
Рис1. частичное синтаксическое дерево для программы copychar
В отличие от обычных деревьев, синтаксические деревья растут сверху вниз. В данном случае, корнем дерева является элемент ,конечные узлы дерева называются листьями.
Данное дерево не показывает нам подробности строения , но результат его построения показывается присоединенным пунктирной линией, сигнализируя о том, что результаты были сокращены.
Проходя по листьям дерева слева направо, мы получаем следующее:
PROGRAM CopyChar(INPUT, OUTPUT);.
Это законченная программа, за исключением элемента , синтаксическое правило которого еще не было дано и поэтому не может быть заполнено.
На рисунке 2 показано полное построениеCopy1
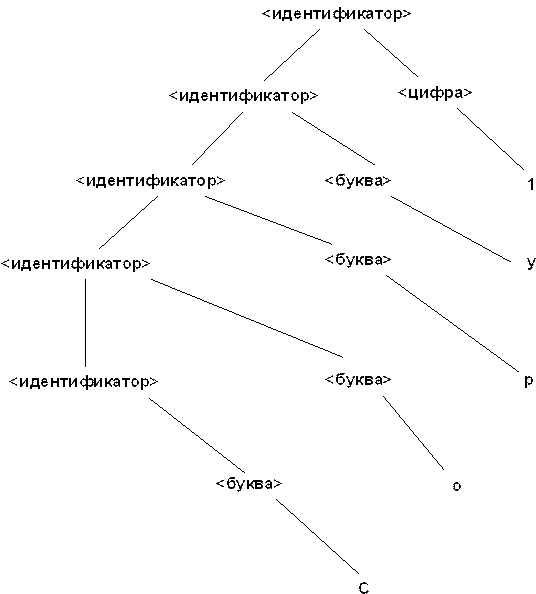
Рис. 2. Синтаксическое дерево дляCopy1
Когда синтаксическое дерево построено с использование всех необходимых правил синтаксиса, листья этого дерева должны явно присутствовать в программе. Когда мы проходим слева направо по листьям дерева, вставляя где положено пробелы, они как бы проговаривают нам элемент программы, название которого находится в корне дерева. Например, часть рисунка 1, изображенная на рисунке 3, показывает, что дерево с корнем , может построить следующее:
PROGRAM CopyChar(INPUT, OUTPUT)
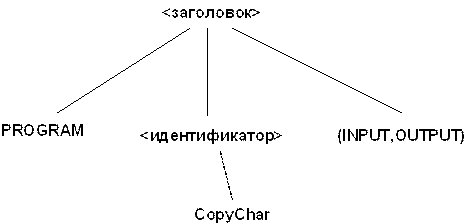
Рис 3. Синтаксическое дерево
Иными словами
PROGRAM CopyChar (INPUT, OUTPUT)
является . Когда мы говорим о , мы имеем в виду эту строку. Но обычно значение идентификатора не имеет большого значения, и ссылка наобозначает любую строку, которая может быть таким образом построена. В данном случае единственная часть дерева, которая может меняться – это .
Синтаксические деревья могут быть использованы для доказательства корректности любой последовательности символов являющейся элементом программы. Начиная с синтаксического правила, имеющего этот элемент слева от знака ::=, дерево строится по этому и другим синтаксическим правилам. Синтаксис последовательности символов считается корректным, если он формируется из листьев дерева путем вставки соответствующих пробелов. Основное правило вставки идентификаторов гласит:
1. Пробелы не могут быть помещены внутрь
2. Пробел должен быть помещен между стандартными словами и идентификаторами, за исключением случаев, когда вставлен символ пунктуации. Пробел может быть вставлен перед или после стандартных слов, идентификаторов и символов пунктуации
3. Там, где может быть помещен один пробел, там может быть помещено любое их количество.
4. Разрыв строки может быть помещен в любом месте, где может быть помещен пробел. Однако разрыв строки не заменяет пробел в пункте 2.
Например, дереворассмотренное выше, показывает, что
PROGRAM CopyChar (INPUT, OUTPUT)
является , как и
PROGRAM
CopyChar
(INPUT, OUTPUT)
показывая различные случаи расстановки пробелов и разрывов строк. В некоторых Паскаль-машинах разрыв строки игнорируется. В других – он заменяет пробел. Правило 4 является консервативным и безопасным при любых обстоятельствах.
В качестве проверки правильного построения синтаксического дера\ева, номера синтаксических правил, используемые при построении, могут быть приписаны к каждому узлу, как показано на рисунке 4 дляB4U

Рис 4. Синтаксическое дерево дляB4U
По мере накопления опыта доказательство корректности синтаксиса станет для вас простым. Вы станете делать это на полном автоматизме. Как только вы прочувствуете идею, очень редко вам придется рисовать синтаксические деревья.
Синтаксис блока.
Синтаксис элементаописывается синтаксическим правилом 6.
SR6.:==;
|
SR7.:== VAR: CHAR
SR8.:==
|,
Помимо синтаксических правил, программы CF-Pascal должны удовлетворять следующим контекстным правилам:
Статьи к прочтению:
Алексей Охрименко — Парсеры — это Спарта
Похожие статьи:
-
Алгоритм для реализации синтаксического анализатора
КУРСОВАЯ РАБОТА по дисциплине Языки и методы программирования На тему: «Разработка синтаксического анализатора на языке С#: арифметические выражения_1»…
-
Задача поиска. красно-черные деревья. задача балансировки для красно-черных деревьев.
Красно-черное дерево — это двоичное дерево поиска, обладающее следующими свойствами (будем называть их RB свойствами): 1. Каждый узел дерева покрашен…