
Втоматический анализ и синтез звучащей речи этапы автоматического анализа речи.
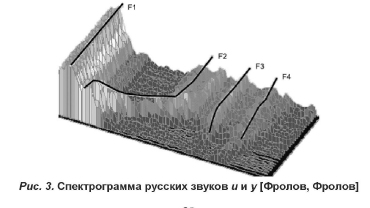
Одним из первых важных шагов использования информационных технологий в лингвистике является дигитализация текстов — переведение языкового материала, существующего в печатном или устном виде, в цифровую форму. Именно в этом случае появляется возможность привлечения компьютеров для выполнения определенных операций над текстами на естественном языке: их преобразования, выделения их них отдельных элементов и создания (синтеза) аналогичных текстов. В связи с принципиальными различиями в способах дигитализации и обработки звучащей речи и печатных текстов в нашей работе эти явления рассматриваются в разных параграфах. Первый параграф посвящен вопросам автоматической обработки и синтеза звучащей речи, а во всех последующих рассматриваются автоматические операции, производимые над печатными текстами. При автоматическом анализе звучащей речи она преобразуется в печатный текст, над которым можно производить дальнейшие операции. Автоматический синтез звучащей речи представляет собой обратный процесс преобразования печатного текста, существующего в цифровой форме, в звучащий текст на естественном человеческом языке. Процесс автоматического анализа речи включает следующие этапы: 1) ввод звучащей речи в компьютер с помощью микрофона. 2) выделение компьютерной программой в звуковом потоке отдельных знаков. 3) идентификация выделенных знаков звучащей речи со знаками языка. Минимальными знаками звучащей речи являются звуки, производимые артикуляторным аппаратом человека. Каждый звук имеет свои акустические характеристики (высота, частота колебаний звуковых волн и т.д.), которые можно измерить специальными приборами (например, осциллографом). Параметры звукового сигнала непрерывно меняются, и такой (непрерывный) тип сигнала называется аналоговым. В отличие от аналогового, цифровой сигнал представляет собой набор дискретных (отдельных) числовых значений, фиксирующих разные уровни звуковой волны. При использовании микрофона аналоговый звуковой сигнал преобразуется в аналоговый электрический, который с помощью аналогово-цифровых преобразователей, встроенных в звуковые карты современных компьютеров, переводится в дискретный цифровой сигнал [49]. Первые устройства автоматического распознавания устной речи, которых на сегодняшний день большинство, в качестве выделяемых в речевом потоке знаков использовали не звуки, а слова. Слова вводимой в компьютер речи идентифицировались со словами, заранее записанными диктором, читающим слова. Но такой тип распознавания речи связан с определенными ограничениями: • личность говорящего: автомат распознает речь только определенного говорящего, • запас слов: автомат распознает только ограниченное количество слов, • подготовленность речи: автомат распознает речь, лишь если она подготовлена [25, 39]. Для преодоления этих ограничений требуется, чтобы компьютерная программа распознавала не слова, а звуки, т.е. работала не с дискретной речью (которая содержит паузы между словами), а со слитной естественной человеческой речью. В основе пофонемного распознавания звуков речи лежит анализ 1) длительности и динамики звучания, 2) чередования акустического сигнала и пауз. При этом на основе универсальной классификации звуков Гуннара Фанта, Морриса Халле и Романа Якобсона акустические признаки звуков выводятся из артикуляционных. Правда, акустические признаки в отношении к артикуляционным оказываются недостаточно универсальными. Кроме того, в этой теории недостаточно учитывается слогоделение, акцентуация и ритм (главные носители смысла) [25, 39]. В настоящее время наиболее доступной формой точной фиксации звучащей речи (в том числе ее тембра и динамики) становится спектрограмма — фотографическое изображение звуков. Результаты наблюдений показывают, что в произнесении звуков активно используются четыре частоты называемые формантами. Так, на рис. 3. изображены форманты русских звуков и и у. При переходе от звука и к звуку j наиболее заметно изменение форманты F2 (рис. 3). Задачей автоматического анализа звучащей речи при использовании спектрограмм становится перевод спектрограмм в фонологическую транскрипцию [25, 41].
В итоге процесс автоматического анализа речи включает ввод слов в компьютер через микрофон, начитанных разными дикторами, их спектральную обработку и создание набора признаков, своеобразного образца слова, который выступает знаком языка. При распознавании звучащей речи реальные признаки составляющих ее единиц сравниваются с признаками и образцами слов, существующими в памяти машины. Результатом сравнения является транскрипция или орфографическая запись слова. Но при автоматическом анализе слитной речи дополнительную трудность составляет отсутствие четких границ между словами. Человек для преодоления этой трудности кроме акустических сигналов обычно использует самые разные другие источники информации: ситуацию, контекст, структуру языкового высказывания, прошлый опыт в данной области и т.п. Аналогичные правила ученые пытаются применить и к машинам и стремятся задействовать в современных системах анализа речи кроме акустического другие уровни системы языка: лексический, синтаксический, семантический, прагматический. Включение семантического уровня в автоматический анализ речи приводит, в частности, к следующим последствиям: 1) машина устанавливает, что введенные предложения многозначны и правдоподобны; 2) машина прогнозирует, что в определенных речевых контекстах могут возникать определенные типы общения; в зависимости от такого прогнозируемого типа общения машина интерпретирует предложение [35, 120]. Очевидно, что создание систем анализа речи такого сложного уровня предусматривает сотрудничество представителей самых разных специальностей. Для экономии времени и усилий ученых и практиков различные компании, в том числе Microsoft, выпускают средства анализа и синтеза речи в виде программных модулей и интерфейсов. Программисты, не обладающие познаниями в области лингвистики, математики и биологии, могут использовать готовые интерфейсы и программные модули в собственных разработках. Правда, в этом случае речевые возможности программ будут ограничены использованными средствами и технологиями. Например, многие средства анализа и синтеза речи не способны работать с русским языком, что ограничивает их использование в России [49]. Можно назвать следующие примеры программ, в которых применяются средства автоматического анализа речи: • программы голосового управления компьютером и бытовой техникой VoiceNavigator и Truffaldino (компания «Центр речевых технологий», С.-Петербург); • комплекс голосового управления мобильным телефоном DiVo («Центр речевых технологий»); • программный модуль Voice Key для идентификации личности по парольной фразе длительностью 3—5 секунд («Центр речевых технологий»); • программы диктовки текста на английском языке: VoiceType Dictation (IBM), DragonDictate («Dragon Systems»); на русском языке: Комбат («Байт Груп») к Диктограф («Voice Member Technology))); • система распознавания речи, встроенная в Microsoft Office ХР (работает только с английским языком); • голосовой поиск (например, в поисковой системе Google). Так, программа VoiceNavigator позволяет запускать компьютерные приложения и выполнять заданные команды голосом без использования клавиатуры. Перед применением программы ее необходимо обучить, произнеся в микрофон слова команд (команды можно произносить на любом языке и любым голосом). Чтобы программа начала распознавать голосовые команды, ее необходимо «разбудить», произнеся ключевое слово [49]. Использование модулей распознавания речи весьма перспективно в различных областях деятельности: в обслуживании клиентов, проведении судебных экспертиз, биометрии, обучении, научных исследованиях и т.д. Но массовое внедрение речевых технологий тормозится высокой стоимостью разработок и предлагаемых технологий, а также их пока еще низким качеством. В целом задача автоматического анализа речи является весьма сложной и решена лишь отчасти. В сравнении с ней задача автоматического синтеза речи оказывается более простой, и с примерами ее массового использования в обиходной жизни мы сталкиваемся постоянно. В частности, автоматически синтезируется речь в следующих ситуациях: • называние текущего времени по телефону, • объявление остановок в метро, • называние остатка средств на счету и другие услуги мобильных операторов, • оповещение систем гражданской безопасности и т.д. Автоматический синтез (генерация) речи в настоящее время осуществляется путем составления слов и фраз из заранее записанных диктором образцов отдельных звуков (метод компилятивного синтеза) или путем моделирования речевого тракта человека {формантно-голосовой метод)[49]. Первый метод используется главным образом для синтеза относительно небольшого и заранее известного набора фраз. При этом обеспечивается довольно высокое качество звучания, поскольку синтезируемая речь базируется на элементах естественной человеческой речи. Тем не менее на стыке составляемых звуковых фрагментов возможны интонационные искажения и разрывы, заметные на слух. Кроме того, создание крупной базы данных звуковых фрагментов, учитывающей все особенности произношения фонем с разными интонациями, представляет собой сложную и кропотливую работу. Второй метод оказывается более сложным, поскольку здесь необходимо точное моделирование особенностей речевого тракта человека, а также учет интонационной модуляции речи. В силу названных особенностей формантно-голосовая модель обладает относительно низкой точностью синтезируемых звуков речи. В качестве примера программы, синтезирующей речь, можно назвать программу Govorilka (разработчик: А. Рязанов, бесплатная версия программы размещена по адресу http://www.vector-ski.com/vecs/ govorilka). Основные особенности данной программы состоят в следующем: • программа читает текст разными голосами и на разных языках, в том числе на русском; • исходный текст для чтения может быть загружен из текстового файла или набран в окне программы при помощи клавиатуры; • можно сохранить результаты синтеза речи, записав файл формата WAV или МРЗ. Таким образом, несмотря на мощность современных компьютеров, проблема оснащения компьютера полноценным речевым интерфейсом еще далека от своего завершения. Главной проблемой при создании программ автоматического распознавания речи является то, что компьютер не умеет работать со смыслом. В синтезе речи уже имеются определенные достижения, которые внедрены в массовую практику
Статьи к прочтению:
Задание № 21 ЕГЭ по русскому языку. Лингвистический анализ текста, стили и типы речи
Похожие статьи:
-
Втоматический анализ и синтез текста
Автоматический анализ текста включает ряд весьма сложных операций, которые компьютер выполняет над текстом на естественном человеческом языке согласно…
-
Системы автоматического синтеза речи
Методы: 1)Кодирование (запись в двоичной системе речевых сигналов с их последующим восстановлением) а)По существу ПК здесь служит устройством для записи…