
Системы с конвейерной обработкой информации 1 страница
При обсуждении способов параллельной обработки информации было отмечено, что одним из способов как раз и является способ конвейерной обработки. Различают два вида конвейера: конвейер команд и конвейер данных. Первым появился и сразу нашел широкое применение конвейер команд. Практически все современные ЭВМ используют этот принцип обработки. Наряду с этим во многих вычислительных системах используют и конвейер данных. Сочетание этих двух конвейеров позволяет достигнуть очень высокой производительности, особенно если используется несколько процессоров, способных работать одновременно и независимо друг от друга. Именно этот подход и используется при построении современных самых высокопроизводительных систем.
История развития вычислительной техники России может быть представлена одним из наиболее удачных образцов ЭВМ БЭСМ-6, имеющей конвейер команд. Машина была разработана под руководством академика С.А. Лебедева в 1966 г. и достаточно долго была одной из самых быстродействующих и востребованных в стране, благодаря целому ряду удачных решений, в том числе и конвейеру команд. Работа конвейера обеспечивалась многомодульной памятью (восемь независимых модулей), работающей по принципу чередования адресов, и большого числа быстрых регистров процессора, предназначенных для буферизации команд и данных. Производительность в 1 млн. операций для своего времени была вполне приемлемой. Это позволило более 30 лет эксплуатировать ее для выполнения ответственейших и сложных расчетов, обеспечивая общий высокий уровень отечественных разработок в различных областях деятельности.
Нельзя обойти вниманием и зарубежные вычислительные системы этого класса, такие, например, как IBM 360/370. Оперативное запоминающее устройство — ОЗУ, процессор команд, операционные устройства – процессоры для выполнения операций с плавающей запятой, с фиксированной запятой и десятичной арифметики работают одновременно и независимо друг от друга. Как и у БЭСМ-6, ОЗУ названной системы построено по модульному
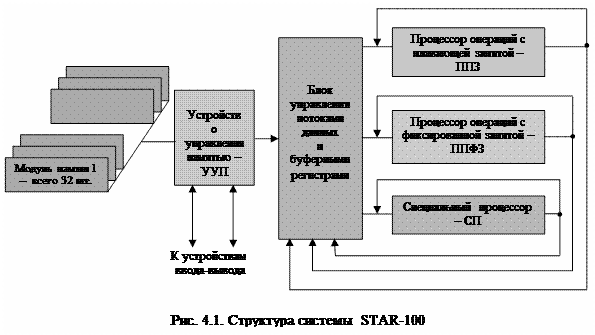
принципу и обеспечивает 8- или 16-кратное чередование адресов, которое обеспечивается устройством управления памятью, работающим также по принципу конвейера. В системах IBM 360/370 кроме конвейеров команд используется также и конвейерная обработка данных. Конвейеры в каждом цикле производят выборку до 8 команд, расшифровку 16 команд, до 3 операций над адресами, до 3 процессорных операций. Всего в системе одновременно обрабатывается до 50 команд. Еще один пример конвейерных систем – система STAR-100, разработанная фирмой CDC в 1973 г. Система имеет оба типа конвейера, содержит три процессора: ППЗ – процессор сложения и умножения данных в форме с плавающей запятой; ППФЗ – процессор, содержащий конвейерное устройство сложения с плавающей запятой, конвейерное многоцелевое устройство умножения и деления с фиксированной запятой и извлечение квадратного корня; СП – специальный конвейерный 16-разрядный процессор, выполняющий операции с фиксированной точкой и логические операции.
Оперативное запоминающее устройство построено по модульному принципу и работает с чередованием адресов под управлением устройства управления памятью – УУП. Время обращения к одному модулю памяти (цикл памяти) составляет 40 нс. и каждый сегмент конвейерных процессоров через каждые 40 нс. выдает результаты в следующий сегмент, а в конечном итоге в блок управления потоками данных.
Процессоры оперируют с 32- или 64-разрядными словами или числами. Обобщенная структура системы представлена на рисунке 4.1.
 |
.






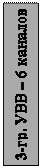

 Конвейерные процессоры не всегда настраивают на одну определенную операцию. Чаще всего их делают многоцелевыми,
Конвейерные процессоры не всегда настраивают на одну определенную операцию. Чаще всего их делают многоцелевыми,
вводя количество сегментов, реализующих полный набор операций, а в зависимости от выполняемых операций весь тракт конвейера настраивается соответствующим образом.
Из общего числа конвейерных систем нельзя обойти вниманием систему CRAY, появившуюся в середине 70-х годов прошлого века. Через некоторое время система стала известна, как один из самых высокопроизводительных суперкомпьютеров мира. В нем в максимальной степени используются оба вида конвейера: конвейер команд и конвейер арифметических и логических операций.
Схематически архитектура CRAY представлена на рисунке 4.2. Здесь применена совмещенная обработка информации несколькими устройствами. Что и позволило достичь очень высокой производительности системы – до 250 млн. операций в секунду при решении научно-технических задач.
Оригинально выполнена конструкция машины – в виде разворачивающейся книги. «Страницами книги» являются панели, на которых смонтирована вся электроника компьютера. Функционально вся система CRAY разделена на четыре части – секции: управления программой, функциональных устройств, регистров, памяти и ввода-вывода. Секция функциональных устройств состоит из 12 процессоров, работающих в режиме конвейера, разбитых на четыре группы: адресную, скалярную, операций с плавающей запятой и векторную. Конвейеры процессоров состоят из различного числа, от 1 до 14, сегментов (указано в круглых скобках) в зависимости от сложности выполняемых операций. Каждый сегмент выполняет свою операцию за 12,5 нс (частота процессора порядка 80 Мгц), это означает, что через 12,5 нс любой процессор выдает результат.
Память организована в виде 16 блоков с независимым управлением, 16-кратным чередованием адресов, общей емкостью 4 млн. 64-разрядных слов (порядка 32 Мбайт). Оригинальным является строение блока. Блок включает в себя 72 модуля, каждый из которых содержит один разряд всех 64 кслов (всего 1152 модуля). Таким образом, одна строка блока памяти содержит 72-разрядное слово, в котором, 64 разряда являются информационными, а 8 разрядов используются для обнаружения одиночных и двойных ошибок. Цикл обращения к памяти составляет 50 нс.
Высокое быстродействие системы достигается за счет большого количества регистров различного назначения. Три группы регистров имеют свои названия: адресные – А-регистры, скалярные –S-регистры и векторные – V-регистры. Можно одновременно формировать и хранить в адресных регистрах восемь адресов, длиной 24 разряда каждый. Скалярная группа имеет так же восемь, но уже 64-разрядных регистров. Векторных регистров тоже 8, из ко-
торых каждый может содержать значения 64 векторов, причем вектор состоит из 64 элементов (вспомните вектор представления числа в двоичном виде). Время обращения к отдельному регистру достаточно мало и составляет всего 6 нс. Из рисунка видно, что между ОЗУ , А-, S- и V-регистрами в системе имеется еще две дополнительные группы: 24-разрядные В-регистры и 64-разрядные Т-регистры. Такое количество регистров позволяет конвейерным процессорам работать с максимально возможной для них скоростью, практически без обращения к ОЗУ. Операнды берутся из регистров, а результаты операций отправляются в регистры. В системе имеется еще одно новшество – благодаря регистрам, конвейеры процессоров могут связываться в цепочки, и тогда результат, полученный одним процессором, является входной величиной конвейера другого процессора.
Состав операций системы является универсальным, только вместо деления выполняется операция вычисления обратной величины. Число операций – 128. Команды могут быть двух форматов – 16 и 32-разрядные.
Ввод-вывод информации осуществляется через 24 канала, разбитых на четыре группы, из которых часть работает только на вывод, а другая часть только на ввод. Входная и выходная информация представляется двухбайтными последовательностями.
Операционная система обеспечивает мультипрограммную обработку 63 задач, имеет оптимизирующий компилятор с фортрана, распознающий циклы, макроассемблер, библиотеку стандартных программ, загрузчик и другие средства.
Все перечисленное обеспечивает системе CRAY высокую производительность
Матричные системы
Ранее было дано определение вычислительной системы. Здесь мы рассмотрим наиболее интересные структуры этого типа систем и начнем это делать с матричных систем. На первый взгляд организация матричных систем достаточно проста. Система содержит, как правило, 2n обрабатывающих устройств (часто их называют процессорными элементами – ПЭ), соединенных в виде матрицы и общее управляющее устройство. Процессорные элементы, работая параллельно и независимо, обрабатывают по единым командам каждый свой поток данных. Характер связей между процессорными элементами может быть различен, так же как и характер их взаимодействия. Это в конечном итоге определяет и различные свойства систем. Матричные системы относятся к классу ОКМД и лучше всего приспособлены для решения задач, характе-ризующихся параллелизмом независимых объектов или паралле-
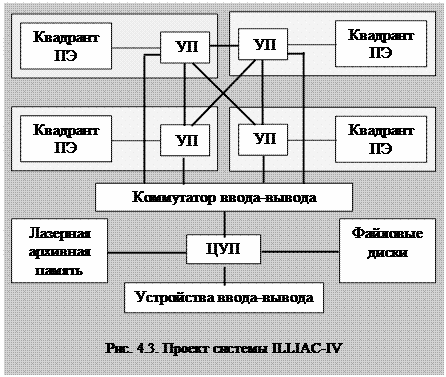 лизмом данных. Примером реализации такой архитектуры является достаточно широко известная система ILLIAC-IV, разработанная Иллинойским университетом (США) и изготовленная фирмой «Барроуз» в 1974 году. Она оказалась практически первой реализованной матричной системой. Проект системы ILLIAC-IV показан на рис. 4.3.
лизмом данных. Примером реализации такой архитектуры является достаточно широко известная система ILLIAC-IV, разработанная Иллинойским университетом (США) и изготовленная фирмой «Барроуз» в 1974 году. Она оказалась практически первой реализованной матричной системой. Проект системы ILLIAC-IV показан на рис. 4.3.
Проектом предусматривалось, что система будет иметь 256 процессорных элементов, разбитых на четыре группы – квадранты: по 64 процессора. Каждый квадрант должен управляться своим специальным управляющим процессором (УП), а система в целом – центральным управляющим процессором (ЦУП). Однако, из-за возникших технологических трудностей с реализацией оперативной памяти на интегральных микросхемах и соответствующих экономических проблем проект был реализован в урезанном объеме. Система была изготовлена и введена в эксплуатацию с одним квадрантом производительностью 200 млн. операций в секунду. И в течение ряда лет считалась самой высокопроизводительной в мире.
Система получилась достаточно интересной и, можно сказать, оригинальной. Процессорные элементы связаны между собой и образуют матрицу размером 8х8 (рис. 4.4).
Пожалуйста, запомните схему связи процессорных элементов для того, чтобы сравнить ее с представленными дальше по тексту матрицами вычислительных систем. Каждый ПЭ связан с четырьмя другими ПЭ. При такой связи передача данных между любыми двумя процессорами осуществлялась не более, чем за 7 тактов (шагов). Каждый ПЭ снабжен собственным ОЗУ и имеет связь с внешней средой, оперирует 64-разрядными словами (числами) и выполняет универсальный набор операций.
Быстродействие процессоров было достаточно высоким. Например, операция сложения выполнялась за 240 нс, а умножения за
400 нс. таким образом, процессор выполнял в среднем 3 млн. опе-раций в секунду, а следовательно производительность системы равнялась 3х64=200 млн. операций в секунду.
 |
Емкость памяти процессорного элемента, по современным меркам, была небольшой: 2048 64-разрядных слов, то есть 16 кбайт, а длительность цикла обращения к памяти 350 нс – доста точно приличной. Эта память имела также связи через устройство управления квадрантом с центральным устройством управления комплексом, а через него с устройствами ввода-вывода. Каждый процессор имел счетчик адресов и индексный регистр, так что физический адрес мог формироваться как сумма трех составляющих: адреса, содержащегося в команде для данного ПЭ, кода, содержащегося в индексном регистре устройства управления, и кода, содержащегося в индексном регистре самого процессора. Каждый процессор кроме названных регистров имел пять программно-адресуемых регистров: накапливающийся сумматор, регистр для операндов, регистр, используемый для пересылок данных от одно-го процессора к другому, буферный регистр на одно слово и регистр управления состоянием процессорного элемента емкостью
восемь бит – его называют еще регистром моды. В зависимости от кода (моды или модальности) вносимого в этот регистр устройством управления процессорный элемент (читай процессор) мог становиться активным – выполнять какие-то действия, или оставаться пассивным, или выполнять пересылочные операции между процессорами.
В качестве центрального управляющего устройства использовалась мини-ЭВМ В-6700, осуществляющая управление также внешней памятью на магнитных дисках (файловая память) и лазерной памятью. Магнитные диски имели неподвижные головки на каждой дорожке (128 головок на диск), емкость 128 Мбайт и 256-разрядную шину для передачи данных управляющему устройству. Для выравнивания скоростей передачи данных и работы управляющей ЭВМ использовалась буферная память.
Лазерная память достаточно оригинальна. Информация записывалась на металлическую пленку путем прожигания на ней лазером микроотверстий. Естественно, перезапись информации исключалась, могло выполняться только ее считывание. Емкость этого запоминающего устройства была порядка 140 Гбайт. Время доступа к данным составляло от 0,2 до 5 с. Память использовалась для длительного хранения информации.
Машина В-6700 использовалась также для трансляции программ, предварительной обработки информации, управления запросами на ресурсы системы.
Следует заметить, что разработка программного обеспечения для системы ILLIAC-IV представляла значительную сложность, а высокая производительность обеспечивалась только на задачах определенного типа, например, операции с матрицами, преобразования Фурье и им подобных.
Рассматривая матричные системы нельзя не отметить и отечественные разработки. По характеру межпроцессорных связей к ним может быть отнесена «Параллельная система 200» (ПС-2000), разработанная в начале 80-х годов прошлого века. Система ориентировалась на решение задач, связанных с обработкой геофизической информации, получаемой при поиске нефти и газа, гидролокационных сигналов и изображений. Прогнозировалось также выполнение расчетов устойчивости летательных аппаратов, решение задач плазменной кинетики, задач в частных производных и др. То есть задач, характеризующихся параллелизмом данных, независимых ветвей и объектов, свойственных системам ОКМД. Архитектура системы схематически представлена на рисунке 4.5.
Центральной частью системы являлся, так называемый, мультипроцессор ПС-2000, состоящий из решающего поля и устройства управления. Решающее поле составлял набор устройств обработки – УО (от одного до восьми), каждое из которых содержало восемь
процессорных элементов (ПЭ) – на рисунке выделены цветом. Таким образом, мультипроцессор мог содержать 8, 16, 32 или 64 процессорных элементов. Процессорные элементы в пределе обрабатывали 24-разрядные слова или представления чисел, в которых 20 разрядов отводилось мантиссе, и 4 разряда определяли порядок в шестнадцатеричном виде. Каждый процессорный элемент мог иметь оперативную память емкостью от 4 до 48 Кбайт с циклом обращения к памяти 640 или 940 нс, соответственно (память построена на ферритовых кольцах).
   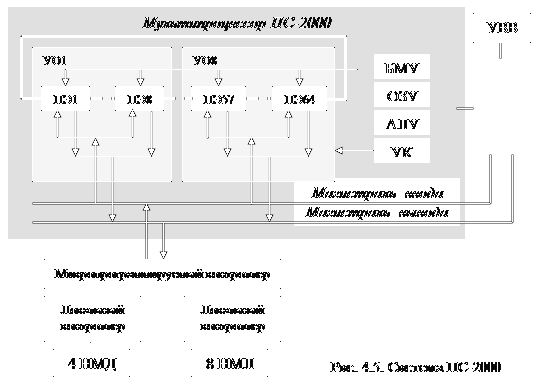 |
Процессорные элементы имели связь друг с другом через, так называемый, регулярный канал, по которому осуществлялся обмен данными между ними. Конфигурация канала перестраивалась программным путем, образуя одно кольцо из 64 элементов или 8 колец по 8 ПЭ, 4 по 16 или 2 по 32.
Интересно построено устройство управления. В ОЗУ загружалась рабочая программа в привычном для нас понимании, команды которой выполнялись в обычном порядке, но эти команды инициировали соответствующие микропрограммы, микрокоманды которых формировали управляющие сигналы, воздействующие на процессорные элементы. ОЗУ могло иметь объем памяти такой же, как и процессорные элементы, то есть до 48 Кбайт. В блок микропрограммного управления (БМУ) загружались микропрограммы обработки данных, ввода-вывода и управления. В базовый комплект микропрограммного обеспечения системы входил набор, обеспечивающий обработку матриц, реализацию быстрого преоб-
разования Фурье, решение задач математической статистики, спектрального анализа, линейного и динамического программирования. Этот комплект мог быть расширен пользовательскими программами в соответствии со своими задачами.
Ввод-вывод данных в память решающего поля, то есть в ОЗУ процессорных элементов инициировался мониторной подсистемой через канал прямого доступа, состоящий из магистралей ввода и вывода, но проводился под управлением устройства управления (УК – управление каналами) мультипроцессора. В системе могли выполняться одновременно обработка данных, ввод и вывод. Ввод данных мог осуществляться со скоростью 1,8 Мбайт/с, а вывод со скоростью 1,4 Мбайта/с.
Вся система в целом управлялась через мониторную подсистему, которая могла содержать одну или две мини-ЭВМ типа СМ-2. К мониторной подсистеме могли подключаться дополнительные периферийные устройства (устройства ввода-вывода) и, в частности, магнитные диски и магнитные ленты. Мини-ЭВМ могли использоваться для разработки и трансляции программ мониторной подсистемы, пользовательских программ и микропрограмм на принятых тогда языках программирования. Мониторная подсистема управляла загрузкой программ в ОЗУ управляющего устройства, контролировала работу мультипроцессора и обеспечивала обмен данными между системой и пользователями.
Для хранения больших объемов информации система была снабжена внешней памятью, подключаемой через программируемый микроконтроллер и имевшей четыре накопителя на магнитных дисках и восемь накопителей на магнитных лентах, управляемых локальными (своими) контроллерами.
Вычислительный процесс заключался в том, что под управлением мониторной подсистемы в управляющее устройство (в его ОЗУ) загружались рабочая программа и набор микропрограмм. Затем инициировался процесс выполнения рабочей программы и по необходимости ввод или вывод данных. Этапы обработки данных перемежались с этапами обмена данными между решающим полем мультипроцессора, его внешней памятью и мониторной подсистемой.
В системе был организован контроль работоспособности, обеспечивающийся двояким способом: схемными средствами, контролирующими корректность хранения и передачи данных и программными – для проверки функционирования системы.
Программное обеспечение было разработано на базе ПО СМ ЭВМ, к которому добавлены модули, организующие работу ПЭ.
Для сравнения с другими подобными системами можно привести интересные данные производительности этой системы: — при
сложении чисел с фиксированной запятой была получена производительность 200 млн. операций в секунду;
— при сложении чисел с плавающей запятой – 66,4 млн. операций/с;
— операция умножения показала производительность 28,5-50 млн. операций/с.
Время выполнения некоторых основных операций в микросекундах составило:
— при умножении матриц 64х64 с плавающей запятой – 1,4;
— при быстром преобразовании Фурье чисел с плавающей запятой – 1,4-2,8.
В заключение следует отметить некоторые особенности, свойственные именно этой системе:
— наличие дополнительной сверхоперативной регистровой памяти ПЭ, ускоряющей операции над адресами;
— наличие процессора активации, обеспечивающего активность или пассивность процессорного элемента;
— возможность совмещенного обмена информацией между модулями памяти ПЭ, АЛУ и устройствами ввода-вывода;
— возможность организации мультипрограммного режима за счет многоуровневой системы прерываний;
— возможность выделения независимых ресурсов для каждой задачи;
— наличие двухуровневого управления: программного и микропрограммного, обеспечивающего более эффективное программирование задач;
— возможность модульного наращивания системы без изменения средств управления.
Ассоциативные системы
Такого класса архитектуры, в принципе нет. Но, чтобы обратить ваше внимание, подчеркнуть существенную особенность архитектуры вычислительной системы, ее выделили в самостоятельный класс. Особенность эта заключается в способе формирования потоков данных. В остальном, они не отличаются, например, от матричных систем. Эти системы, как и матричные, характеризуют-ся большим числом операционных устройств, которые одновременно по командам управляющего устройства выполняют обработку потоков данных. Они также принадлежат к классу ОКМД. Информация на обработку в этих системах выбирается из запоминающих устройств (из памяти) не по адресам, а по ее содержанию.
Содержание идентифицируется каким-либо признаком, например, специфичным кодом. То есть между кодом и содержанием существует связь – ассоциация (сходство), при наличии которой код вызывает содержимое ячейки памяти. По этому принципу, иллюстрируемому рисунком 4.6, системы назвали ассоциативными. Запоминающиймассив, как и в адресуемой памяти, состоит из n-го числа m-разрядных ячеек, хранящих необходимую информацию с зашифрованным в ней кодом признака этой информации. Устройством управления формируется код признака (иногда его называют компарандом) информации, хранящейся в i-й ячейке памяти, и заносится в регистр ассоциативных признаков (РгАП). Код может иметь число разрядов от 1 до m. Если код признаков используется полностью (без изменения), он поступает на схему сравнения, если его необходимо модифицировать, тогда ненужные разряды маскируются с помощью регистра маски (РгМ). Перед началом поиска информации в ассоциативной памяти все разряды регистраиндикаторов адреса устанавливаются в значение 1. После этого начинается опрос первого разряда содержимого всех ячеек запоминающего массива и сравнение его с первым разрядом содержимого РгАП. Если значения сравниваемых разрядов совпадают, то значение соответствующего разряда регистра индикатора адреса остается равным 1, если не совпадают, оно сбрасывается в 0. Операция сравнения повторяется со вторым, третьим и т.д. разрядами до конца, пока не будет произведено сравнение со всеми разрядами. В результате в регистре индикаторов адреса в 1 останутся те разряды, которые соответствуют ячейкам, содержащим запрашиваемые данные. Эта информация может быть считана в последовательности, определенной устройством управления.
Особенностью поиска информации по ассоциативному признаку является независимость времени поиска от числа ячеек памяти. Это время зависит только от числа разрядов кода признака и от скорости опроса разрядов запоминающего массива. В этом и заключается главное преимущество ассоциативных запоминающих устройств (ассоциативной памяти) по сравнению с адресной памятью, где необходим перебор всех адресов в процессе поиска нужной информации.
Интересен и процесс записи информации в ассоциативную память. Один из разрядов каждой ячейки запоминающего массива используется в качестве индикатора ее занятости. Например, если ячейка свободна – этот разряд имеет значение 0, если занята – 1. Следовательно, достаточно проверить один разряд во всех ячейках, чтобы определить занятые или свободные и поместить информацию в свободную ячейку.
Ассоциативная память позволяет осуществлять поиск информации по результатам выполнения определенных логических функ-ций, например, содержимое ячейки больше (меньше), больше илиравно (меньше или равно) признаку РгАП. Дополнительно, память может быть построена и с реализацией прямой адресации к данным, что удобно при работе с периферийными устройствами. Кроме этого, память позволяет легко изменять место и порядок расположения информации, благодаря чему позволяет эффективно формировать наборы данных.
Опыт эксплуатации ассоциативных систем показал эффективность решения с их помощью таких задач, как обработка радиолокационных данных, распознавание образов, обработка графических изображений и т.д. К тому же программирование задач для таких систем оказалось проще, чем для традиционных.
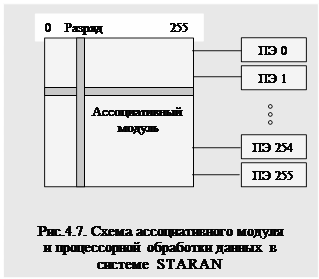
В качестве примера ассоциативной вычислительной системы часто приводят систему STARAN, разработки США. Для хранения данных в системе используется ассоциативная память с многомерным доступом, к ней можно обратиться как поразрядно, так и пословно. Каждое слово обрабатывается своим процессорным элементом (ПЭ0-ПЭ255), имеется уникальная схема для перегруппировки данных в памяти.
Ассоциативная память представляет собой квадрат на 256 слов по 256 разрядов каждое, что составляет в общей сложности 64 Кбит данных. Матрица обеспечена 256 входами и 256 выходами, позволяющими осуществлять параллельный ввод-вывод данных от (к) любых устройств. Схема ассоциативного модуля памяти и обработки представлена на рисунке 4.7.
Число ассоциативных модулей в системе может достигать 32 и обработке подвергаться до 256 Кбайт информации. Обрабатываемые слова могут быть разбиты на поля переменной длины, над
которыми могут быть выполнены арифметические и логические операции.
 Управление работой ассоциативных модулей организуется по командам программы, хранящейся в управляющей памяти. Управляющая память уникальна тем, что она состоит из шести секций:
Управление работой ассоциативных модулей организуется по командам программы, хранящейся в управляющей памяти. Управляющая память уникальна тем, что она состоит из шести секций:
— первая, емкостью 512 32-разрядных слов, является библиотекой подпрограмм;
— вторая и третья (512 слов) – память команд;
— четвертая (512 слов) – быстродействующий буфер данных;
— пятая, емкостью 16384 32-разрядных слова, считается основной памятью;
— шестая (10720 слов) – область памяти для прямого доступа – обеспечение работы периферийных устройств.
Первые четыре секции выполнены на интегральных микросхемах, имеют высокое быстродействие – время доступа около 200 нс. Память команд работает попеременно. Если, например, вторая секция выдает команды устройству управления, то третья загружается от страничного устройства и наоборот. Пятая и шестая секции выполнены на ферритовых сердечниках и имеют длительность цикла около 1 мкс.
Связь оператора с системой осуществляется с помощью мини-ЭВМ типа PDP-11. С помощью этой машины осуществляется первоначальная загрузка управляющей программы в управляющую память. Реализуется управление программами обработки прерываний по ошибкам и возможность разработки, трансляции и отладки программного обеспечения – обычная работа оператора. Машина обеспечена печатающим устройством и перфоленточным устройством ввода-вывода.
Ввод и вывод информации между системой и многочисленными периферийными устройствами обеспечивается четырьмя видами интерфейса:
— прямой доступ к памяти;
— буферизованный ввод-вывод;
— параллельный ввод-вывод;
— логическое устройство внешних функций.
Интерфейс прямого доступа к памяти может быть использован и для подключения внешней памяти. Буферизованный ввод-
вывод используется для связи системы со стандартными периферийными устройствами. При этом данные передаются в форме блоков. Параллельный ввод-вывод обеспечивается 256 линиями связи, позволяющими вести обмен данными между ассоциативными модулями и любыми устройствами системы с высокими скоростями.
4.4 Однородные системы и среды
Эти виды архитектуры вычислительных комплексов в той или иной степени уже нашли отражение в ранее рассмотренных, однако считают, что их можно выделить в самостоятельный вид, если они «вобрали в себя»» совокупность трех обязательных принципов. Первый принцип исходит из положения о том, что любую сложную задачу можно представить в виде совокупности более простых подзадач, решение которых может быть реализовано по параллельному алгоритму, который обеспечит достижение высокой производительности за счет сокращения времени ее решения.Второй постулат предполагает, что для любой сложной задачи можно подобрать соответствующую структуру из обрабатывающих элементов, связанных между собой определенным образом. Третий принцип означает, что обрабатывающая система может быть построена из одинаковых обрабатывающих элементов, связанных между собой одинаковыми связями. Такого рода системы предложили считать однородными.
Однородная система, таким образом, может быть создана на базе совокупности большого числа ЭВМ, например, на базе микро-ЭВМ. В качестве иллюстрации приводят систему, названную МИНИМАКС. Эту систему, имеющую программируемую макроструктуру, отнесли к классу однородных.
Статьи к прочтению:
- Системы с конвейерной обработкой информации 2 страница
- Системы с конвейерной обработкой информации 3 страница
Evernote другими глазами. Тема 3 -Обработка и упаковка информации. Специальная система меток
Похожие статьи:
-
Системы с конвейерной обработкой информации 2 страница
Число элементарных машин (ЭМ) не регламентировано и определяется классом решаемых задач. Структурной единицей является ЭМ, включающая вычислительный…
-
Системы с конвейерной обработкой информации 5 страница
ваемые, связные процессоры. Линейный адаптер (ЛА) подключается с одной стороны к одному из каналов ввода-вывода ЭВМ и с другой стороны к АПД,…