
Компьютеры с суперскалярной обработкой
Еще одной разновидностью однопотоковой архитектуры является суперскалярная обработка. Смысл этого термина заключается в том, что в аппаратуру процессора закладываются средства, позволяющие одновременно выполнять две или более скалярные операции, т.е. команды обработки пары чисел. Суперскалярная архитектура базируется на многофункциональном параллелизме и позволяет увеличить производительность компьютера пропорционально числу одновременно выполняемых операций. Способы реализации суперскалярной обработки могут быть разными.
Аппаратная реализация суперскалярной обработки применяется как в CISC, так и в RISC — процессорах и заключается в чисто аппаратном механизме выборки из буфера инструкций (или кэша инструкций) несвязанных команд и параллельном запуске их на исполнение. Этот метод хорош тем, что он «прозрачен» для программиста, составление программ для подобных процессоров не требует никаких специальных усилий, ответственность за параллельное выполнение операций возлагается в основном на аппаратные средства.
VLIW-архитектуры суперскалярной обработки. Второй способ реализации суперскалярной обработки заключается в кардинальной перестройке всего процесса трансляции и исполнения программ. Уже на этапе подготовки программы компилятор группирует несвязанные операции в пакеты, содержимое которых строго соответствует структуре процессора. Например, если процессор содержит функционально независимые устройства (сложения, умножения, сдвига и деления), то максимум, что компилятор может «уложить» в один пакет — это четыре разнотипные операции; (сложение, умножение, сдвиг и деление). Сформированные пакеты операций преобразуются компилятором в командные слова, которые по сравнению с обычными инструкциями выглядят очень большими. Отсюда и название этих суперкоманд и соответствующей им архитектуры — VLIW (Very Large Instruction Word — очень широкое командное слово). По идее, затраты на формирование суперкоманд должны окупаться скоростью их выполнения и простотой аппаратуры процессора, с которого снята вся «интеллектуальная» работа по поиску параллелизма несвязанных операций. Однако практическое внедрение VLIW-архитектуры затрудняется значительными проблемами эффективной компиляции.
Архитектуры класса SISD охватывают те уровни программного параллелизма, которые связаны с одиночным потоком данных. Они реализуются многофункциональной обработкой и конвейером команд.
Параллелизм циклов и итераций тесно связан с понятием множественности потоков данных и реализуется векторной обработкой. В таксономии компьютерных архитектур М. Флина выделена специальная группа однопроцессорных систем с параллельной обработкой потоков данных – SIMD.
SIMD-компьютеры
SIMD (Single Instruction Stream — Multiple Data Stream) или ОКМД — один поток команд и множество потоков данных. SIMD компьютеры состоят из одного командного процессора (управляющего модуля), называемого контроллером, и нескольких модулей обработки данных, называемых процессорными элементами.
 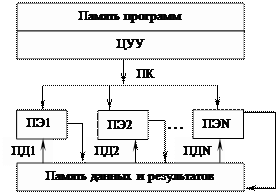 |
Рис. 2.3. SIMD- архитектура
Управляющий модуль принимает, анализирует и выполняет команды. Если в команде встречаются данные, контроллер рассылает на все процессорные элементы команду, и эта команда выполняется на нескольких или на всех процессорных элементах.
Все процессорные элементы идентичны и каждый из них представляет собой совокупность управляюще-обрабатывающего органа (быстродействующего процессора) и процессорной памяти небольшой емкости. Процессорные элементы выполняют операции параллельно над разными потоками данных (ПД) под управлением общего потока команд (ПК), вследствие чего такие ЭВМ называются системами с общим потоком команд. В любой момент в каждом процессоре выполняется одна и та же команда, но обрабатываются различные данные. Реализуется синхронный параллельный вычислительный процесс.
Одним из преимуществ данной архитектуры считается то, что в этом случае более эффективно реализована логика вычислений. До половины логических инструкций обычного процессора связано с управлением выполнением машинных команд, а остальная их часть относится к работе с внутренней памятью процессора и выполнению арифметических операций. В SIMD компьютере управление выполняется контроллером, а арифметика отдана процессорным элементам. Возможны два способа построения компьютеров этого класса. Это матричная структура ЭВМ и векторно-конвейерная обработка.
Матричная архитектура
Суть матричной структуры заключается в том, что имеется множество процессорных элементов, исполняющих одну и ту же команду над различными элементами вектора (потоков данных), объединенных коммутатором. Каждый процессорный элемент включает схемы местного управления, операционную часть, схемы связи и собственную оперативную память. Изменение производительности матричной системы достигается за счет изменения числа процессорных элементов.
Основные их преимущества — высокая производительность и экономичность. Недостатки матричных систем, ограничивающие области их применения, заключаются в жесткости синхронного управления матрицей процессорных элементов и сложности программирования обмена данными между процессорными элементами через коммутатор.
Они применяются главным образом для реализации алгоритмов, допускающих параллельную обработку многих потоков данных по одной и той же программе (одномерное и двумерное прямое и обратное преобразования Фурье, решение систем дифференциальных уравнений в частных производных, операций над векторами и матрицами и др.). Матричные системы довольно часто используются совместно с универсальными однопроцессорными ЭВМ. Примером векторных супер-ЭВМ с матричной структурой является знаменитая в свое время система ILLIAC-IV.
Статьи к прочтению:
- Компьютерные сети как человеко-машинные системы
- Компьютерные вирусы: модель информационной эпидемиологии
Диаграммы Потоков Данных
Похожие статьи:
-
Информационная модель эвм. основные виды обработки данных
Обработка чисел, символьной информации, логическая обработка, обработка сигналов – это все частные случаи общего понятия под названием “обработка…
-
Что такое архитектура и структура компьютера?
Как выполняется команда? Выполнение команды можно проследить по схеме: Общая схема компьютера Как пpавило, этот процесс разбивается на следующие этапы:…