
Перевод чисел в системах счисления с кратными основаниями
Рассмотримправило перевода чисел из восьмеричной системы счисления в двоичную.
Для перевода восьмеричного числа в двоичную систему счисления достаточно заменить каждую цифру восьмеричного числа соответствующим трехразрядным двоичным числом.После этого необходимо удалить нули, стоящие слева от старшего разряда в целой части, а при наличии дробной части – также нули, стоящие справа от младшего разряда в дробной части.
Перевод числа из шестнадцатеричной системы счисления в двоичную выполняется аналогично. Только в этом случае каждая цифра шестнадцатеричного числа заменяется соответствующим четырехразрядным двоичным числом.
Примеры:
Перевести число 305.4 из восьмеричной системы счисления в двоичную.
Решение.
Переводимое число Результат
(3 0 5. 4)(8) = 11000101.1(2)
011 000 101. 100
Перевести число 7D2.E из шестнадцатеричной системы счисления в двоичную.
Решение.
Переводимое число Результат
(7 D 2. E)(16) = 11111010010.111(2)
0111 1101 0010. 1110
Для перевода числа издвоичнойсистемы счисленияввосьмеричную (илишестнадцатеричную) поступают следующим образом: двигаясь от запятой сначала влево, а затем вправо, разбивают двоичное число на группы по три (четыре) разряда, дополняя, при необходимости, нулями крайние левую и правую группы. Затем каждую группу из трех (четырех) разрядов заменяют соответствующей восьмеричной (шестнадцатеричной) цифрой.
Пример. Перевести число 111001100.001 из двоичной системы счисления в восьмеричную, а число 10111110001.001 – из двоичной системы счисления в шестнадцатеричную.
Решение.
Переводимое число Результат
(111 001 100. 001)(2) = 714.1(8)
7 1 4. 1
Переводимое число Результат
(0101 1111 0001. 0010)(2) = 5F1.2(16)
5 F 1. 2
Представление информации в цифровых
Автоматах
Для автоматизации работы с данными, относящимися к различным типам, очень важно унифицировать их форму представления. Для этого обычно используется прием, называемый кодированием.Суть кодирования состоит в выражении данных одного типа через данные другого типа. Естественные человеческие языки – это не что иное, как системы кодирования понятий для выражения мыслей посредством речи. К языкам близко примыкают азбуки (системы кодирования компонентов языка с помощью графических символов).
В вычислительной технике используется своя система кодирования, называемая двоичным кодированием. Она основана на представлении данных последовательностью всего двух знаков: 0 и 1. Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложьи т.п.). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия:
00 01 10 11
Тремя битами можно закодировать восемь различных значений:
000 001 010 011 100 101 110 111
Увеличивая на единицу количество разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которое может быть выражено в данной системе, то есть, в общем случае:
N = 2 n,
где N – количество независимых кодируемых значений;
n – разрядность двоичного кодирования, принятая в данной системе.
Для представления символьной информации в средствах автоматизированной обработки (например, ЭВМ) также используется двоичное кодирование. Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы, например §, $, / и др.
Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования. Пока это невозможно из-за противоречий между символами национальных алфавитов.
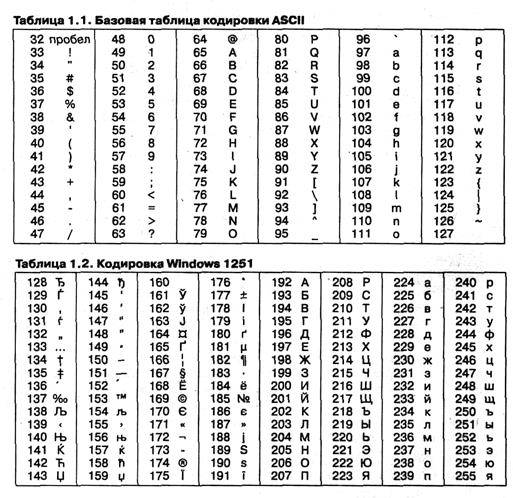
Институт стандартизации США (ANSI – American National Standard Institute)ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange – стандартный код информационного обмена США). В системе ASCIIзакреплены две таблицы кодирования – базовая и расширенная.Базовая таблица закрепляет значения кодов от 0 до 127, расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять процессом вывода прочих данных.
Начиная с номера 32 по номер 127 в таблице ASCII размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Коды букв русского алфавита располагаются в расширенной таблице ASCII (кодировка «Windows — 1251») начиная с номера 192 (рисунок 2).
Аналогичные системы кодирования текстовых данных были разработаны и в других странах. Так, например, в СССР в этой области действовала система кодирования КОИ-7 (код обмена информацией, семизначный). Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) – ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы. Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.
Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось отступить во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255.
В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных – это одна из распространенных задач информатики.
Рисунок 2 – Базовая и расширенная таблицы ASCII
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной – UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов – этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Несмотря на тривиальную очевидность такого подхода, простой механический переход на данную систему долгое время сдерживался из-за недостаточных ресурсов средств вычислительной техники (в системе кодирования UNICODEвсе текстовые документы автоматически становятся вдвое длиннее). Во второй половине 90-х годов технические средства достигли необходимого уровня обеспеченности ресурсами, и сегодня мы наблюдаем постепенный перевод документов и программных средств на универсальную систему кодирования.
Кроме символьных данных современные компьютеры позволяют обрабатывать и другие типы данных, например – графические. Остановимся на способах кодирования таких данных.
Если рассмотреть с помощью увеличительного стекла черно-белое графическое изображение, напечатанное в газете или книге, то можно увидеть, что оно состоит из мельчайших точек, образующих характерный узор, называемый растром. Поскольку линейные координаты и индивидуальные свойства каждой точки (яркость) можно выразить с помощью целых чисел, то можно сказать, что растровое кодирование позволяет использовать двоичный код для представления графических данных. Общепринятым на сегодняшний день считается представление черно-белых иллюстраций в виде комбинации точек с 256 градациями серого цвета, и, таким образом, для кодирования яркости любой точки обычно достаточно восьмиразрядного двоичного числа.
Для кодирования цветных графических изображений применяется принцип декомпозиции произвольного цвета на основные составляющие. В качестве таких составляющих используют три основные цвета: красный (Red, R), зеленый (Green, G) и синий (Blue, B). На практике считается (хотя теоретически это не совсем так), что любой цвет, видимый человеческим глазом, можно получить путем механического смешения этих основных цветов. Такая система кодирования называется системой RGB по первым буквам названий основных цветов.
Если для кодирования яркости каждой из основных составляющих использовать по 256 значений (восемь двоичных разрядов), как это принято для полутоновых черно-белых изображений, то на кодирование цвета одной точки надо затратить 24 разряда. При этом система кодирования обеспечивает однозначное определение 16,5 млн. различных цветов, что на самом деле близко к чувствительности человеческого глаза. Режим представления цветной графики с использованием 24 двоичных разрядов называется полноцветным(True Color).
Каждому из основных цветов можно поставить в соответствие дополнительный цвет, то есть цвет, дополняющий основной цвет до белого. Нетрудно заметить, что для любого из основных цветов дополнительным будет цвет, образованный суммой пары остальных основных цветов. Соответственно, дополнительными цветами являются: голубой (Cyan, C), пурпурный (Magenta, M) и желтый (Yellow, Y). Принцип декомпозиции произвольного цвета на составляющие компоненты можно применять не только для основных цветов, но и для дополнительных, то есть любой цвет можно представить в виде суммы голубой, пурпурной и желтой составляющей. Такой метод кодирования цвета принят в полиграфии, но в полиграфии используется еще и четвертая краска – черная (Black, K). Поэтому данная система кодирования обозначается четырьмя буквами CMYK (черный цвет обозначается буквой К, потому, что буква В уже занята синим цветом), и для представления цветной графики в этой системе надо иметь 32 двоичных разряда. Такой режим тоже называется полноцветным(True Color).
Если уменьшить количество двоичных разрядов, используемых для кодирования цвета каждой точки, то можно сократить объем данных, но при этом диапазон кодируемых цветов заметно сокращается. Кодирование цветной графики 16-разрядными двоичными числами называется режимом High Color.
При кодировании информации о цвете с помощью восьми бит данных можно передать только 256 цветовых оттенков. Такой метод кодирования цвета называется индексным. Смысл названия в том, что, поскольку 256 назначений совершенно недостаточно, чтобы передать весь диапазон цветов, доступный человеческому глазу, код каждой точки растра выражает не цвет сам по себе, а только его номер (индекс) в некоей справочной таблице, называемой палитрой. Разумеется, эта палитра должна прикладываться к графическим данным – без нее нельзя воспользоваться методами воспроизведения информации на экране или бумаге (точнее, воспользоваться, конечно, можно, но из-за неполноты данных полученная информация не будет адекватной: листва на деревьях может оказаться красной, а небо – зеленым).
Статьи к прочтению:
- Периферийные устройства — это устройства, с помощью которых информация вводится или выводится из в компьютера.
- Периферийные устройства вычислительной техники
Перевод чисел, системы счисления с основанием 2, 8, 16
Похожие статьи:
-
Перевод чисел из одной системы счисления в другую.
Лекция №4 Системы счисления. План 1. Непозиционные и позиционные системы счисления. 2. Системы счисления, используемые в электронно-вычислительных…
-
Представление числовых данных. перевод чисел в позиционных системах счисления
ЛЕКЦИЯ №2. ПРЕДСТАВЛЕНИЕ ДАННЫХ НА ЭВМ План o Общее представление данных и понятие о системах счисления. o Структура данных. Единицы хранения данных….