
Работа микропроцессора с памятью. методы адресации
Адресное пространство МП состоит из множества ячеек памяти ОЗУ, из которых он может брать информацию или засылать ее. Как говорилось выше, начиная с 4-го поколения доминирует байтовая организация памяти, и минимально адресуемой единицей является байт. Например, для ОЗУ емкостью 1024 кбайта адреса байтов таковы:
00000 00001 … FFFFF
(как принято, записываем их в шестнадцатеричнои системе; адрес последнего байта есть 1024*1024 -1=1 048 576 — 1 = FFFFF). Длина же ячейки («машинного слова») может быть как один, так и несколько байтов в зависимости от типа процессора и команды, обрабатывающей соответствующую информацию.
При обмене информацией с памятью процессор обращается к ячейкам ОЗУ по их номерам (адресам). Способы задания требуемых адресов в командах ЭВМ принято называть методами адресации. От видов и разнообразия методов адресации существенно зависит эффективность работы программы с данными, особенно если последние организованы в определенную структуру.
Для того, чтобы процессор мог извлечь данные из ячейки ОЗУ или поместить их туда, необходимо где-то задать требуемый адрес. Если адрес находится в самой команде, то мы имеем дело с прямой адресацией. Поскольку при подобном способе слишком сильно возрастает длина команды, то, чтобы избежать этого неприятного эффекта, при обращении к ОЗУ процессор использует метод косвенной адресации. Идея состоит в том, что адрес памяти предварительно заносится в один из регистров МП, а в команде содержится лишь ссылка на этот регистр. Если учесть, что при хранении адреса в регистре его еще очень удобно модифицировать (скажем, циклически увеличивая на заданную величину), становится понятным, почему косвенная адресация нашла такое широкое применение.
Приведем описание наиболее распространенных вариантов ссылок на исходную информацию (учитывая, что терминология для разных МП может различаться, названия методов адресации не приводятся):
1) данные находятся в одном из регистров МП;
2) данные входят непосредственно в составкоманды, т.е. размещаются после кода операции (операции с константой);
3) данные находятся в ячейке ОЗУ, адрес которой содержится в одном из регистров МП;
4) данные находятся в ячейке ОЗУ, адрес которой вычисляется по формуле
адрес = базовый адрес + смещение.
Базовый адрес хранится в одном из регистров МП и является начальной точкой массива данных. Смещение может быть как некоторой константой, так и содержимым другого регистра. Часто такой способ доступа к ОЗУ называют индексным, так как это похоже на нахождение элемента в одномерном массиве по его индексу.
Следует подчеркнуть, что здесь описаны лишь наиболее общие методы адресации. У конкретных моделей МП существуют некоторые особенности адресации ОЗУ. Кроме того, имеющиеся методы адресации могут быть комбинированными. Так, например, в процессорах семейства PDP возможна двойная косвенная адресация: данные хранятся в ячейке ОЗУ, адрес которой хранится в ячейке, адрес которой находится в указанном регистре (как тут не вспомнить детский стишок о синице, которая ворует пшеницу, которая в темном чулане хранится, в доме, который построилДжек?).
Методы адресации могут быть и более экзотическими. Рассмотрим, например, широко распространенный сегментный способ, принятый в процессорах фирмы «Intel». Известный американский программист Питер Нортон метко назвал эют способ словом «клудж» (от английского «kludge» — приспособление для временного устранения проблемы). Сегментный метод адресации был предложен для первого 16-разрядного МП 8086 для того. чтобы, используя 16-разрядные регистры, можно было получить 20-разрядный адрес и тем самым расширить максимально возможный объем ОЗУ с 64 кбайт до 1 Мбайта. Суть метода состоит в том, что адрес ОЗУ вычисляется как сумма двух чисел (сегмента и смещения), причем одно из них сдвинуто влево на 4 двоичных разряда, т.е. умножено на 16. Пусть, например, сегмент в шестнадцатеричном виде равен АООО, а смещение — 1000. Общепринятая запись такого адреса имеет вид АООО: 1000. Итоговый адрес равен
А000()
+ 1000
А1000
«Такой способ адресации более 64 кбайт памяти кажется довольно странным, однако он работает», — не без некоторой иронии замечает по этому поводу Питер Нортон.
Добавим, что, помимо всего прочего, при сегментной адресации один и тот же адрес ОЗУ может быть представлен несколькими комбинациями чисел (в самом деле, одну и ту же сумму можно получить разными способами)
Поскольку современные интелловские процессоры, начиная с 80386, стали 32-разрядными, их регистров хватает, чтобы адресовать до 4 Гбайт памяти Сегментный способ при этом становится излишним, хотя и сохраняется как вариант ради обеспечения программной совместимости с предыдущими моделями.
Нам осталось рассмотреть еще один очень специфический, но интересный и часто используемый на практике способ адресации данных в ОЗУ. Речь пойдет о работе со стеком. Сам термин происходит от английского слова «stack», имеющего множество значений, причем ни одно из них не подходит достаточно точно. Чаще всего в литературе упоминается магазин револьвера, который по очереди обеспечивает доступ к каждому патрону. Даже если не учитывать ненужную «милитаризацию» терминологии, такой перевод явно не подходит к современной реализации стека. Во-первых, стек не является круговым, а во-вторых, информация в стеке микрокомпьютера не смещается (для точности аналогии пришлось бы признать, что магазин покоится, а вращается револьвер!). Поэтому возьмем термин «стек» как есть, без перевода, и перейдем к определению.
Стек — это неявный способ адресации, при котором информация записывается и считывается только последовательным образом с использованием, так называемого, указателя стека.
Обратимся к примеру. Пусть требуется на время сохранить значения трех целочисленных переменных N1, N2 и N3, а затем их все сразу восстановить. Попробуем воспользоваться для этого стековой памятью. Прежде всего запомним, что стек всегда имеет единственный вход и выход информации — для .хранения его адреса и нужен указатель стека. Пусть для определенности он сейчас содержит адрес 2006 (рис. 4.13, а). Тогда по команде «записать в стек N1» (обратите внимание, что в команде не фигурирует явно ни адрес ОЗУ, ни регистр МП!) процессор проделает следующее:
1) уменьшит указатель стека на 2 (целое число занимает в памяти 2 байта);
2) запишет N1 по полученному адресу 2004 (рис.4.13, б).
Аналогично при выполнении команд «записать в стек N2» и «записать в стек N3» значения этих переменных попадут в ячейки 2002 и 2000, причем указатель стека станет равным 2000 (рис. 4.13, в).
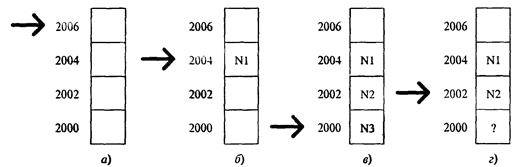
Рис. 4.13. Пример для изучения принципа работы стека
Теперь займемся извлечением информации. Как видно из рис. 4.13, в, указатель сейчас «направлен» на значение переменной N3, а значит считывать придется, начиная с него. Выполним команду «прочитать из стека N3». При этом процессор
1) считает в N3 значение из стека;
2) увеличит указатель на 2 (рис. 4.13, г).
Аналогично прочитаем N2 и N1, после чего стек опустеет и вернется к начальному состоянию, изображенному на рис. 4.13, а.
Примечание. Обратим внимание на то, что значение в стеке после считывания, конечно же, не исчезает, как это условно показано на рис. 4.13, г, но есть причины полагать, что мы его там можем больше не увидеть. Дело в том, что процессор имеет право иногда временно использовать стек для своих «внутренних» нужд. При этом некоторые ячейки, адреса которых меньше текущего указателя стека, естественно, изменятся. Следовательно, во избежание неприятностей лучше всегда считать, что после считывания информации в стековой памяти она пропадает.
Подводя итоги рассмотрения примера, обратим внимание на следующее. Та информация, которая заносится в стек первой, извлекается последней и наоборот. Обычно об организации стека говорят: «первым пришел — последним ушел». Удобно представить себе аналогию с детской пирамидкой, нижнее кольцо которой невозможно снять до тех пор, пока не будут сняты все остальные.
Еще раз подчеркнем, что в командах работы со стеком адрес ОЗУ не фигурирует в явном виде. Но при этом молчаливо предполагается, что указатель стека уже задан. Как правило, инициализацию указателя стека компьютер делает сам, но не мешает поинтересоваться, так ли это в вашем конкретном случае и достаточно ли памяти под стек имеется при этом. Если указатель стека определен неправильно, то запись в стек может разрушить полезную информацию в ОЗУ и вызвать непредсказуемые последствия.
Интересно, что со стековым способом организации мы имеем дело в жизни гораздо чаще, чем это может показаться на первый взгляд. Во-первых, дисциплине «первым пришел — последним ушел» подчиняются скобки в арифметических выражениях: первой всегда закрывается «самая внутренняя», т.е. как раз последняя скобка. Если вы знакомы с программированием на любом алгоритмическом языке, то без труда найдете и еще два примера: вложенные циклы и подпрограммы.
Итак, мы подробно рассмотрели общие принципы записи информации в стек. Остается сказать, что стековый способ организации ОЗУ используется в вычислительной технике очень широко. На аппаратном уровне процессор «обучен» сохранять в стеке текущий адрес программы при выполнении команды перехода с возвратом, т.е. при вызове подпрограммы. Часто программа предварительно заносит в тот же самый стек необходимые для подпрограммы параметры: так реализуется, например, вызов процедур и функций с параметрами в языке «Паскаль». Кроме того. стек часто используется для временного сохранения значений тех или иных внутренних регистров процессора. Наконец, процессор активно использует стек при реализации прерываний от внешних устройств (об этом будет рассказано в следующем параграфе).
ФОРМАТЫ ДАННЫХ
Почти каждая команда процессора нацелена на обработку данных, местонахождение которых определяется значениями адресов операндов. Для понимания работы процессора существенно представлять, какого рода данные он может обрабатывать.
Если в ходе исполнения программы ее остановить, прочитать содержимое какой-нибудь ячейки памяти ОЗУ, к которой в это мгновение обращается процессор, и попытаться понять, что именно хранится в этой ячейке, то это чаще всего невозможно сделать, не расшифровав код выполняемой операции — сам по себе хранимый в ячейке двоичный код может быть и числом, и командой, и кодом символа, и чем-то еще. Все дело в том, как его интерпретирует работающая с ним команда.
Перечислим некоторые форматы данных, типичные для 16- разрядной ЭВМ.
8- битовые целые числа без знака. Каждое такое число занимает 1 байт и воспринимается процессором как целое положительное число. Следовательно, диапазон представимости чисел в этом формате от 00000000 до 11111111, т.е. от 0 до FF в шестнадцатеричной системе (от 0 до 255 в десятичной).
8- битовые целые числа со знаком. В этом случае величина числа задается семью битами, а значение старшего бита определяет знак числа (0 — положительное, 1 -отрицательное). Например, в этом формате код 01101011 означает число +6В.
Однако код 11101011 не означает, как можно подумать, число -6В, так как для кодирования отрицательных чисел применяется, так называемый, дополнительный код. Он образуется следующим образом:
• находится восьмиразрядное двоичное представление абсолютной величины числа;
• найденный код инвертируется, т.е. в нем нули заменяются на единицы и наоборот;
• к полученному коду арифметически прибавляется единица.
Например, процесс получения дополнительного кода десятичного числа -75 таков:
01001011 10110100 10110101
/
Использование дополнительного кода облегчает организацию арифметических действий в процессоре (который, как правило, не имеет даже аппаратно реализованной операции вычитания — все удается свести к сложению целых чисел).
Обратная процедура — восстановление значения числа подополнительному коду -осуществляется по тому же правилу, что и прямая.
Диапазон представимости чисел в этом формате: от-128 до +127.
16- битовые целые числа со знаком и без знака. Они в точности аналогичны 8-битовым, но код имеет вдвое большую длину. Соответственно, многократно возрастает диапазон представимости: для чисел без знака от 0000 до FFFF (т.е. от О до 65535 в десятичной системе), для чисел со знаком — от -8000 до +7FFF (т.е. в десятичной системе от -32768 до +32767).
8- битовые символы. В этом формате двоичный код интерпретируется обрабатывающей его командой как код символа. При работе с персональными ЭВМ обычно используется система кодирования ASCII, о которой говорилось в главе 1. В этой системе стандартизированы (закреплены за определенными символами) коды, у которых значение старшего бита равно 0; все прочие коды остаются за символами национальных алфавитов и дополнительными специальными символами.
Битовые поля. В этом формате значащим является не весь 8- или 16- разрядный код в целом, а каждый из составляющих его битов. Один из примеров битового поля — содержимое регистра состояния процессора (см. выше). Другой пример -форма хранения множеств в языке «Паскаль».
Существуют и другие форматы данных — двоично-десятичные числа, строки и т.д.
ОБРАБОТКА ПРЕРЫВАНИЙ
Важную роль в работе современного МП играют прерывания. Они всегда нарушают естественный ход выполнения программы для осуществления неотложных действий, связанных, например, с реакцией на щелчок мыши или сбой в цепи электропитания.
События, вызывающие прерывания, можно разделить на две группы: фатальные и нефатальные. На фатальные (неотвратимо наступающие) процессор может реагировать единственным способом: прекратить исполнение программы, проанализировать событие и принять соответствующие меры (чаще всего — сообщить причину прерывания пользователю и ждать его реакции). Однако часто можно с остановкой программы повременить: запомнить, что прерывание было, и продолжать исполнять программу. Например, сложение с переполнением разрядной сетки -фатальное событие, после которого остановка неизбежна; попытка вывода на принтер, не готовый к приему информации, может быть отложена (с сохранением этой информации).
Основные виды прерываний — внутрипроцессорные прерывания и прерывания от внешних устройств. Первые связаны с возникновением непреодолимого препятствия при выполнении программы. Причин может быть много: из памяти выбрана команда с несуществующим кодом или адресом, в ходе исполнения команды возникло переполнение разрядной сетки ЭВМ или произошла попытка записи в оперативную память, отведенную другой задаче. В большинстве подобных случаев дальнейшее выполнение программы становится невозможным и управление передается системе, обеспечивающей прохождение задач (чаще всего это — операционная система), которая и принимает меры по обработке внешней нештатной ситуации.
Гораздо реже, но возможны, нефатальные внутрипроцессорные прерывания, например, специальные отладочные прерывания. Такие прерывания обеспечивают возможность пошагового исполнения тестируемой программы под контролем специальных программных средств.
Прерывания второй группы возникают по требованиям какого-либо из многочисленных внешних устройств. Такое событие обычно не приводит к фатальному завершению задачи,напротив, это вполне нормальная ситуация. Поэтому при таком прерывании МП принимает меры для того, чтобы обеспечить дальнейшее выполнение программы: запоминает в стеке текущее значение счетчика команд и содержимое регистра состояния. Затем происходит переход на подпрограмму обработки данного прерывания. После ее выполнения процессор восстанавливаетизстека значения своих регистров и продолжает выполнение прерванной программы.
Прерывания от внешних устройств подробно рассматриваются в следующем пункте.
Отметим, что термин «прерывание» часто используется еще в одном значении. Речь идет о, так называемых, программных прерываниях. Например, для IBM-совместимых компьютеров существуют многочисленные команды прерывания 1NT с самыми разнообразными номерами. Следует понимать, что 1NT — это одна из инструкций процессора; чтобы она заработала, ее код должен содержаться в программе. В противоположность этому, «настоящие» прерывания возникают аппаратно и не требуют наличия каких-то специальных команд в тексте прерываемой программы. Более того, аппаратное прерывание может произойти между двумя любыми командами программы.
К программным относятся и межмашинные прерывания, возникающие в локальной сети при обмене информацией между компьютерами.
Запрет нефатального прерывания называется маскировкой; маскировка задается программистом или системной программой. Делается это либо с помощью установления вида битового поля в специальном регистре маски прерываний, в котором значения разрядов (0 или 1) связаны соответственно с отсутствием или наличием маскировки закрепленного за этим разрядом прерывания, либо с аналогичным использованием разрядов регистра состояния процессора.
После получения сигнала о незамаскированном прерывании процессор делает следующее:
• запоминает состояние прерванной программы;
• распознает источник прерывания;
• вызывает и выполняет специальную системную программу обработки прерываний;
• восстанавливает состояние прерванной программыи, при возможности, продолжает ее исполнение.
Для распознавания источника прерывания анализируются некоторые биты регистра состояния процессора, состояние внешних устройств и т.д. Для запоминания состояния прерванной программы чаще всего используется стек. Выше мы уже говорили о стеке в ракурсе организации особого способа адресации. Кроме того, стек используется процессором как для организации механизма прерываний, так и для обработки обращения к подпрограммам, передачи параметров и временного хранения данных.
Назначение программы обработки — понять и в удобной для пользователя форме вывести (обычно на экран) сообщение о причине прерывания и (иногда) дать рекомендации по возможной реакции на эту причину.
Все это разительно отличается от ситуации с машинами 1-го и 2-го (а отчасти и 3-го) поколений, когда пользователь без помощи системного программиста в большинстве случаев не мог разобраться в причине события, вызвавшего прерывание его программы на этапе исполнения. Такая ситуация стала нетерпимой для пользователей персональных компьютеров, и чем совершеннее анализатор программы обработки прерываний, тем выше уровень «дружелюбности» пользовательского интерфейса.
Статьи к прочтению:
- Работа микропроцессора с внешними устройствами
- Работа первичного управляющего автомата в режиме прерывания
Лекция 6: Адресация
Похожие статьи:
-
Способы адресации микропроцессора к580.
ЦЕЛЬ РАБОТЫ – изучить способы адресации. Метод задания операнда в команде называется способом адресации. В микропроцессоре К580ИК80А используется пять…
-
Работа микропроцессора с внешними устройствами
Выше было описано, как процессор обменивается информацией с ее наиболее важным и оперативным источником — памятью. Рассмотрим теперь, как МП может…