
Семантической обработки (окончание)
Для распознавания каждого ключевого слова можно построить свой автомат. В этом случае возникает несколько проблем:
– замедляется разбор, что связано с постоянными откатами, используемыми в непрямом лексическом анализаторе (чем больше автоматов, тем медленнее разбор, а ключевых слов может быть много);
– состав ключевых слов может постоянно меняться (особенно, в новом языке), что ведет к необходимости модификации кода программы.
Гораздо проще и быстрее провести распознавание ключевых слов с использованием семантической обработки. Чаще всего (а в данном случае – это факт) ключевые слова являются подмножеством идентификаторов. Поэтому, можно в начале осуществить выявление идентификатора, а затем провести его анализ на принадлежность к ключевому слову. Такой анализ можно осуществлять поиском (лучше всего двоичным) значения полученного идентификатора в таблице ключевых слов. При обнаружении совпадения формируется лексема, соответствующая выявленному ключевому слову. В противном случае выдается лексема — идентификатор. Соответствующая этому случаю диаграмма Вирта, вместе с блоком семантического разбора (представленного шестиугольником) приведена на Рисунке 7.1б. Аналогичную схему имеет смысл использовать и в прямом лексическом анализаторе.
Диаграммы Вирта для отдельных автоматов непрямого лексического анализатора
Диаграммы Вирта, описывающие отдельные независимые фрагменты непрямого лексического анализатора, представлены на Рисунке 7.2. В отличие от диаграмм, используемых для описания пользовательского синтаксиса, данные схемы помечены именами, которые предполагается использовать в программе. Выходы диаграмм идентифицируют порождаемые лексемы. Каждая из диаграмм непосредственно не связана с механизмом отката. Этим занимается сам анализатор.

Примечание 1. Лексема, порождаемая при достижении конца обрабатываемого текста.
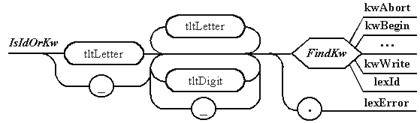
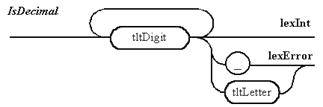
Примечание 2. Идентификатор и ключевые слова описываются правилом с семантической вставкой. Осуществляется также анализ на недопустимость возможного слияния идентификатора с действительным числом, начинающимся с точки.
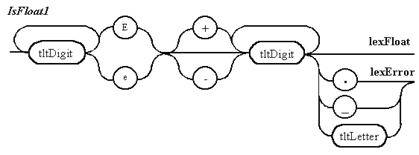
Рисунок 7.2 Описание с помощью диаграмм Вирта лексем, распознаваемых непрямым лексическим анализатором
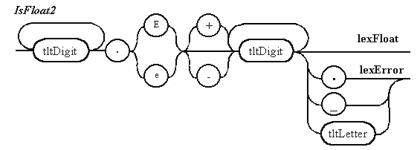
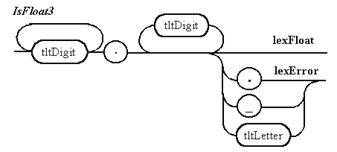
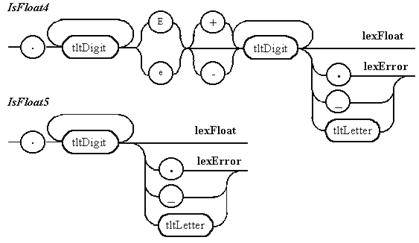
Рисунок 7.2 Описание с помощью диаграмм Вирта лексем, распознаваемых непрямым лексическим анализатором (продолжение)
Примечание 3. Пять вариантов правил для распознавания действительного числа приводятся только для демонстрации арбитража при непрямом лексическом анализе. На практике легко можно обойтись одним правилом. Выдача ошибки происходит, если действительное число не отделяется разделителем от идентификатора или другого действительного числа, начинающегося с десятичной точки.
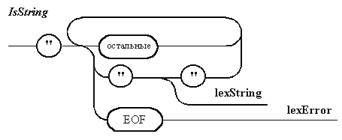
Примечание 4. Под остальными понимаются все символы, кроме кавычек и конца файла.
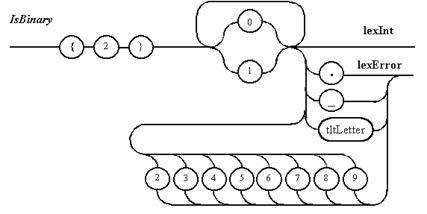
Рисунок 7.2 Описание с помощью диаграмм Вирта лексем, распознаваемых непрямым лексическим анализатором (продолжение)
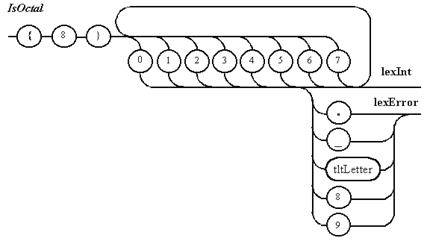
Примечание 5. Для двоичных и десятичных целых чисел необходима проверка того, что оно не сливается с теми цифрами, которые в них не содержаться.
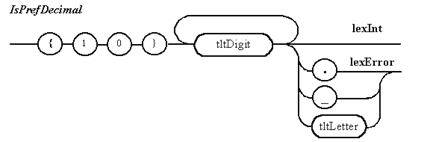
Примечание 6. Для целого десятичного числа без префикса анализ на недопустимость точки излишен, так как такая ситуация должна была быть проанализирована раньше для действительного числа.
Рисунок 7.2 Описание с помощью диаграмм Вирта лексем, распознаваемых непрямым лексическим анализатором (продолжение)
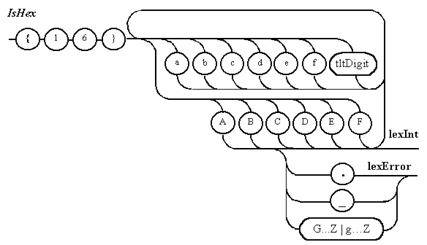
Примечание 7. Для целого шестнадцатеричного числа проверка на недопустимость должна исключать прописные и строчные буквы, используемые в самом числе. На представленных диаграммах это показано сокращенной записью путем задания диапазона. Это сделано для того, чтобы не загромождать диаграмму деталями.
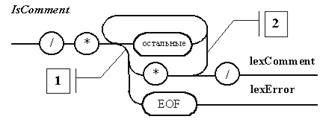
Примечание 8. Под остальными понимаются символы, не рассматриваемые в текущей точке. В точке 1 – это не «*» и не конец файла; в точке 2 – это не «*», не конец файла и не «/».

Рисунок 7.2 Описание с помощью диаграмм Вирта лексем, распознаваемых непрямым лексическим анализатором (продолжение)
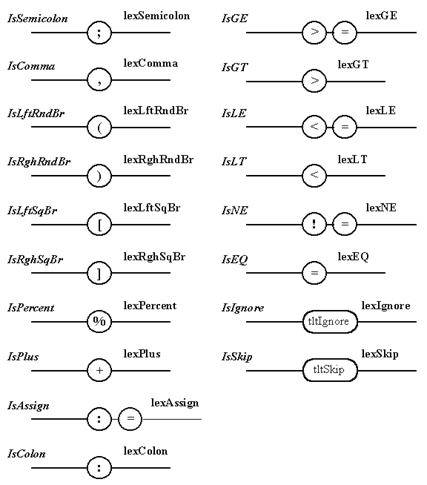
Примечание 9. Лексемы, определяющие разделительные символы, расположены в соответствие с их приоритетом при анализе сверху вниз и слева направо.
Рисунок 7.2 Описание с помощью диаграмм Вирта лексем, распознаваемых непрямым лексическим анализатором (окончание)
Статьи к прочтению:
ВАЖНО!!! ОБРАБОТКА ВЯЗАННЫХ ИЗДЕЛИЙ!!! ОШИБКИ, КОТОРЫЕ УНИЧТОЖАТ ВЕСЬ ВАШ РЕЗУЛЬТАТ РАБОТЫ!!!
Похожие статьи:
-
Создание и обработка графических объектов
Лекция № 5 Новые возможности текстового процессора WORD Возможность импорта многих графических форматов, редакторов формул, программ деловой графики и…
-
Элементы обработки и интерпретации георадарных данных
В результате измерений полученные данные в каждой точке складываются в волновую картину (радарограмму) представляющую собой ансамбль записей сигналов,…