 24 бит, задающих адрес кэшированного блока, содержит бит значимости, определяющий действительность строки (если бит значимости 0, данная строка считается недействительной и не вызовет кэш-попадания). Обращения к данным не кэшируются.
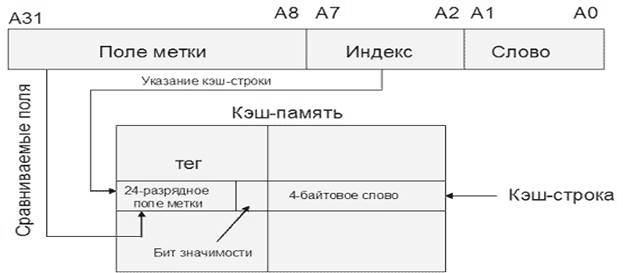
14. Рис. Схема организации кэш-памяти в МП Motorola MC68020
Компромиссным вариантом между первыми двумя алгоритмами является множественный ассоциативный кэш или частично-ассоциативный кэш (Рис. Двухвходовый ассоциативный кэш 8х8 для 10-битного адреса ). При этом способе организации кэш-памяти строки объединяются в группы, в которые могут входить 2, 4, : строк. В соответствии с количеством строк в таких группах различают 2-входовый, 4-входовый и т.п. ассоциативный кэш. При обращении к памяти физический адрес разбивается на три части: смещение в блоке (строке кэша), номер группы (набора) и тег. Блок памяти, адрес которого соответствует определенной группе, может быть размещен в любой строке этой группы, и в теге строки размещается соответствующее значение. Очевидно, что в рамках выбранной группы соблюдается принцип ассоциативности. С другой стороны, тот или иной блок может попасть только в строго определенную группу, что перекликается с принципом организации кэша прямого отображения. Для того чтобы процессор смог идентифицировать кэш-промах, ему надо будет проверить теги лишь одной группы (2/4/8/: строк).
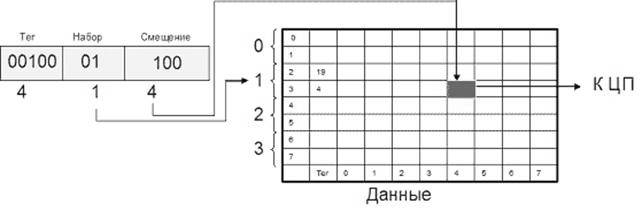
Рис. Двухвходовый ассоциативный кэш 8х8 для 10-битного адреса
Данный алгоритм отображения сочетает достоинства как полностью ассоциативного кэша (хорошая утилизация памяти, высокая скорость), так и кэша прямого доступа (простота и дешевизна), лишь незначительно уступая по этим характеристикам исходным алгоритмам. Именно поэтому множественный ассоциативный кэш наиболее широко распространен (табл. Характеристики подсистемы кэш-памяти у ЦП IA-32).
Таблица . Характеристики подсистемы кэш-памяти у ЦП IA-32
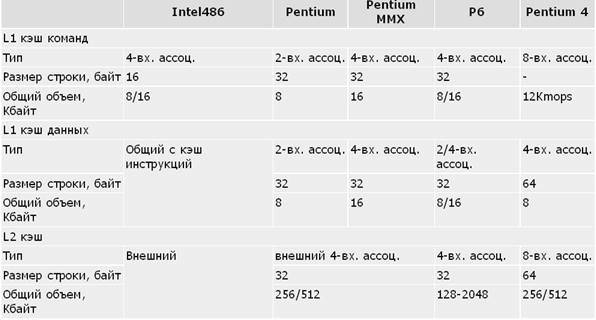
Примечания: В Intel-486 используется единый кэш команд и данных первого уровня. В Pentium Pro L1 кэш данных — 8 Кбайт 2-входовый ассоциативный, в остальных моделях P6 — 16 Кбайт 4-входовый ассоциативный. В Pentium 4 вместо L1 кэша команд используется L1 кэш микроопераций (кэш трассы).
Для организации кэш-памяти можно использовать принстонскую архитектуру (смешанный кэш для команд и данных, например, в Intel-486). Это очевидное (и неизбежное для фон-неймановских систем с внешней по отношению к ЦП кэш-памятью) решение не всегда бывает самым эффективным. Разделение кэш-памяти на кэш команд и кэш данных (кэш гарвардской архитектуры) позволяет повысить эффективность работы кэша по следующим соображениям:
многие современные процессоры имеют конвейерную архитектуру, при которой блоки конвейера работают параллельно. Таким образом, выборка команды и доступ к данным команды осуществляется на разных этапах конвейера, а использование раздельной кэш-памяти позволяет выполнять эти операции параллельно.
- кэш команд может быть реализован только для чтения, следовательно, не требует реализации никаких алгоритмов обратной записи, что делает этот кэш проще, дешевле и быстрее.
Именно поэтому все последние модели IA-32, начиная с Pentium, для организации кэш-памяти первого уровня используют гарвардскую архитектуру.
Критерием эффективной работы кэша можно считать уменьшение среднего времени доступа к памяти по сравнению с системой без кэш-памяти. В таком случае среднее время доступа можно оценить следующим образом:
15. Tср = (Thit x Rhit) + (Tmiss x (1 Rhit))
где Thit — время доступа к кэш-памяти в случае попадания (включает время на идентификацию промаха или попадания), Tmiss — время, необходимое на загрузку блока из основной памяти в строку кэша в случае кэш-промаха и последующую доставку запрошенных данных в процессор, Rhit — частота попаданий.
Очевидно, что чем ближе значение Rhit к 1, тем ближе значение Tср к Thit. Частота попаданий определяется в основном архитектурой кэш-памяти и ее объемом. Влияние наличия и отсутствия кэш-памяти и ее объема на рост производительности ЦП показано в табл. Размер и эффективность кэш-памяти
Таблица. Размер и эффективность кэш-памяти
| Размер кэш-памяти | Частота попаданий, % | Рост производительности, % |
| Нет кэш-памяти, DRAM с 2 TW | — | |
| 16 Кб | ||
| 32 Кб | ||
| 64 Кб | ||
| 128 Кб | ||
| Нет кэш-памяти, SRAM без TW | — |
Стратегия размещения.
На сложность этого механизма существенное влияние оказывает
стратегия размещения, определяющая, в какое место кэш-памяти
следует поместить каждый блок из основной памяти.
В зависимости от способа размещения данных основной памяти в кэш-памяти существует три типа кэш-памяти:
- кэш с прямым отображением (размещением);
- полностью ассоциативный кэш;
- множественный ассоциативный кэш или частично-ассоциативный.
Кэш с прямым отображением (размещением) является самым
простым типом буфера. Адрес памяти однозначно определяет строку
кэша, в которую будет помещен блок информации. При этом предпо-
лагается, что оперативная память разбита на блоки и каждому та-
кому блоку в буфере отводится всего одна строка. Это простой и недорогой в реализации способ отображения. Основной его недостаток – жесткое закрепление за определенными блоками ОП одной строки в кэше. Поэтому, если программа поочередно обращается к словам из двух различных блоков, отображаемых на одну и ту же строку кэш-памяти, постоянно будет происходить обновление данной строки и вероятность попадания будет низкой.
Кэш с полностью ассоциативным отображениемпозволяет преодолеть недостаток прямого, разрешая загрузку любого блока ОП в любую строку кэш-памяти. Логика управления выделяет в адресе ОП два поля: поле тега и поле слова. Поле тега совпадает с адресом блока ОП. Для проверки наличия копии блока в кэш-памяти, логика управления кэша должна одновременно проверить теги всех строк на совпадение с полем тега адреса. Ассоциативное отображение обеспечивает гибкость при выборе строки для вновь записываемого блока. Принципиальный недостаток этого способа – в необходимости использования дорогой ассоциативной памяти.
Множественно-ассоциативный тип или частично-ассоциативный тип отображения –это один из возможных компромиссов, сочетающий достоинства прямого и ассоциативного способов. Кэш-память ( и тегов и данных) разбивается на некоторое количество модулей. Зависимость между модулем и блоками ОП такая же жесткая, как и при прямом отображении. А вот размещение блоков по строкам модуля произвольное и для поиска нужной строки в пределах модуля используется ассоциативный принцип. Этот способ отображения наиболее широко распространен в современных микропроцессорах.
- От чего зависит эффективность работыкэш-памяти.
- Зачем нужен TLB (буферассоциативности трансляции).
Трансляция каждого адреса требует двух операций поиска: сначала нужно найти подходящую таблицу страниц в каталоге страниц, а затем элемент в этой таблице. Выполнение этих операций при каждом обращении по виртуальному адресу снижает быстродействие системы. Поэтому большинство процессоров кэшируют транслируемые адреса и необходимость в повторной трансляции тех же адресов из-за этого отпадает. Процессор типа x86 поддерживает такой кэш в виде массива ассоциативной памяти, называемого ассоциативным буфером трансляции (translation lookaside buffer, TLB). Ассоциативная память – это вектор, составляющие которого могут одновременно считываться и сравниваться с целевым значением. В случае TLB вектор содержит отображение виртуальных адресов в физические для страниц, которые использовались
самыми последними. Упрощенная схема TLB показана на Рис. 5. Ассоциативный буфер трансляции.
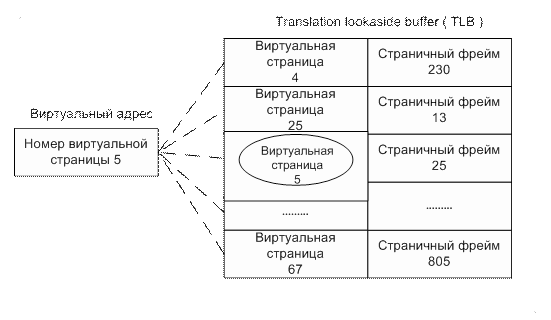
Для адресов, которые используются часто, с высокой вероятностью будут присутствовать входы в TLB, а значит, трансляция этих виртуальных адресов в физические будет происходить очень быстро. Когда виртуальная страница откачивается на диск, диспетчер виртуальной памяти делает недействительным соответствующий вход TLB. При обращении процесса к такой странице происходит страничная ошибка, и диспетчер виртуальной памяти вновь переносит страницу в память и снова создает для нее вход TLB.
Для поиска страниц, отсутствующих в TLB, диспетчер виртуальной памяти использует таблицы страниц, создаваемые программно. Концептуально таблица страниц представлена на Рис. 3 Концептуальная схема таблицы страниц.
Вход таблицы страниц (page table entry, PTE) содержит всю информацию, необходимую системе виртуальной памяти для поиска страницы, когда поток обращается по адресу в ней. Недействительный вход означает, что страница отсутствует в физической памяти и ее нужно загрузить с диска. Генерируется страничная ошибка, программное обеспечение подкачки страниц загружает запрашиваемую страницу в память и обновляет таблицу страниц. Команда, вызвавшая страничную ошибку, выполняется повторно. Теперь вход таблицы страниц является действительным, и обращение к памяти выполняется успешно.
Статьи к прочтению:
КАК ПОВЫСИТЬ FPS В CS:GO? НА СЛАБОМ КОМПЬЮТЕРЕ!
Похожие статьи:
-
Диспетчеризация задач с использованием динамических приоритетов
При выполнении программ, реализующих какие-либо задачи контроля и управления (что характерно, прежде всего, для систем реального времени), может…
-
Методы повышения пропускной способности оп.
Для чего нужно повышать пропускную способность ОП? Прежде всего, для того, чтобы за одно обращение к памяти можно было считать большее количество…