
Хеширование, или метод вычисляемого адреса. хеш-функции. разрешение коллизий.
Одним из основных недостатков последовательного поиска является зависимость времени доступа к различным элементам множества A . Как упоминалось выше, основной Причиной этого является отсутствие структурированности множества. С другой стороны массив является структурой, позволяющей, организовать прямой доступ к элементу при наличии его индекса. Но поскольку поиск обычно ведется по значению элемента, возникает задача преобразования значения элемента в индекс его местонахождения. Выше было описано, как с такой задачей справляются деревья поиска. Эта задача может быть решена при помощи специальных таблиц, преобразующих значения элементов в индексы, но тогда надо уметь решать задачу поиска в этих таблицах, и образуется заколдованный круг. Промежуточным вариантом является индексно-последовательный доступ, когда множество A представляется в виде набора подмножеств и существует функция отображающая значение каждого элемента из A в индекс подмножества его содержащего. При такой организации множества, поиск элемента может быть сведен к поиску соответствующего подмножества с дальнейшим перебором в некотором порядке его элементов.
4.4.1. Открытое хеширование. Одной из реализаций такой идеи является таблица, строкам которой приписаны подмножества множества A . Множества элементов, приписанных различным строкам таблицы, не пересекаются и каждый элемент множества A принадлежит некоторой строке. Пусть строки таблицы пронумерованы и номера лежат в интервале от 0 до d -1. Положим D = {0,1,…,d -1}. Пусть далее задана некоторая функция h : AU B -D34, которая называется функцией хеширования. Решение задачи поиска b€A сводится к вычислению значения h(b) с дальнейшей проверкой предиката P(a,b) для элементов соответствующей строки. Наиболее часто используемой структурой для представления элементов строки h(b) A является последовательный список или массив. Сочетание прямого и последовательного доступа представляет определенный компромисс между временем и объемом памяти. При этом число подмножеств множества A является параметром алгоритма хеширования, выбор которого позволяет поддерживать необходимое соотношение между показателями времени и объема памяти. Ниже приведен пример хеш-таблицы, в которой подмножества заданы списками:
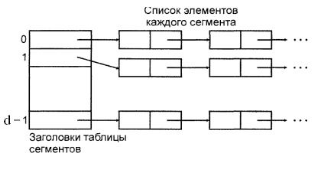
Временная сложность одной операции поиска в худшем случае выражается как сумма T (h (b )) + maxh(b) T (A h(b) ) , где первый член суммы является временем вычисления значения h(b) , а T( A h(b))- временем поиска элемента b в строке h(b) A . Поскольку при неудачном распределении все элементы могут попасть в один класс, то временная сложность поиска в худшем случае составляет O(n) , где n — число элементов множества A 35. Понятно, что минимизация общего времени поиска связана с минимизацией каждого слагаемого суммы T (h (b)) + maxd€D T (A d ). Поскольку T (A d) прямо пропорционально числу элементов множества A d, то хорошие алгоритмы хеширования должны минимизировать мощность A d. Гораздо больший интерес представляет среднее время поиска. Оказывается при выполнении некоторых предположений (а именно, если значения хеш-функции равномерно распределены по позициям таблицы) можно оценить среднее время поиска элемента в таблице. Число a = n / d называется коэффициентом заполнения таблицы.
Тогда верна
Продолжение 26
Теорема [4] При равномерном хешировании среднее время успешного поиска в хеш- таблице с цепочками равно O(1+a ) , где a — коэффициент заполнения. Из теоремы следует, что когда количество позиций в хеш-таблице пропорционально числуключей среднее время поиска можно свести к O(1) . При использовании двустороннихсписков среднее время добавления и удаления элемента в хеш-таблицу также оцениваетсякак O(1) . Поэтому среднее время выполнения любой словарной операции (впредположении равномерного хеширования) равно O(1) .Поскольку два разных элемента 1 a и 2 a попадают в одну строку таблицы в случае h (a1) = h( a2) , то следуя [14] назовем такую ситуацию коллизией. Поскольку разрешениеколлизий требует дополнительного времени, при выборе подходящей хеш-функциируководствуются требованиями:
1. для любого b€ B время вычисления h(b) должно быть небольшим;
2. число коллизий должно быть минимальным.
Выбор подходящей функции, удовлетворяющей этим условиям, является достаточно сложной задачей. Подбор функции хеширования во многом зависит от элементов множества A . При условии, что ключевые параметры элементов множеств A и B описываются натуральными числами, можно положить h(a) = a (mod d) . Такая функция дает достаточно неплохие результаты при простых значениях d . Если A является множеством строк, то в качестве функции хеширования можно рассмотреть функцию, задаваемую процедурой
Function h(a: string): 0..d-1;
Var i, sum : integer;
begin
sum:=0;
for i=0 to length(a) do
sum:=sum+ord(a[i]);
h:=sum mod d;
end
Функция суммирует коды букв из строки a с последующим вычислением остатка по модулю простого числа d . Однако, как показывает анализ, это неудачный пример функции хеширования. В самом деле, если A состоит из строк, начинающихся с одинаковых префиксов и имеющих одинаковые суффиксы, например строк вида str1+nom+str2, где nom – цифровая строка от нуля до d -1, то распределение значений функции h будет крайне неравномерным. Значения функции h заполнят только около трети значений множества D = {0,1,…,d -1}. Объясняется это тем, что константные части строк (str1 и str2) не влияют на число различных значений функции h , а т олько производят сдвиг этих значений внутри D , а сумма цифр чисел от 0 до d -1 принимает ограниченное число значений. Для достижения равномерности можно использовать алгоритмы порождения равномерно распределенных псевдослучайных чисел [14, т.2]. В частности, в [7] предлагается использовать следующую функцию: Пусть d не является степенью числа 10, элементы исходного множества определяются числами из интервала 0,1,2,…,K . Пусть C такое число, что dC2 примерно равно K2 . Положим h(m) = |m2 /C| mod d , где |x| — целая часть числа x . Для символьных строк можно рассматривать представление строки в позиционной системе счисления с основанием 256, где каждому символу строки сопоставляется его двоичный код. Тогда в качестве значения m можно выбрать значение числа в системе счисления с основанием 256. Например, строке ‘abcd’ соответствует число ord (a)q3 + ord (b)q2 + ord (c)q + ord (d) при q = 256 .
Статьи к прочтению:
- H. неряшливо или вычурно одетые участники к шествию в колонне допускаться не должны!
- Хочешь интересно жить – читай!
Информатика. Структуры данных: Разрешение коллизий хеширования. Центр онлайн-обучения «Фоксфорд»
Похожие статьи:
-
Таблица с вычисляемым адресом (преобразованием ключа в адрес) представляет собой вектор из N ключей с индексами от 0 до N-1. Поиск элемента начинается с…
-
Разрешение коллизий методом открытой адресации.
Другой путь решения проблемы, связанной с коллизиями, состоит в том, чтобы полностью отказаться от ссылок, и просматривать различные записи таблицы одну…